一种可重构电池拓扑结构及深度强化学习控制方法
本发明涉及电池储能,更具体的说是涉及一种可重构电池拓扑结构及深度强化学习控制方法。
背景技术:
1、电池储能系统具有快速功率响应、密集能量存储、灵活部署等优势,是目前储能行业中发展最快、应用最广和较为成熟的储能技术之一。并且系统为响应复杂的用户需求、获取更高的电压与容量,通常将大量单体电池采用固定串并联方式集成为电池组。然而,由于电池生产商家制作工艺参差不齐,单体电池电压、容量及内部参数无法做到完全统一,在运行中易引发电池性能失衡而造成系统的“短板效应”,使得系统的整体性能、安全性和寿命大幅降低。因此,研究人员针对如何避免系统“短板效应”以延长电池寿命、提高电池性能和储能系统的可靠性提出了多种解决思路,一种是设计能量转移电池均衡方法,主要分为被动均衡和主动均衡两大类。其中主动均衡是常见的均衡方式,通过电容、电感、变压器、电力电子变换器等设备构造额外的能量传输通道,实现电池能量在不同电池之间的转移,但是该方法会产生能量的浪费和系统成本增加。另一种是设计可重构电池网络的均衡方法,该方法被公认为克服这些缺陷最有前景的解决方案。在开关和电池组成的可重构电池拓扑中,根据电池状态和环境等因素动态调整电池的连接方式实现电池均衡。
2、为了克服电池间的差异,采用可重构电池组的方法实现电池性能一致以提升系统性能是当前储能行业的一个研究热点。可重构电池组是指每个单体电池与一组高速电力电子开关连接,形成一个动态可重构电池网络,在网络中,电池单元的拓扑结构将根据每个电池的状态和负载情况进行重新配置。然而,电池组的动态可重构存在路径组合优化问题。
技术实现思路
1、有鉴于此,本发明提供了一种可重构电池拓扑结构及深度强化学习控制方法。
2、为了实现上述目的,本发明采用如下技术方案:
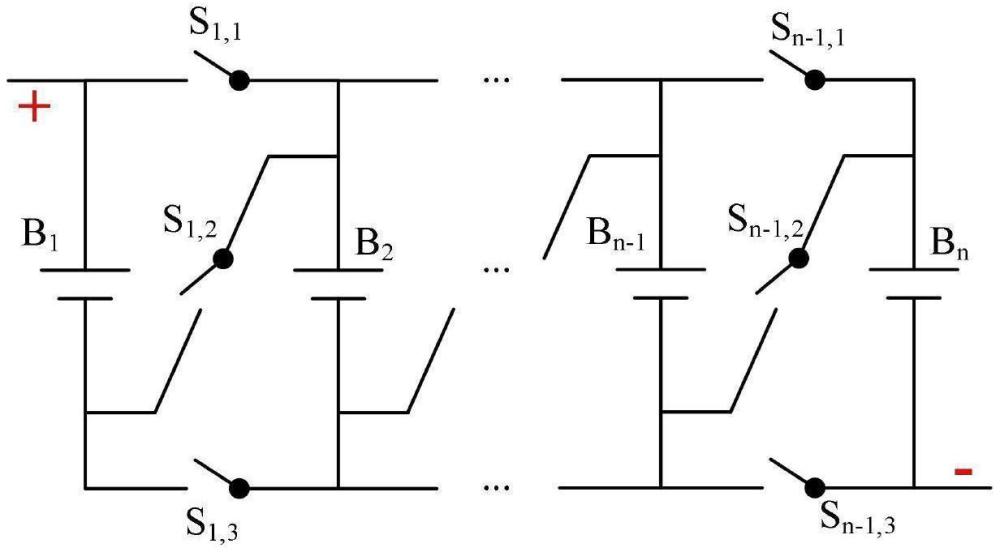
3、一种可重构电池拓扑结构,包括n颗电池和开关阵列,用于实现电池隔离、串联和并联;
4、当电池bi串联接入时,第一开关si,1和第三si,3断开,第二开关si,2闭合;当电池bi并联接入时,第二开关si,2断开,第一开关si,1和第三si,3闭合;当电池bi隔离时,开关第一si,1和第三si,3断开,开关第二si,2闭合,且前一颗电池的第一前项开关si-1,1和第二前项si-1,2断开,第三前项开关si-1,3闭合。
5、一种可重构电池拓扑深度强化学习控制方法,包括以下步骤:
6、获取所述拓扑结构中每一单体电池的soc值,确定电池组中的soc差异;
7、在基于深度强化学习dqn算法改进的dueling dqn网络结构中,将每个电池的soc作为网络的输入,输出每个动作的q-值。
8、可选的,所述dueling dqn网络结构中将分离的状态价值和优势价值两个分支按照以下公式结合在一起,用于估计q-值:
9、q(s,a;θ,η,β)=v(s,θ,β)+a(s,a;θ,η);
10、其中,v表示状态价值;a表示优势价值;s表示状态;a表示动作;θ为第一隐藏层参数;η和β分别为价值层和优势层参数。
11、可选的,还包括对q-值进行中心化处理,将优势价值a表示为某个动作的优势价值减去该状态下所有优势价值的平均值,更新之后的计算方式如下所示,其中|a|是行为维度;
12、
13、其中,v表示状态价值;a表示优势价值;s表示状态;a表示动作;θ为第一隐藏层参数;η和β分别为价值层和优势层参数。
14、可选的,dueling dqn网络结构训练过程包含初始化经验池、agent和环境三个变量。
15、可选的,agent定义三个空间变量,包括状态空间,行为空间和优化目标。
16、可选的,状态空间为电池组内所有电池展现出的所有soc组合的集合,则t时刻的状态定义为公式如下:
17、
18、表示为第i颗电池t时刻的soc值。
19、可选的,行为空间为单个电池的行为就是电池的连接状态,即0和1,按照预设映射为开关的状态,则行为空间就是每个电池不同连接状态的所有组合数,在t时刻的行为at是由开关状态组成的0-1矩阵。
20、可选的,优化目标即确定均衡效果,在t时刻的奖励rt定义,其中socmean是电池组的平均soc;根据奖励的定义如下,rt越接近0,表示电池间的soc差异越小,均衡效果越好:
21、
22、经由上述的技术方案可知,与现有技术相比,本发明提供了一种可重构电池拓扑结构及深度强化学习控制方法,利用其无模型特性,显著降低构建经验或专家模型的复杂性,提出dueling dqn方法实现可重构电池组的soc均衡,该算法分别计算状态价值和动作优势,更准确地估计每个状态的价值,减轻dqn对q-值的过度估计问题,以提高算法的稳定性和加快模型收敛速度。
技术特征:
1.一种可重构电池拓扑结构,其特征在于,包括n颗电池和开关阵列,用于实现电池隔离、串联和并联;
2.一种可重构电池拓扑深度强化学习控制方法,其特征在于,包括以下步骤:
3.根据权利要求2所述的一种可重构电池拓扑深度强化学习控制方法,其特征在于,所述dueling dqn网络结构中将分离的状态价值和优势价值两个分支按照以下公式结合在一起,用于估计q-值:
4.根据权利要求2所述的一种可重构电池拓扑深度强化学习控制方法,其特征在于,还包括对q-值进行中心化处理,将优势价值a表示为某个动作的优势价值减去该状态下所有优势价值的平均值,更新之后的计算方式如下所示,其中|a|是行为维度;
5.根据权利要求2所述的一种可重构电池拓扑深度强化学习控制方法,其特征在于,dueling dqn网络结构训练过程包含初始化经验池、agent和环境三个变量。
6.根据权利要求5所述的一种可重构电池拓扑深度强化学习控制方法,其特征在于,agent定义三个空间变量,包括状态空间,行为空间和优化目标。
7.根据权利要求6所述的一种可重构电池拓扑深度强化学习控制方法,其特征在于,状态空间为电池组内所有电池展现出的所有soc组合的集合,则t时刻的状态定义为公式如下:
8.根据权利要求6所述的一种可重构电池拓扑深度强化学习控制方法,其特征在于,行为空间为单个电池的行为就是电池的连接状态,即0和1,按照预设映射为开关的状态,则行为空间就是每个电池不同连接状态的所有组合数,在t时刻的行为at是由开关状态组成的0-1矩阵。
9.根据权利要求6所述的一种可重构电池拓扑深度强化学习控制方法,其特征在于,优化目标即确定均衡效果,在t时刻的奖励rt定义,其中socmean是电池组的平均soc;根据奖励的定义如下,rt越接近0,表示电池间的soc差异越小,均衡效果越好:
技术总结
本发明公开了一种可重构电池拓扑结构及深度强化学习控制方法,涉及电池储能技术领域。包括n颗电池和开关阵列,用于实现电池隔离、串联和并联;当电池B<subgt;i</subgt;串联接入时,第一开关S<subgt;i,1</subgt;和第三S<subgt;i,3</subgt;断开,第二开关S<subgt;i,2</subgt;闭合;当电池B<subgt;i</subgt;并联接入时,第二开关S<subgt;i,2</subgt;断开,第一开关S<subgt;i,1</subgt;和第三S<subgt;i,3</subgt;闭合;当电池B<subgt;i</subgt;隔离时,开关第一S<subgt;i,1</subgt;和第三S<subgt;i,3</subgt;断开,开关第二S<subgt;i,2</subgt;闭合,且前一颗电池的第一前项开关S<subgt;i‑1,1</subgt;和第二前项S<subgt;i‑1,2</subgt;断开,第三前项开关S<subgt;i‑1,3</subgt;闭合。本发明分别计算状态价值和动作优势,更准确地估计每个状态的价值,减轻DQN对Q‑值的过度估计问题,以提高算法的稳定性和加快模型收敛速度。
技术研发人员:马志强,王淑静,高俊东
受保护的技术使用者:内蒙古工业大学
技术研发日:
技术公布日:2025/3/18
- 还没有人留言评论。精彩留言会获得点赞!