一种基于Spark与YARN的邮件内容分析方法与流程
本发明涉及一种邮件内容分析方法,尤其涉及一种基于spark与yarn的邮件内容分析方法,应用于大量邮件内容分析、归类、查询、展示的处理框架。
背景技术:
邮件是人们在工作中一种主要的信息交换的通讯方式,是互联网应用最广泛的服务之一。通过邮件,人们可以以非常低廉的价格、非常快速而且安全的方式,与世界上任何一个地点的网络用户进行联络。同时,邮件的内容也可以是文本、图片、视频、文件等多种形式,可以传递大量的信息。
随着用户邮件数据在邮件服务器的累积,在政策允许和获得授权的情况下,具有邮件读取权限的公司和用户可以通过对邮件内容的分析来获取一些有价值的信息(如垃圾邮件分析),并且对新来的邮件进行相应处理。
邮件往往采用的是人类易读的自然语言来通讯的。邮件内容分析不同于文本分析之处在于:1)邮件可能包含多媒体文件,图片、音频甚至是文件等;2)邮件包含有一些特殊的属性,如收件人、抄送人、主题等;3)邮件之间有直接或间接的关联,如邮件的回复,相同主题的邮件等等。所以邮件分析处理不仅仅有自然语言分析处理的部分,也有邮件间关联分析的部分。
在大数据分析技术越来越成熟的今天,借助大数据手段可以快速分析上百万封,数据量数g到几十g,对邮件进行内容、主题定位,对邮件分类,特定信息抽取建模等。最终通过机器学习等手段达到新入邮件分类,邮件关联性内容可视化展示等。
技术实现要素:
邮件是人们在工作中一种主要的信息交换的通讯方式,是互联网应用最广泛的服务之一。通过邮件,人们可以以非常低廉的价格、非常快速而且安全的方式,与世界上任何一个地点的网络用户进行联络。同时,邮件的内容也可以是文本、图片、视频、文件等多种形式,可以传递大量的信息。
随着用户邮件数据在邮件服务器的累积,在政策允许和获得授权的情况下,具有邮件读取权限的公司和用户可以通过对邮件内容的分析来获取一些有价值的信息(如垃圾邮件分析),并且对新来的邮件进行相应处理。
邮件往往采用的是人类易读的自然语言来通讯的。邮件内容分析不同于文本分析之处在于:1)邮件可能包含多媒体文件,图片、音频甚至是文件等;2)邮件包含有一些特殊的属性,如收件人、抄送人、主题等;3)邮件之间有直接或间接的关联,如邮件的回复,相同主题的邮件等等。所以邮件分析处理不仅仅有自然语言分析处理的部分,也有邮件间关联分析的部分。
在大数据分析技术越来越成熟的今天,借助大数据手段可以快速分析上百万封,数据量数g到几十g,对邮件进行内容、主题定位,对邮件分类,特定信息抽取建模等。最终通过机器学习等手段达到新入邮件分类,邮件关联性内容可视化展示等。
说明书附图
图1,为本发明所述系统的流程示意图;
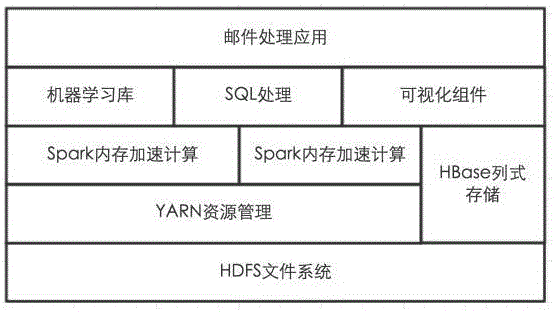
图2,为本发明所述系统的系统框架图;
图3,为本发明所述系统的数据处理示意图。
具体实施方式
结合说明书附图1,对本发明所述系统的数据处理过程进行详细描述:
1)步骤1,数据处理:
本系统将原始的邮件数据上传到hdfs,通过读取这些保存在hdfs上的文件,提取邮件元数据以及邮件内容,将读取到的记录保存到hbase存储中,并将邮件数据记录序列化转换后合并写入到新的hdfs文件中。
进一步的上述原始mail数据格式可能是xml、html、txt等,xml或html等可以包含图片、视频等多媒体文件。
数据的预处理主要用于:
1)将邮件文件合并,避免在数据处理时大量的小文件读写,提高系统io的效率;2)提高存储效率,hdfs直接存储适用于大文件,小文件存储会降低控件利用率,通常情况下一个50kb,甚至更小的邮件文件需要占用一个block大小的hdfs容量,通常系统默认是128mb,采用hbase列式存储邮件原文件一个原因也是因为此;
3)在处理原始邮件数据时,一并引入序列化过程,因此不论是对于持久化或是数据处理而言,效率都会是相对很高的。
2)步骤二、经过预处理的数据文件存放在hdfs上,通过自然语言分析处理工具对邮件内容进行主题定位和特征词提取,并根据特征词与主题的关联程度赋以不同的权重,对邮件内容进行量化。
例:设定一组主题,1)网购,2)体育,3)音乐,4)汽车,5)残障关爱。对于邮件内容为(内容虚构):
from:news@chinasports.com
to:li4@mail.com
cc:sports_subscribe@chinasports.com,zhang3@mailservice.com…
content:
…中国盲人足球队自2006年建队以来取得了不俗的成绩,2008年获北京残奥会亚军,2010年获盲人足球世锦赛季军和广州亚残运会冠军,2012年获伦敦残奥会第五名。2007年、2009、2011年、2013年连续4届获得盲人足球亚锦赛冠军。
的邮件中,从中提取一些关键词:
中国,盲人,足球队,北京,残奥会,亚军,世锦赛,季军,亚残运会,冠军,伦敦,亚锦赛…
根据每个主题的一些预先设定的现有词库确定(出现的频数,与词库中词汇的紧密程度)这个邮件的属于各个主题的程度,它是一个多维数组。针对这个邮件计算出的可能结果为:
(5,33,2,-10,11,...)
我们可以根据此来确定,它更倾向于属于“体育”的主题。同时,“特征鲜明”的词汇也会补充到预设主题的词汇中去,让词汇更丰富,训练集更有效精准。
3)步骤三、聚类。结合说明书附图3进行详述。依据步骤二输出的量化信息对邮件进行分类,将具有关联关系的邮件放在一个划分集合内。通过计算两个邮件特征量化参考值之间的欧氏距离,计算两封邮件之间的类似程度(完全一样的两个个体之间这个值是0)。
这个过程经过多次迭代计算,每一次计算的结果都是一次重新的归类划分,直到最后一次划分结果不再变化或者数量超过预先设定的迭代次数。
4)步骤四、:查询与可视化,将第二阶段与第三阶段计算的结果,以元数据形式附加到相应的一条邮件记录上,写回到hbase数据库,向外提供灵活的查询服务。提供的查询展示服务主要有:同一类邮件按相似程度展示、符合某一类特征的邮件按时间发生先后次序展示等。
上述的同一类邮件按相似程度展示,在具体实施过程为:
对于给定邮件a,通过第三阶段查询到的聚类结果,展示同一聚类下的邮件列表,排序依据为邮件与a的相似程度(两者欧氏距离)从小到大排列。越相似的邮件排名越靠前。
上述的符合某一类特征的邮件按时间发生先后次序展示,在具体实施过程为:
对于给定邮件b、c、d,对于同一主题,体育,足球赛事的符合程度分别为81%,83%,79%,设定80%以上可属于基本吻合。在结果展示时,b、c按照邮件的发送自然时间前后排序。
技术特征:
技术总结
本发明为一种基于Spark与YARN的邮件内容分析方法,应用于大量邮件内容分析、归类、查询、展示的处理框架。本发明所述分析方法,将大量邮件数据内容经过预处理后,进行主题定位和特征词提取,并根据特征词与主题的关联程度赋以不同的权重,对邮件内容进行量化。再根据量化结果,对邮件进行分类,将具有关联关系的邮件放在一个划分集合内。通过算法计算两封邮件之间的类似程度,并进行多次迭代计算,并将最终计算结果,写回到HBASE数据库,向外提供灵活的查询服务。本发明基于spark on YARN数据分析平台实时性、高效性、高数据吞吐能力,实现了一套邮件分析、查询及可视化的完整方案。
技术研发人员:高颜
受保护的技术使用者:北京易讯通信息技术股份有限公司
技术研发日:2016.06.22
技术公布日:2017.12.29
- 还没有人留言评论。精彩留言会获得点赞!