一种新型Turbo码译码状态值归一化方法与流程
本发明属于turbo编译码处理以及纠错编码,涉及一种新型turbo码译码状态值归一化方法。
背景技术:
1、无线通信中,通常使用编译码实现低信噪比下的数据可靠传输,turbo编码作为一种常用的前向纠错(forward error correction,fec)技术,其将卷积码和随机交织器结合,在实现随机编码的同时,通过交织器实现了短码构造长码,并采用软输出迭代译码来逼近最大似然译码。turbo码充分利用了shannon信道编码定理的基本条件,得到了接近shannon极限的性能,因此获得了较为广泛的应用。
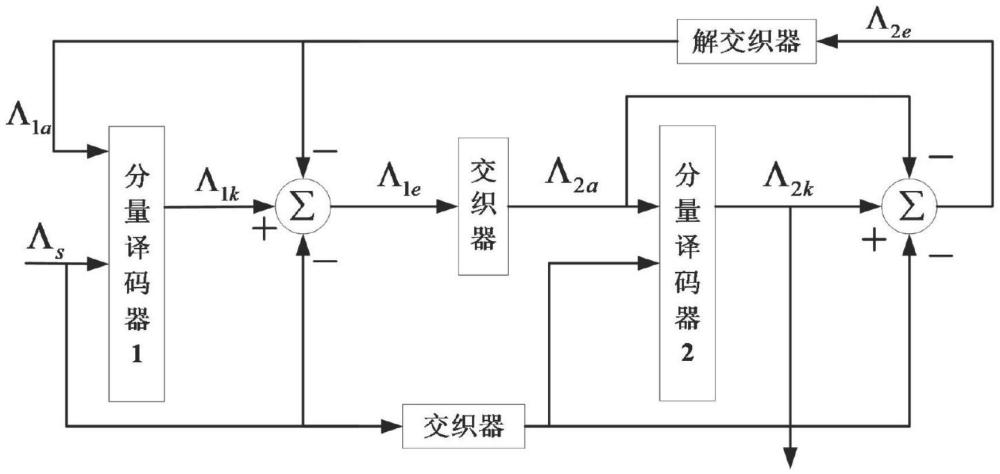
2、与turbo码的编码结构相比较,turbo码的译码过程就显得较为复杂,如图1所示。turbo码的译码过程是一个循环迭代译码的过程,在分量译码器里实现前向递推和后向递推的运算中,为了防止数据溢出,需要对每一比特的数个状态值进行归一化处理,即找出这些状态值里的最大值,然后各个状态值再都减去此最大值即可。该步骤需要数级流水才能完成,所以导致分量译码器的延时非常大。再加上多次迭代译码,在某些特定系统里,这种高延时的译码方案并不适用。
技术实现思路
1、(一)发明目的
2、本发明的目的是:为了解决传统turbo码译码存在的延时长的问题,提出一种新型turbo码译码状态值归一化方法,基于最大方向溢出的思想,省去传统归一化处理的流水计算,在不损害译码性能的前提下,大大减小译码延时。
3、(二)技术方案
4、为了解决上述技术问题,本发明针对传统turbo码译码状态值归一化处理流水多导致整体译码延时大的缺陷,提出一种新型turbo码译码状态值归一化方法。turbo码译码过程中每一个分量译码器里,都需要计算前向递推值和后向递推值,其采用相同的归一化处理方式;处理过程起始于turbo码译码的分量译码器里对某一比特计算出n个状态值后,参照图1所示,本发明方法包括以下步骤:
5、步骤一、对输入分量译码器的第一个比特计算出n个状态值x={x1,x2,…,xn},n=1,2,…n;
6、步骤二、将步骤一算出的状态值序列x逐一与正方向的最大值xmax和负方向的最小值xmin做比较:如果大于最大值,则标志位fmax_n置1,否则置0,由此获得标志序列fmax={fmax_1,fmax_2,…,fmax_n};如果小于最小值,则标志位fmin_n置1,否则置0,由此获得标志序列fmin={fmin_1,fmin_2,…,fmin_n};
7、步骤三、对步骤二得到的标志序列fmax和fmin进行判断:若都为全0,则不对状态值x做处理,新的状态值序列x'=x;若fmax不是全0,则对状态值x的每一个状态变量统一减去xmax,得到新的状态值序列x'={x1',x2',...,xn'};若fmin不是全0,则对状态值x的每一个状态变量统一减去xmin,得到新的状态值序列x'={x1',x2',...,xn'};
8、步骤四、将步骤三所得的新的状态值序列x'作为输入,计算出下一比特的n个状态值;
9、步骤五、重复步骤二到步骤四,完成所有比特的前向递推值和后向递推值的计算,进而完成整个译码过程。
10、其中:
11、(1)正方向的最大值xmax和负方向的最小值xmin可以根据译码过程数据的量化位宽来计算设定,一般情况下分别设定为量化位宽所能表示的最大值和最小值的一半即可;
12、(2)步骤二可以在计算状态值时同步计算出来,不需要额外的流水延时;
13、(3)步骤三可以用组合逻辑实现,不需要流水延时。
14、(三)有益效果
15、上述技术方案所提供的新型turbo码译码状态值归一化方法,与传统的状态值归一化处理操作相比,具有如下有益效果:
16、(1)大大减小了译码延时:传统的归一化处理操作,计算一个比特的所有状态值需要固定的两级流水,然后找其中的最大值需要数级流水,最后减去此最大值需要一级流水;而本发明方法只需要计算状态值所需的固定两级流水即可,延时大大减小;
17、(2)译码延时减小的同时,译码性能并没有回退,而且还略好于传统的操作方法,如图2所示。
技术特征:
1.一种新型turbo码译码状态值归一化方法,其特征在于,归一化处理过程起始于turbo码译码的分量译码器里对某一比特计算出n个状态值后,包括以下步骤:
2.如权利要求1所述的新型turbo码译码状态值归一化方法,其特征在于,turbo码译码过程中,每一个分量译码器里,都计算前向递推值和后向递推值,采用相同的归一化处理方式。
3.如权利要求2所述的新型turbo码译码状态值归一化方法,其特征在于,步骤一中,状态值序列记为:x={x1,x2,…,xn},n=1,2,…n。
4.如权利要求3所述的新型turbo码译码状态值归一化方法,其特征在于,步骤二中,状态值序列x逐一与正方向的最大值xmax做比较,如果大于最大值,则标志位fmax_n置1,否则置0,由此获得标志序列fmax={fmax_1,fmax_2,…,fmax_n}。
5.如权利要求4所述的新型turbo码译码状态值归一化方法,其特征在于,步骤二中,状态值序列x逐一与负方向的最小值xmin做比较,如果小于最小值,则标志位fmin_n置1,否则置0,由此获得标志序列fmin={fmin_1,fmin_2,…,fmin_n}。
6.如权利要求5所述的新型turbo码译码状态值归一化方法,其特征在于,步骤三中,标志序列fmax和fmin都为全0时,则不对状态值x做处理,新的状态值序列x'=x。
7.如权利要求6所述的新型turbo码译码状态值归一化方法,其特征在于,步骤三中,若fmax不是全0,则对状态值x的每一个状态变量统一减去xmax,得到新的状态值序列x'={x1',x2',…,xn'}。
8.如权利要求7所述的新型turbo码译码状态值归一化方法,其特征在于,步骤三中,若fmin不是全0,则对状态值x的每一个状态变量统一减去xmin,得到新的状态值序列x'={x1',x2',…,xn'}。
9.如权利要求8所述的新型turbo码译码状态值归一化方法,其特征在于,正方向的最大值xmax和负方向的最小值xmin根据译码过程数据的量化位宽来计算设定。
10.如权利要求9所述的新型turbo码译码状态值归一化方法,其特征在于,正方向的最大值xmax和负方向的最小值xmin分别设定为量化位宽所能表示的最大值和最小值的一半。
技术总结
本发明公开了一种新型Turbo码译码状态值归一化方法,过程为:对输入分量译码器的第一个比特计算出N个状态值,形成状态值序列X;将步骤一算出的状态值序列X逐一与正方向的最大值和负方向的最小值做比较,大于最大值的状态值形成标志序列F<subgt;max</subgt;,小于最小值的状态值形成标志序列F<subgt;min</subgt;;对步骤二得到的标志序列F<subgt;max</subgt;和F<subgt;min</subgt;进行判断,得到新的状态值序列X';将新的状态值序列X'作为输入,计算出下一比特的N个状态值;重复步骤二到步骤四,完成所有比特的前向递推值和后向递推值的计算,进而完成整个译码过程。本发明只需计算状态值所需的固定两级流水即可,延时大大减小。
技术研发人员:邵晓田,李永翔
受保护的技术使用者:天津津航计算技术研究所
技术研发日:
技术公布日:2025/3/10
- 还没有人留言评论。精彩留言会获得点赞!