一种(n,1,v)卷积码生成多项式的盲识别方法与流程
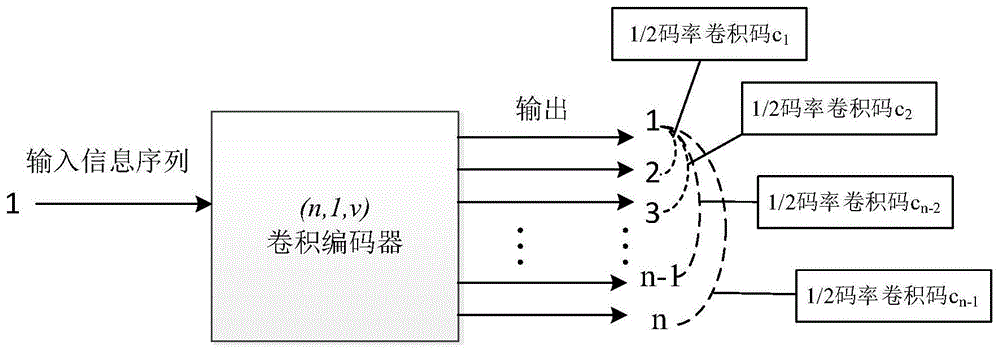
本发明属于通信
技术领域:
,具体的说是一种(n,1,v)卷积码生成多项式的盲识别方法。
背景技术:
:elias在1955年时最早引入了卷积码,因其独特的性能立即得到各方面的重视。1967年viterbi构造的最大似然译码算法,使卷积码能够在深空通信、移动通信等现代通信中扮演重要角色。因为卷积码优秀的纠错性能,广泛在级联码中使用,如在上世纪九十年代发现的turbo码等。目前w-cdma、ccsds、iee802.11等无线通信标准中均大量应用了卷积码。通信技术的快速发展,使信道编码识别领域得到越来越多的重视,卷积码作为一种重要的信道编码,其参数估计具有重要的研究价值。总结国内外公开发表的文献资料来看,目前的(n,1,v)卷积码的生成多项式识别方法主要有矩阵高斯消元法、walsh-hadamard变换法、建立关键模方程的双合冲算法等。其中walsh-hadamard变换法的抗误码性能最好,即使在7%的高误率下,生成多项式为(171,133)的(2,1,6)卷积码生成多项式识别率超过80%。但是对于(2,1,v)的卷积码,walsh-hadamard变换法的空间复杂度为24(v+1),计算时占用的存储空间随着存储级数v指数增加,当v=15时,空间复杂度为264约1.85×1019,一般的计算机已经难以进行计算。所以walsh-hadamard变换法的适用范围受存储级数的限制,当存储级数超过15基本不在适用。其它方法也难以识别存储级数v>20的卷积码。为了解决识别算法对存储级数的适应范围,本发明提出了一种(n,1,v)卷积码生成多项式盲识别方法,虽然相较于walsh-hadamard变换法抗误码性能有所下降,但大大拓宽了对卷积码存储级数的适应范围,对(4,1,61)卷积码仍然能够完成识别。技术实现要素:本发明的目的,就是利用接收数据,完成(n,1,v)卷积码的生成多项式的盲识别。本发明通过对接收数据矩阵经过高斯行消元之后的秩进行判断,若满秩则更换数据矩阵,当秩亏时计算解向量与测试矩阵的乘积,再对乘积的重量进行门限检测实现了校验向量的求解,进而完成生产多项式的识别。在本发明中,具体给出了存储级数v已知和未知情况下的识别生成多项式的解决方案。本发明针对的是1/n码率的卷积码,其中n≥2。在介绍n>2的(n,1,v)卷积码识别方法之前,先给出(2,1,v)卷积码生成多项式的盲识别方法,因为1/n码率的卷积码可以看成是n-1个1/2码率卷积码的组合,如图1所示。换句话说,识别(n,1,v)卷积码生成多项式的问题可以归结为做n-1次(2,1,v)码率卷积码生成多项式盲识别问题。本发明的具体实施步骤如下:s1:对待识别的(n,1,v)卷积码的码率n和存储级数v进行判断:如果n=2,并且存储级数v已知,则进入步骤s11;如果n=2,并且存储级数v未知,则进入步骤s2;如果n>2,则进入步骤s3;s11:初始化i=0,利用卷积码接收数据c={c1,c2,c3,…cn}的第2i+1比特到第6m+2i-2比特,即共6m-2比特构造系数矩阵a,其中m=v+1:s12:对矩阵a做二进制上的高斯行消元得到矩阵a',对矩阵a'的秩做判断,如果r(a')=2m,此时方程组aht=0的解向量h为1×2m的全零解,则舍弃该段数据,更新i=i+1,回到步骤s11;如果r(a')<2m,此时的a'有如下形式:其中i(2m-1)×(2m-1)为2m-1阶单位阵,01×(2m-1)为1×(2m-1)的全零向量,p(2m-1)×1为(2m-1)×1的非全零向量,01×1为1×1的零元素。则由矩阵a'中得到方程组aht=0的解向量h(如下所示),记录h和h的重量w1;s13:利用接收数据构造另一矩阵b(m×2m)作为测试矩阵,计算s=bht,计录s的重量为w2,其中b的构造方式如下:s14:计算检测门限式中m为矩阵b的行数,ε为误比特率;s15:若w2<t,判定已找到正确的解向量,则输出此时对应的解向量h,进入步骤s16;否则,舍弃该段数据,更新i=i+1,回到步骤s11,直到找到正确的解向量h或者接收数据用完为止;s16:将解向量h先倒序排列得到h':h'=[h2v+2,h2v+1,…,h2,h1]再将h'按1/2码率抽取即得到待识别卷积码生成多项式的各项系数,即可得到生成多项式:g=[g(1)(d),g(2)(d)]其中g(1)(d),g(2)(d)的各项系数分别为:g1=[h2v+2,h2v,…h2];g2=[h2v+1,h2v-1,…h1];s2:对n=2,存储级数v未知的(n,1,v)卷积码,其生成多项式的盲识别方法包括:s21:初始化m=2,设置最大遍历的范围值mmax;s22:对于当前的m,计算在此m下识别率为p0时所需要的数据量len,具体为,初始化k=6m-2:s221、计算pk:pk=(1-ε)k,ε为数据的误比特率;s222、判断pk是否大于或等于预设的p0,若是,则输出len=k;否则更新k=k+2,回到步骤s221;s23:取接收数据c={c1,c2,c3,…cn}的前len比特数据{c1,c2,c3,…clen}按照s1中的存储级数v已知的方法进行识别,若数据量len的数据使用完仍没有找到正确的解向量,判定当前的m不正确,则继续遍历m=m+1,如果遍历到m=mmax仍没有得到正确的解向量,则识别失败;s3:对n>2的(n,1,v)卷积码,其生成多项式的盲识别方法包括:s31:将1/n卷积码序列按码长分组成n路,抽取其中两路构成1/2码率卷积码,抽取组合方式为:第1路和第2路组合,第1路和第3路组合,……,第1路和第n路组合,共n-1个1/2码率卷积码,按照s2中的识别方法进行识别,共进行n-1次识别操作,并存储各次的识别结果:s32:在s31的n-1组全部识别结果中,求出gi(d)第一项阶次最高的解:s33:对各次识别结果进行遍历,比较gi(d)的第一项与gmax(d)是否相等,如果相等则直接保留gi(d);如果不相等,则说明它们存在倍式关系,对gi(d)乘以倍式操作:s34:组合得到(n,1,v)卷积码的生成多项式矩阵:本发明的有益效果为:无论存储级数是否已知,都能完成(n,1,v)卷积码生成多项式的识别,并且对于大存储级数的卷积码,只要数据量足够,仍然有较好的识别效果。附图说明图1是本发明中识别(n,1,v)卷积码生成多项式的问题转化为做n-1次(2,1,v)码率卷积码生成多项式盲识别问题的示意图。图2是本发明实施例3中m=10,20,30,40,50时,1%误码率下的理论识别概率p-数据量n曲线图图3是本发明实施例3中m=10,20,30,40,50时,1‰误码率下的理论识别概率p-数据量n曲线图图4是本发明中,未知存储级数v时(2,1,v)卷积码盲识别方法的实现流程图具体实施方式下面结合附图和实施例对本发明进行详细的描述,以便本领域的技术人员更好地理解本发明。实施例1:本实施例的目的在于展示本发明的实现过程。以一个生成多项式为(171,133)的(2,1,6)卷积码为例,假定已经知道存储级数v=6,误码率1%条件下,按照本发明的方法进行识别。具体执行如下:s1:由于n=2,且存储级数v=6已知,则执行s11-s16s11:利用接收卷积码比特流,初始化i=0,利用接收数据的第2i+1比特到第6m+2i-2比特(共6m-2=40比特,其中m=v+1=7)构造14×14的系数矩阵a;s12:构造14×14的数据矩阵,然后进行高斯行消元,表1为当前数据矩阵中存在误码时消元的结果a',结果为单位阵,矩阵满秩r(a')=2m=14舍弃。则更新i=i+1=0+1=1,再重复s11,s12。表1高斯行消元结果a'然后经过重复s11,s12,不断更新i以更新数据矩阵,某次高斯消元结果a'如表2所示:表2高斯行消元结果a'此时表2的结果不满秩,r(a')=13<2m=14,其解向量为:h=[11100011110111]t,重量w1=10。s13:利用接收序列构造另一数据矩阵b(50×14)作为测试矩阵。计算s=bht,计录s的重量为w2,此处算得w2=1。s14:由m=50,ε=0.01,w1=10计算检测门限:s15:由于w2=1<t=12.54,判定已找到正确解,输出此时对应的解向量h=[11100011110111]ts16:将解向量h先倒序排列得到h'=[11101111000111]t,再将h'按1/2码率抽取g1=[1111001]和g2=[1011011],改写为常用的8进制表示形式即:g=(171,133)。对比原来的生成多项式可知识别正确实施例2:本实施例的目的在于解释说明本发明中n>2时的(n,1,v)卷积码拆分为n-1组(2,1,v)卷积码的识别过程,且本实施例采用大存储级数的卷积码,证明了本发明对大存储级数卷积码的适应性。以存储级数非常大的(4,1,61)卷积码的识别过程为例进行说明,其生成多项式矩阵如下:g=[0004010000c08001,2001040000011001,0400000400004029,1](为表示方便,用16进制数表示),在接收序列长度30000bit,1‰误码率下进行在matlab中进行仿真实验。具体执行如下:s1由于n=4>2,执行s3.s31:将1/4码率卷积码序列按码长分组成4路,依次抽取其中两路构成1/2码率卷积码(第1路和第2路组合,第1路和第3路组合,第1路和第4路组合,共3组1/2码率卷积码)按照s2中的(2,1,v)卷积码步骤进行识别(共需进行3次识别操作),并存储各次的识别结果,3次识别结果如表3所示:表3(4,1,61)卷积码拆分成1/2卷积码使用本发明方法识别结果s32:在s31的3组全部识别结果中,求出gi(d)第一项阶次最高的解为:gmax=4010000c08001s33:对各次识别结果进行遍历,比较gi(d)的第一项与gmax(d)是否相等,如果相等则直接保留gi(d);如果不相等,则说明它们存在倍式关系,对gi(d)乘以倍式操作:由上式知,与各项的第一项阶次比较后,若不等则需要先进行二进制上的多项式除法运算:值得注意的是,模2除法与普通二进制算术除法类似,但不同的是,此处的模2除法为不带借位的除法,本质上就是异或运算。下面以第1组的结果g1为例进行详细说明:gmax=4010000c08001(16)=100000000010000000000000000110000001000000000000001(2)上面的模2除法运算的结果为1001,用多项式形式表示即:求得倍式关系后,按照s33的描述,接着对g1乘以倍式操作:同理,对g2,g3重复进行相同的操作,处理后的结果如表4所示:表4乘以倍式处理后结果组别处理结果(为表示方便,多项式系数用16进制表示)多项式阶次g1(4010000c08001,2001040000011001)(50,61)g2(4010000c08001,400000400004029)(50,56)g3(4010000c08001,1)(50,0)s34:根据表4的结果,组合得到待识别1/n卷积码的生成多项式矩阵为:g=(4010000c08001,2001040000011001,400000400004029,1)将它与原始(4,1,61)生成多项式进行比较可知,识别结果完全正确。实施例3本实施例的目的在于方法容错性与所需数据量分析,同时说明本发明中s22中计算公式的得来过程,并仿真绘制了m为10,20,30,40,50时,不同数据量n条件下的理论识别概率p曲线,从理论上证明了发明对大存储级数卷积码的适应性。假设数据的误码率为ε,考察用于高斯消元的数据矩阵a,该矩阵使用的总数据量为(6m-2)bit,则能成功求解出正确的校验向量的条件为:在含误码的比特流中能够找到一段长度为6m-2的连续无误码的数据段,而任意一段长为6m-2的数据满足条件的概率为(令k=6m-2):p=(1-ε)6m-2=(1-ε)k相应的,不满足条件即识别失败的概率为:p=1-p接下来尝试用递推的方式推导在给定数据量n(n≥k)时,能够正确识别校验向量的概率pn;(记“在给定数据量n条件下正确识别校验向量”为事件an)当n=k时,有:pn=(1-ε)k当n=k+2时:因此可递推得出:给定任意的数据量n,(n≥k),可以由以下公式计算出理论识别概率pn(由pk计算pk+2,由pk+2计算pk+4……以此类推最后由pn-2计算pn)。通过上述公式可以分析数据量为多少时足够完成识别。图2和图3分别给出了在误码率为1%和1‰时,m为10,20,30,40,50时,不同数据量n条件下的理论识别概率p。对于1/2码率的卷积码,m=50已经非常大了,针对这一个列子,从图2和图3中可以看到:在1‰的误码率条件下,m=50的1/2码率卷积码使用5000bit数据足以完成识别;而在1%误码率下,使用10000bit数据识别概率已经接近于1。可见,理论上该方法对存储级数很大的卷积码,仍然有较好的识别效果。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1