多微网系统能量管理方法、装置、系统及介质
本发明涉及智能电网,具体提供一种多微网系统能量管理方法、装置、系统及介质。
背景技术:
1、基于深度强化学习的微网能量管理技术能克服传统方法难以处理负荷需求意外变化的不足,但存在数据隐私保护及数据传输安全问题。而将具有数据隐私保护特性的联邦学习应用于微网能量管理,为解决该问题提供了一种可行技术途径。已有基于联邦深度强化学习的微网能量管理技术中,本地微网和中心服务器之间需要频繁交互模型参数而耗费大量通信时间,通信成本较高,且主要聚焦于电能方面,未考虑复杂的多类型能量转换以及不同微网之间的电量交易问题,导致多微网系统收益低。
技术实现思路
1、为了克服上述缺陷,提出了本发明,以提供解决或至少部分地解决如何提高多微网系统的收益的技术问题,即一种多微网系统能量管理方法、装置、系统及介质。
2、在第一方面,本发明提供一种多微网系统能量管理方法,所述多微网系统包括能量管理平台和若干微网,所述方法应用于微网,其特征在于,所述方法包括:
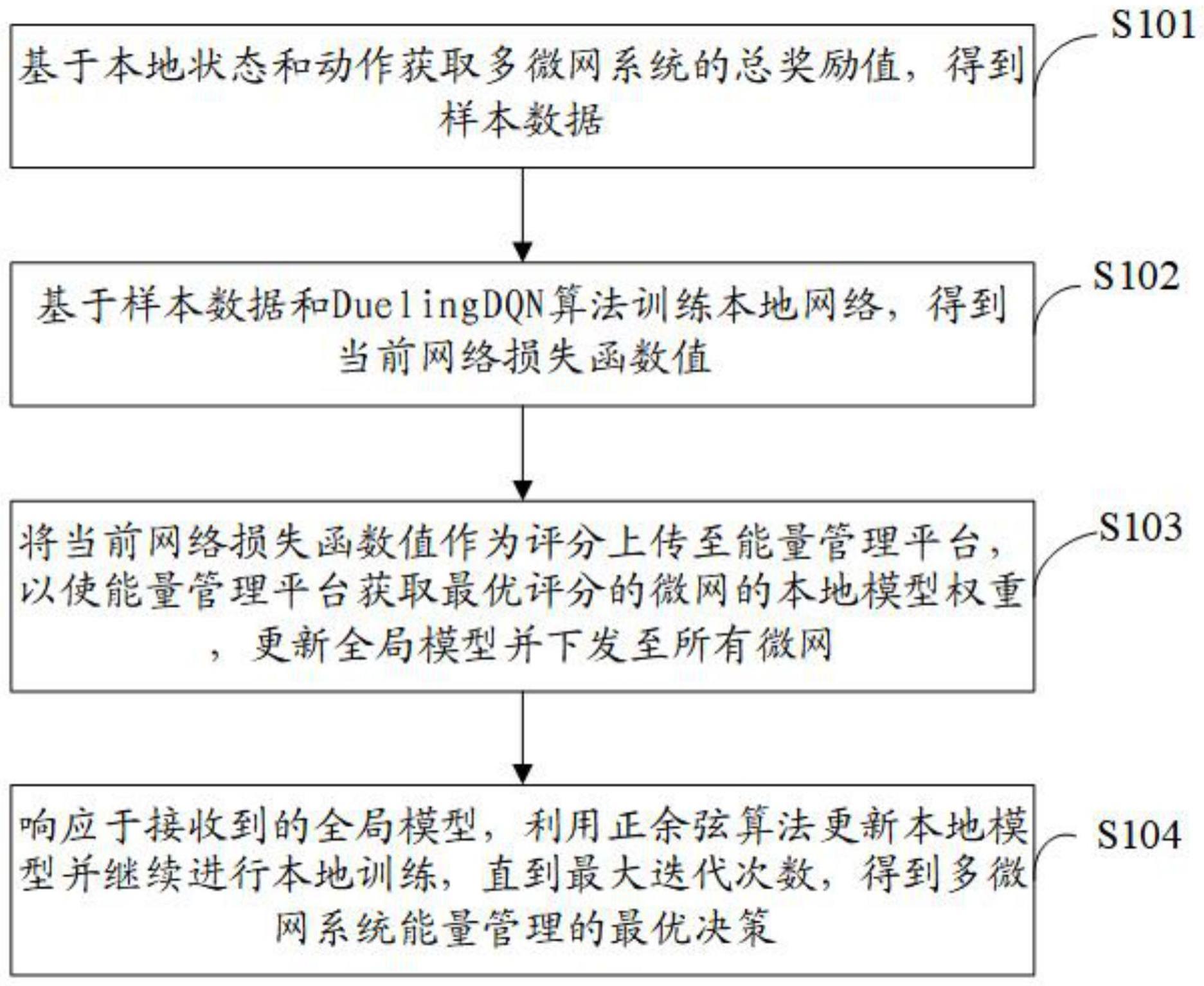
3、基于本地状态和动作获取多微网系统的总奖励值,得到样本数据,其中所述本地状态包括多种类型能量状态,所述总奖励值以经济收益为目标;
4、基于样本数据和dueling dqn算法训练本地网络,得到当前网络损失函数值;
5、将所述当前网络损失函数值作为评分上传至能量管理平台,以使能量管理平台获取最优评分的微网的本地模型权重,更新全局模型并下发至所有微网;
6、响应于接收到的全局模型,利用正余弦算法更新本地模型并继续进行本地训练,直到最大迭代次数,得到多微网系统能量管理的最优决策。
7、在上述多微网系统能量管理方法的一个技术方案中,
8、所述基于本地状态和动作获取多微网系统奖励值,得到样本数据,包括:
9、根据本地状态,利用ε-greed算法选择动作并执行动作,得到当前奖励值和下一时刻本地状态;
10、将自身奖励值上传至能量管理平台,以使能量管理平台累加所有微网奖励值得到多微网系统的总奖励值;
11、响应于能量管理平台下发的总奖励值,存储本地状态及其对应的动作、总奖励值和下一时刻本地状态并制作样本数据。
12、在上述多微网系统能量管理方法的一个技术方案中,
13、所述基于样本数据和dueling dqn算法训练本地网络,得到当前网络损失函数值,包括:
14、基于样本数据对本地网络进行训练,计算当前网络的价值函数和优势函数;
15、基于所述当前网络的价值函数和优势函数,计算当前网络q值;
16、基于样本的奖励值、奖励折扣因子和下一时刻本地状态从所有动作选择中使用目标网络计算出的最大q值,计算目标q值;
17、基于当前网络q值和目标q值的均方差,得到当前网络损失函数。
18、在上述多微网系统能量管理方法的一个技术方案中,
19、所述方法还包括:
20、对当前网络损失函数进行随机梯度下降计算,以更新当前网络q值的权重参数;
21、每隔预设时间步长将当前网络的参数复制到目标网络,以更新目标网络的参数。
22、在上述多微网系统能量管理方法的一个技术方案中,
23、所述当前网络损失函数:
24、
25、其中,m是样本总数,ym表示样本m的目标q值,sm和am表示样本m的状态和动作,θ为公共部分的网络参数,β为价值函数的网络参数,α为优势函数的网络参数,q(sm,am;θ,α,β)表示当前网络q值。
26、在上述多微网系统能量管理方法的一个技术方案中,
27、所述将所述当前网络损失函数值作为评分上传至能量管理平台,以使能量管理平台获取最优评分的微网的本地模型权重,更新全局模型并下发至所有微网,包括:
28、每隔预设时间步长将当前网络损失函数值作为评分上传至能量管理平台,以使能量管理平台比较所有微网的评分,选取最优评分的微网,得到其id并向此id的微网发送权重传输请求;
29、响应于接收到的所述权重传输请求,发送本地模型权重至能量管理平台,以使能量管理平台更新全局模型并下发至所有微网。
30、在上述多微网系统能量管理方法的一个技术方案中,
31、所述利用正余弦算法更新本地模型,包括:
32、
33、其中,为第j维第itr次迭代的当前神经网络层的权重值,为下一神经网络层的权重值,为全局模型神经网络层的权重值,k1为[0,1]之间的随机数,k2为[0,2π]之间的随机数,k3为[0,2]之间的随机数,k为[0,1]之间的随机数;
34、
35、maxitr为正余弦算法迭代的最大次数,即本地微网与能量管理平台交互次数,c为常数。
36、在第二方面,本发明提供一种控制装置,包括存储器、一个或多个处理器、一个或多个应用程序,其中,所述一个或多个应用程序存储在所述存储器中,所述一个或多个应用程序被配置为由所述一个或多个处理器调用时,使得所述一个或多个处理器执行如第一方面中任一项所述的方法。
37、在第三方面,本发明提供一种多微网系统,所述系统包括能量管理平台和如第二方面中所述的装置。
38、在第四方面,一种计算机可读存储介质,其特征在于,存储有多条程序代码,所述程序代码适于由处理器加载并运行以执行如第一方面中任一项所述的方法。
39、本发明上述一个或多个技术方案,至少具有如下一种或多种有益效果:
40、在实施本发明的技术方案中,基于正余弦联邦深度强化学习能量管理策略,本地微网以评分代替模型权重上传至能量管理平台即中心服务器,在保护各微网数据隐私性的前提下,得到更高奖励值且收敛性更优,增加了微网的经济收益,并且采用传递评分机制大大降低本地微网向中心服务器传输的数据量,设计了微网间能量交易与内部多种能量转换,在提高微网收益的同时降低了通信时延。
技术特征:
1.一种多微网系统能量管理方法,所述多微网系统包括能量管理平台和若干微网,所述方法应用于微网,其特征在于,所述方法包括:
2.根据权利要求1所述的多微网系统能量管理方法,其特征在于,所述基于本地状态和动作获取多微网系统奖励值,得到样本数据,包括:
3.根据权利要求1所述的多微网系统能量管理方法,其特征在于,所述基于样本数据和dueling dqn算法训练本地网络,得到当前网络损失函数值,包括:
4.根据权利要求3所述的多微网系统能量管理方法,其特征在于,所述方法还包括:
5.根据权利要求3所述的多微网系统能量管理方法,其特征在于,所述当前网络损失函数:
6.根据权利要求1所述的多微网系统能量管理方法,其特征在于,所述将所述当前网络损失函数值作为评分上传至能量管理平台,以使能量管理平台获取最优评分的微网的本地模型权重,更新全局模型并下发至所有微网,包括:
7.根据权利要求1-6中任一项所述的多微网系统能量管理方法,其特征在于,所述利用正余弦算法更新本地模型,包括:
8.一种控制装置,其特征在于,包括存储器、一个或多个处理器、一个或多个应用程序,其中,所述一个或多个应用程序存储在所述存储器中,所述一个或多个应用程序被配置为由所述一个或多个处理器调用时,使得所述一个或多个处理器执行如权利要求1-7中任一项所述的方法。
9.一种多微网系统,其特征在于,所述系统包括能量管理平台和如权利要求8中所述的装置。
10.一种计算机可读存储介质,其特征在于,存储有多条程序代码,所述程序代码适于由处理器加载并运行以执行如权利要求1-7中任一项所述的方法。
技术总结
本发明涉及智能电网技术领域,具体提供一种多微网系统能量管理方法、装置、系统及介质,旨在解决如何提高多微网系统的收益的问题。为此目的,本发明的一种多微网系统能量管理方法,包括:基于本地状态和动作获取多微网系统的总奖励值,得到样本数据;基于样本数据和DuelingDQN算法训练本地网络,得到当前网络损失函数值;将所述当前网络损失函数值作为评分上传至能量管理平台,以使能量管理平台获取最优评分的微网的本地模型权重,更新全局模型并下发至所有微网;响应于接收到的全局模型,利用正余弦算法更新本地模型并继续进行本地训练,直到最大迭代次数,得到多微网系统能量管理的最优决策。
技术研发人员:杨艳红,张国驹,邓卫,肖浩,马丽,裴玮
受保护的技术使用者:中国科学院电工研究所
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!