基于前后向交替迭代的Turbo码译码实现方法
本发明属于通信,具体涉及一种基于前后向交替迭代的turbo码译码实现方法。
背景技术:
1、在通信技术领域编码译码是必不可少的通信手段,可以提高传输效率。香农理论是编码译码的基础理论,而turbo码是接近香农极限的好码。现有技术采用双二元turbo码编码和双二元turbo码译码实现传输。
2、参考图1,turbo码是接近香农极限的好码,实质是在并行级联的两个独立的分量码编码器的基础上,引入了能够将码变成伪随机长码的伪随机交织器,译码采用循环迭代译码的思想。双二元turbo码与经典turbo码相似,而其“双二元”体现在双二元turbo码是并行输入了两列比特序列,即信息序列按比特初始顺序依次两两分为一组符号,第i个符号即为相邻的两比特构成的二元组(ai,bi),其中ai表示第i个符号中的前一个比特,bi表示第i个符号中的后一个比特。图1为双二元turbo码编码器的总体结构,其有两路支路,主要的构成部分有分量码编码器、交织器、删余器三部分。进行编码时,首先将信息序列进行串并转换,以比特顺序依次分成二元组(ai,bi),并将其对应的两比特序列并行输入到编码器中,通过切换抽头以分时复用的方式将信息比特序列输入两个支路。当开关切换为1时,比特序列通过上支路直接进入分量码编码器进行编码;当开关切换到2时,比特序列先经过交织器完成交织再进入分量码编码器进行编码,两个分量编码器采用相同结构。编码后输出两个分量码编码器对应的校验序列y1w1和y2w2。校验序列通过删余器即可形成多种码率的编码输出,y1w1校验序列删余后为z1,y2w2删余后为z2。最后,将原始输入的信息序列与校验序列进行并串转换即得到双二元turbo码编码器最终的输出序列。
3、参考图2,对应于双二元turbo码的两个分量码,采用两个分量码译码器分别译码。在两个分量码译码器间,采用外信息进行交互,不断地迭代译码。为了得到更优的性能,分量码译码要采用siso算法,以便于通过交换软信息完成两个子译码器的信息交互。最大后验概率(maximum a posteriori,map)算法是一种在多次迭代译码后能够收敛到最优译码性能的译码算法。其推导原理是对接收信号序列进行处理,计算不同符号的后验概率,选取后验概率最大的符号作为判决结果。
4、然而现有技术存在以下缺陷:
5、(1)在分量码译码过程中,要求前一个时刻的计算结果在一个时钟之内完成,以此结果递推到下一个状态的计算中去。这个单时钟计算的要求对于双二元turbo码则非常困难,因为输入的量多,且涉及的计算复杂,需要消耗很多的硬件资源以保证递推过程的顺利进行。导致大量的计算无法利用多个时钟进行流水处理,导致了turbo码译码器的工作时钟难以提升的难题。
6、(2)双二元turbo码的译码过程中,前向和后向状态度量以及对数似然比等量都需要进行四输入的max*运算。四输入的max*运算需要通过两两递推进行,该算法过程复杂度高。
7、(3)对于双二元turbo码的译码过程由于计算过程计算量过大,实际实现中,一个时钟内完成计算依然很紧张,稍有延误就无法顺利实现流水线处理递推计算,对系统产生很大影响。
技术实现思路
1、为了解决现有技术中存在的上述问题,本发明提供了一种基于前后向交替迭代的turbo码译码实现方法。本发明要解决的技术问题通过以下技术方案实现:
2、本发明提供了一种基于前后向交替迭代的turbo码译码实现方法,应用于每一个分量码译码器,分量码译码器之间形成反馈,所述基于前后向交替迭代的turbo码译码实现方法包括:每个分量码译码器在每个译码循环次均执行:
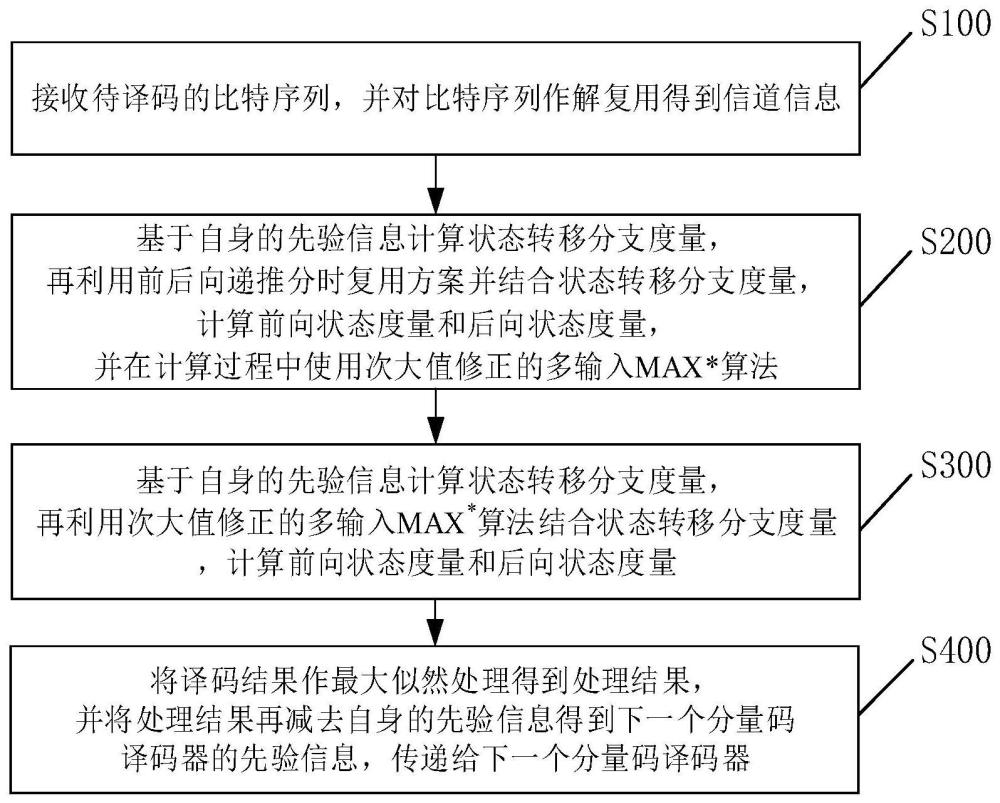
3、s100,接收待译码的信息序列,并对所述信息序列作解复用得到信道信息;
4、s200,基于自身的先验信息计算状态转移分支度量,再利用前后向递推分时复用方案并结合所述状态转移分支度量,计算前向状态度量和后向状态度量,并在计算过程中使用次大值修正的多输入max*算法;
5、s300,利用所述前向状态度量、所述后向状态度量、所述状态转移分支度量和自身的先验信息对所述信道信息作译码,得到译码结果存储起来;
6、s400,将所述译码结果进行对数似然处理得到处理结果,并将所述处理结果再减去自身的先验信息得到下一个分量码译码器的先验信息,传递给下一个分量码译码器。
7、有益效果:
8、1、本发明对四输入max*运算进行优化,原本的四输入max*运算需要进行三次二输入max*运算,优化后的基于次大值修正的多输入max*算法只需要进行一次排序,和一次二输入max*运算即可,因此可以降低计算资源;
9、2、本发明前后向递推分时复用方案,以将递推计算扩展到两个时钟计算的前提下,降低了一半的计算资源消耗,只比单时钟递推计算流程多用了k/2个时钟的处理时间。考虑到采用两个时钟进行流水计算所获得的时序收敛和最高工作时钟方面的好处,本发明采用的前后向递推分时复用的分量码码译码流程在资源消耗和译码吞吐量方面都具有较大的优势,是一种优化的分量码译码结构。
10、以下将结合附图及实施例对本发明做进一步详细说明。
技术特征:
1.一种基于前后向交替迭代的turbo码译码实现方法,其特征在于,应用于每一个分量码译码器,分量码译码器之间形成反馈,所述基于前后向交替迭代的turbo码译码实现方法包括:每个分量码译码器在每个译码循环次均执行:
2.根据权利要求1所述的基于前后向交替迭代的turbo码译码实现方法,其特征在于,s200包括:
3.根据权利要求2所述的基于前后向交替迭代的turbo码译码实现方法,其特征在于,所述前向状态度量和所述后向状态度量的计算过程中递推方向相反,从初始时刻到第k时刻所述前向状态度量的序号依次增加,所述后向状态度量的序号依次递减。
4.根据权利要求2所述的基于前后向交替迭代的turbo码译码实现方法,其特征在于,s230包括:
5.根据权利要求4所述的基于前后向交替迭代的turbo码译码实现方法,其特征在于,s232中计算前向状态度量的过程包括:
6.根据权利要求4所述的基于前后向交替迭代的turbo码译码实现方法,其特征在于,s232中计算后向状态度量的过程包括:
7.根据权利要求1所述的基于前后向交替迭代的turbo码译码实现方法,其特征在于,s300包括:
8.根据权利要求7所述的基于前后向交替迭代的turbo码译码实现方法,其特征在于,s320包括:
9.根据权利要求1所述的基于前后向交替迭代的turbo码译码实现方法,其特征在于,s300的执行过程与s200的执行过程在不同的硬件中运行,或在同一硬件的不同模块中运行。
10.根据权利要求9所述的基于前后向交替迭代的turbo码译码实现方法,其特征在于,s300的开始执行时间至少晚于s200执行一半的时间。
技术总结
本发明提供了基于前后向交替迭代的Turbo码译码实现方法,包括:对接收的序列作解复用得到信道信息;基于自身的先验信息计算状态转移分支度量;本发明对现有四输入MAX<supgt;*</supgt;运算作优化,提出基于次大值修正的多输入MAX<supgt;*</supgt;算法,再利用前后向递推分时复用方案将递推计算扩展到两个时钟计算,降低了一半的计算资源消耗;结合次大值修正的多输入MAX<supgt;*</supgt;算法和状态转移分支度量,计算前向状态度量和后向状态度量;之后对信道信息作译码,将译码结果作对数似然处理得到的结果再减去自身的先验信息得到下一个分量码译码器的先验信息。因此本发明可以提高译码过程中的时序收敛性,且降低资源消耗、提高吞吐量。
技术研发人员:马卓,张若婷,杜栓义
受保护的技术使用者:西安电子科技大学
技术研发日:
技术公布日:2024/6/18
- 还没有人留言评论。精彩留言会获得点赞!