智能体表情模仿的映射优化方法、装置、设备及介质与流程
本发明涉及人工智能,具体涉及图像数据处理,更具体地涉及一种智能体表情模仿的映射优化方法、装置、设备、介质及产品。
背景技术:
1、人工智能(artificial intelligence,简称ai)是新一轮科技革命和产业变革的重要驱动力量,是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的关键性技术科学。作为智能科学重要的组成部分,人工智能企图了解智能的实质,并生产出一种新的能以与人类智能相似的方式做出反应的智能机器(如高仿生表情机器人)。
2、作为人工智能技术中的重要组成部分,人类表情的识别复现(如表情模仿)技术在人机交互、安全识别、机器人制造、自动化、医疗、通信以及驾驶等领域得到了广泛的关注,迅速成为业界的研究热点。表情模仿技术主要分为表情感知、映射迁移和驱动执行三个阶段,旨在表情感知阶段通过精确捕捉人类面部的表情动态特征,在映射迁移阶段实现向高仿生表情机器人等具身智能的人脸映射,最后在驱动执行阶段控制表情执行器实现精确的表情复现驱动。但是现有技术中传统的表情模仿技术,在映射迁移阶段存在易于产生严重语义失真且无法直接用于驱动实际物理执行器等问题。
技术实现思路
1、鉴于上述问题至少之一,本发明的实施例旨在能够的智能体表情模仿的映射优化方法、装置、设备、介质及产品,从而提供了一种智能体表情模仿的映射阶段的优化方案,通过混合形状基底来精确刻画表情语义,引入一个统一的表情参数空间,建立了从标准化人脸表情到机器人表情空间的跨模态映射机制,从而解决了人脸与机器人面部在几何结构上的差异,确保了表情语义在迁移过程中的一致性。
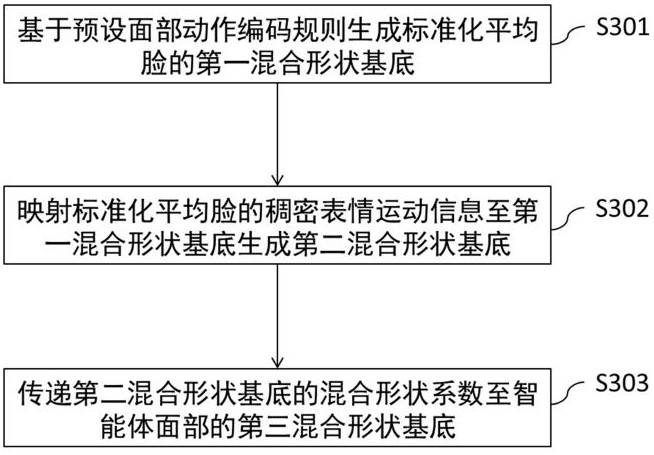
2、本发明的实施例的一个方面提供了一种智能体表情模仿的映射优化方法,其中,包括:基于预设面部动作编码规则生成标准化平均脸的第一混合形状基底;映射标准化平均脸的稠密表情运动信息至第一混合形状基底生成第二混合形状基底;以及传递第二混合形状基底的混合形状系数至智能体面部的第三混合形状基底,完成智能体表情模仿的映射优化。
3、根据本发明的一实施例,在基于预设面部动作编码规则生成标准化平均脸的第一混合形状基底中,包括:根据预设面部动作编码规则生成混合形状表情基底矩阵;基于预设混合形状权重向量和混合形状表情基底矩阵生成标准化平均脸的第一混合形状基底。
4、根据本发明的一实施例,在映射标准化平均脸的稠密表情运动信息至第一混合形状基底生成第二混合形状基底之前,还包括:根据提取的目标表情图像的表情运动信息生成标准化平均脸的稠密表情运动信息。
5、根据本发明的一实施例,在映射标准化平均脸的稠密表情运动信息至第一混合形状基底生成第二混合形状基底中,包括:提取稠密表情运动信息对应的稠密表情网格上的第一稠密标注点和平均脸网格上的第二稠密标注点;根据混合形状表情基底矩阵获取稠密标注基底矩阵;根据稠密标注基底矩阵、第一稠密标注点和第二稠密标注点生成混合形状权重优化任务。
6、根据本发明的一实施例,在映射标准化平均脸的稠密表情运动信息至第一混合形状基底生成第二混合形状基底中,还包括:通过最小化预设误差向量和预设系数约束条件获取混合形状权重优化任务对应的混合形状系数,以实现映射标准化平均脸的稠密表情运动信息至第一混合形状基底生成第二混合形状基底。
7、根据本发明的一实施例,在传递第二混合形状基底的混合形状系数至智能体面部的第三混合形状基底,完成之前,还包括:基于预设面部动作编码规则生成智能体面部的第三混合形状基底,其中,第三混合形状基底与第一混合形状基底的混合形状语义相同。
8、根据本发明的一实施例,在传递第二混合形状基底的混合形状系数至智能体面部的第三混合形状基底,完成中,包括:将混合形状系数应用于第三混合形状基底,生成智能体对应的智能体表情网格。
9、本发明的实施例的另一个方面提供了一种智能体表情模仿的映射优化装置,其中,包括基底生成模块、信息映射模块和系数传递模块。基底生成模块用于基于预设面部动作编码规则生成标准化平均脸的第一混合形状基底;信息映射模块用于映射标准化平均脸的稠密表情运动信息至第一混合形状基底生成第二混合形状基底;以及系数传递模块用于传递第二混合形状基底的混合形状系数至智能体面部的第三混合形状基底,完成智能体表情模仿的映射优化。
10、本发明的实施例的另一个方面提供了一种电子设备,包括一个或多个处理器和存储器,存储器用于存储一个或多个程序,其中,当该一个或多个程序被该一个或多个处理器执行时,使得该一个或多个处理器执行上述智能体表情模仿的映射优化方法。
11、本发明的实施例的另一个方面提供了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行上述智能体表情模仿的映射优化方法。
12、本发明的实施例的另一个方面提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述智能体表情模仿的映射优化方法。
13、本发明实施例提供的智能体表情模仿的映射优化方法可以至少部分地解决相关技术中的问题,并因此可以至少实现如下技术效果之一:
14、因此,在映射阶段,本发明实施例的上述智能体表情模仿的映射优化方法,通过一套基于标准化平均脸的第二混合形状基底的混合形状语义空间作为中间桥梁,解决了人脸与智能体面部在拓扑结构和几何特性上的差异问题。具体地,首先在标准化平均脸上定义一套第一混合形状基底,用于表情语义的稠密表征。该第一混合形状基底则可以通过稠密语义关键点,将感知阶段(参照上述实施例1)生成的稠密表情运动映射到混合形状系数空间,形成第二混合形状基底。在此过程中,通过传递混合形状系数,将表情运动从标准化平均脸的拓扑结构上映射至智能体面部的拓扑结构上,实现了跨拓扑结构的语义一致性表情迁移。
15、因此,这种通过从几何域到语义域的转换,解决了传统方案中因人脸与机器人面部拓扑差异导致的语义失真问题。此外,混合形状系数数量有限,便于实时传输,从而大幅提升了映射阶段的效率和鲁棒性。同时生成的混合形状系数直接对应机器人表皮(如图5c所示皮肤skin)的运动状态,确保了生成表情的物理可执行性。可见,在表情模仿的跨实体映射过程中,基于上述预设面部动作编码规则设计的混合形状基底可以被用于精确刻画表情语义。通过引入一个统一表情参数空间,可建立从标准化平均脸的稠密人脸表情到机器人表情空间的跨模态映射机制,因而解决了人脸和机器人面部在几何结构上的差异,确保了表情语义在迁移过程中的一致性。
16、应了解的是,上述一般描述及以下具体实施方式仅为示例性及阐释性的,其并不能限制本发明所欲主张的范围。
技术特征:
1.一种智能体表情模仿的映射优化方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,在所述基于预设面部动作编码规则生成标准化平均脸的第一混合形状基底中,包括:
3.根据权利要求1所述的方法,其特征在于,在所述映射所述标准化平均脸的稠密表情运动信息至所述第一混合形状基底生成第二混合形状基底之前,还包括:
4.根据权利要求1所述的方法,其特征在于,在所述映射所述标准化平均脸的稠密表情运动信息至所述第一混合形状基底生成第二混合形状基底中,包括:
5.根据权利要求4所述的方法,其特征在于,在所述映射所述标准化平均脸的稠密表情运动信息至所述第一混合形状基底生成第二混合形状基底中,还包括:
6.根据权利要求1所述的方法,其特征在于,在所述传递所述第二混合形状基底的混合形状系数至智能体面部的第三混合形状基底,完成所述映射优化之前,还包括:
7.根据权利要求1所述的方法,其特征在于,在所述传递所述第二混合形状基底的混合形状系数至智能体面部的第三混合形状基底,完成所述映射优化中,包括:
8.一种智能体表情模仿的映射优化装置,其特征在于,包括:
9.一种电子设备,包括:
10.一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行权利要求1~7中任一项所述的方法。
11.一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现权利要求1~7中任一项所述的方法。
技术总结
本发明实施例提供了一种智能体表情模仿的映射优化方法,可以应用于人工智能技术领域。该智能体表情模仿的映射优化方法包括:基于预设面部动作编码规则生成标准化平均脸的第一混合形状基底;映射智能体表情模仿的映射优化标准化平均脸的稠密表情运动信息至智能体表情模仿的映射优化第一混合形状基底生成第二混合形状基底;以及传递智能体表情模仿的映射优化第二混合形状基底的混合形状系数至智能体面部的第三混合形状基底,完成智能体表情模仿的映射优化。本发明实施例还提供了一种智能体表情模仿的映射优化装置、设备、存储介质和程序产品。
技术研发人员:李博韧,李杭
受保护的技术使用者:北京通用人工智能研究院
技术研发日:
技术公布日:2025/4/14
- 还没有人留言评论。精彩留言会获得点赞!