一种基于大型语言模型的酶活参数抽取方法与系统与流程
本发明涉及文本信息处理和数据挖掘领域,特别涉及一种基于大型语言模型的酶活参数抽取方法与系统。
背景技术:
1、在生物医学研究中,酶活参数是研究酶催化反应的重要指标之一。随着文献数据量的指数级增长,如何快速、高效、准确地从海量生物医学文献中提取酶活参数成为一大挑战。传统的人工抽取方法存在工作量大、效率低下、易出错的问题,且无法适应文献不断增长的需求。
2、现有的自动化信息提取技术大多依赖于规则匹配或基于关键词的方法,这些方法在应对复杂文献内容时表现不佳。近年来,随着大型语言模型的快速发展,自然语言处理(natural language processing,nlp)技术已经取得显著进展,尤其是在理解复杂语言模式和处理大量非结构化数据方面具有优势。因此,提出一种基于大型语言模型的酶活参数抽取方法与系统,能够有效提高酶活参数提取的准确性和效率。
技术实现思路
1、本发明旨在解决现有酶活参数提取过程中的效率低、准确性不足的问题。通过结合大型语言模型的自然语言处理能力、提示词工程的优化技术以及人工抽取的标准操作,提供一种基于大型语言模型的酶活参数抽取方法与系统。本发明可显著减少人工的工作量,提升从生物医学文献中提取酶活参数的精度和可靠性。
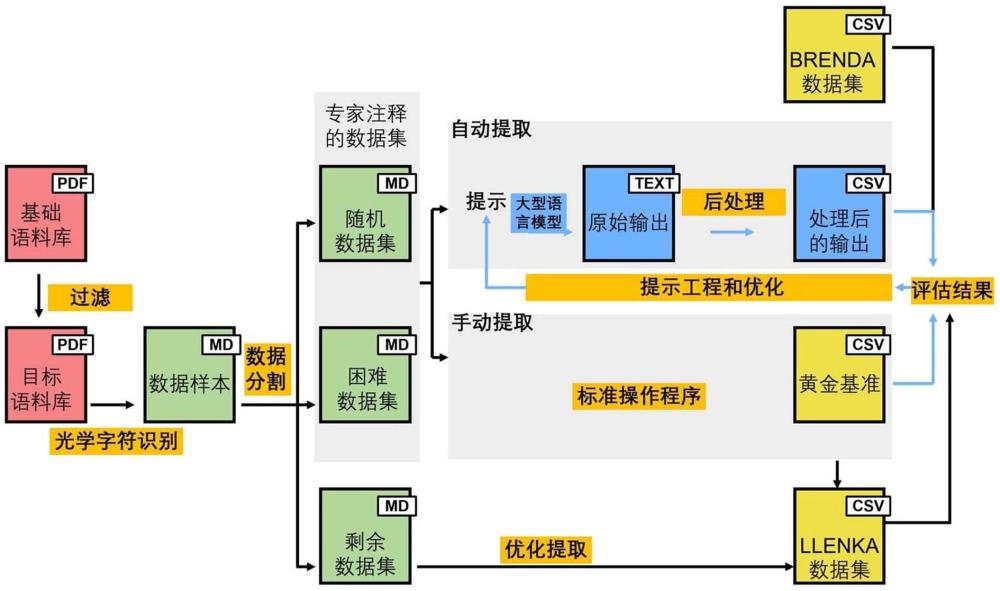
2、为实现上述目的,本发明提供了一种基于大型语言模型的酶活参数抽取方法,包括以下步骤:
3、(1)从生物医学文献库中筛选出与酶活相关的文献;
4、(2)对筛选后的文献进行光学字符识别,生成文本数据;
5、(3)将所述文本数据拆分为包含不同特征的样本数据,生成困难样本和随机样本;
6、(4)对所述困难样本进行人工酶活参数抽取,生成黄金基准数据;
7、(5)使用基于提示词驱动的大型语言模型,通过提示词优化对所述随机样本进行自动化酶活参数抽取,并对自动抽取结果进行后处理,生成结构化的酶活参数数据;
8、(6)结合所述步骤(4)中的人工抽取结果与步骤(5)中的自动抽取结果,利用黄金基准数据对自动抽取得到的酶活参数数据进行校正和优化,得到最终的酶活参数数据。
9、进一步地,所述步骤(3)中,所述困难样本为含有最多酶功能参数数据的文献;所述随机样本为从文献池中随机选取的文献。
10、进一步地,所述步骤(5)中,提示词为:"请提取表格中的酶名、来源生物、动力学常数、ph和温度”;"请识别并提取文献中的酶突变体信息及其对酶活性影响的实验数据”;在提示词优化过程中,使用随机样本和困难样本对提示词进行评估,针对召回率低于50%的样本手动分析并优化提示词,在每次优化中,逐步增加文本梯度,以解决特定问题。
11、进一步地,所述召回率由正确提取的数据量/黄金基准数据中的总数据量得到。
12、进一步地,所述步骤(5)中,后处理操作包括:清理无效字段及空值、数字格式标准化以及单位统一。
13、为实现上述目的,本发明还提供了一种基于大型语言模型的酶活参数抽取系统,包括:
14、文献过滤模块,用于从生物医学文献中筛选与酶活相关的文献;
15、光学字符识别模块,用于对筛选后的文献进行光学字符识别,生成文本数据;
16、数据拆分模块,用于将文本数据拆分为包含不同特征的样本数据,生成困难样本和随机样本;
17、人工抽取模块,用于从困难样本中人工提取酶活参数,生成黄金基准数据;
18、自动抽取模块,用于基于大型语言模型对随机样本进行自动化抽取酶活参数;
19、优化提取模块,用于整合人工抽取模块与自动抽取模块的输出,构建优化的酶活参数抽取框架;
20、数据库模块,用于存储提取出的酶活参数数据。
21、进一步地,所述文献过滤模块基于关键词匹配或基于领域知识的文献筛选算法进行筛选。
22、进一步地,所述自动抽取模块包括:
23、提示词工程单元,用于设计和优化提示词以驱动大型语言模型提取酶活参数;
24、原始输出单元,用于通过大型语言模型生成初始提取结果;
25、后处理单元,用于对初始提取结果进一步处理和格式化,生成结构化的酶活参数数据。
26、为实现上述目的,本发明还提供了一种电子设备,包括存储器和处理器,所述存储器与所述处理器耦接;其中,所述存储器用于存储程序数据,所述处理器用于执行所述程序数据以实现上述的基于大型语言模型的酶活参数抽取方法。
27、为实现上述目的,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现上述的基于大型语言模型的酶活参数抽取方法。
28、与现有技术相比,本发明的有益效果是:本发明提出了一种结合人工抽取与基于大型语言模型的自动抽取方法与系统,实现了从复杂的生物医学文献中高效提取酶活参数的功能。该系统通过提示词优化与后处理技术,显著提升了文献解析与数据抽取的精度,能够为生命科学领域的研究人员提供高效的数据支持。通过性能评估与反馈机制,系统能够不断优化提示词设计与模型参数,确保持续的提取效果改进。本发明能够快速、批量处理大量生物医学文献,大幅减少了手动工作量,提高了数据收集的效率和准确性,尤其适用于酶学研究领域的数据库构建和信息整理;还适用于生命科学领域中的文献管理、数据挖掘以及知识提取等应用。
技术特征:
1.一种基于大型语言模型的酶活参数抽取方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于大型语言模型的酶活参数抽取方法,其特征在于,所述步骤(3)中,所述困难样本为含有最多酶功能参数数据的文献;所述随机样本为从文献池中随机选取的文献。
3.根据权利要求2所述的基于大型语言模型的酶活参数抽取方法,其特征在于,所述步骤(5)中,提示词为:"请提取表格中的酶名、来源生物、动力学常数、ph和温度”;"请识别并提取文献中的酶突变体信息及其对酶活性影响的实验数据”;在提示词优化过程中,使用随机样本和困难样本对提示词进行评估,针对召回率低于50%的样本手动分析并优化提示词,在每次优化中,逐步增加文本梯度,以解决特定问题。
4.根据权利要求3所述的基于大型语言模型的酶活参数抽取方法,其特征在于,所述召回率由正确提取的数据量/黄金基准数据中的总数据量得到。
5.根据权利要求3所述的基于大型语言模型的酶活参数抽取方法,其特征在于,所述步骤(5)中,后处理操作包括:清理无效字段及空值、数字格式标准化以及单位统一。
6.一种基于大型语言模型的酶活参数抽取系统,其特征在于,包括:
7.根据权利要求6所述的基于大型语言模型的酶活参数抽取系统,其特征在于,所述文献过滤模块基于关键词匹配或基于领域知识的文献筛选算法进行筛选。
8.根据权利要求6所述的基于大型语言模型的酶活参数抽取系统,其特征在于,所述自动抽取模块包括:
9.一种电子设备,包括存储器和处理器,其特征在于,所述存储器与所述处理器耦接;其中,所述存储器用于存储程序数据,所述处理器用于执行所述程序数据以实现上述权利要求1-5任一项所述的基于大型语言模型的酶活参数抽取方法。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时实现如权利要求1-5任一项所述的基于大型语言模型的酶活参数抽取方法。
技术总结
本发明提出了一种基于大型语言模型的酶活参数抽取方法与系统,属于文本信息处理和数据挖掘领域。本发明通过OCR技术将PDF格式文献转换为Markdown格式,随后利用大型语言模型结合优化的提示词自动提取关键数据;自动提取流程经过严格的提示词优化和后处理操作,确保数据的准确性和一致性;然后通过精确度和召回率验证自动提取的有效性,最终生成的酶数据库可供后续的研究和分析使用。本发明通过结合OCR技术与大型语言模型,突破了现有手动数据提取的局限,显著提升了文献解析和数据提取的自动化程度;通过提示词工程和优化的提示词设计,实现了复杂文献中的结构化数据自动提取,特别是对于酶动力学参数的精确识别和提取。
技术研发人员:郭蒙浩,谢斯蔚,胡捷,江金陵,裘捷中,孙泽懿,姜先月,岳振雷,石军超,傅帅,张小玉,陈广勇
受保护的技术使用者:之江实验室
技术研发日:
技术公布日:2025/2/17
- 还没有人留言评论。精彩留言会获得点赞!