一种连麦直播方法和系统与流程
本发明涉及网络直播技术领域,特别涉及一种连麦直播方法和系统。
背景技术:
构建在互联网技术上的网络社交平台随着技术发展逐渐形成了一类连麦直播平台,直播平台需要在主播端、嘉宾端和观众端之间建立实时的信息互动。图1为现有连麦直播技术中的数据传输架构示意图。如图1所示包括利用实时网络传输系统和分布式内容网络的服务器端直播流模式和客户端直播流模式,针对主播端场景的信息发布可以采用cdn网络(contentdeliverynetwork,即内容分发网络)将信息同步缓存至靠近观众的cdn网络节点,保证信息针对海量观众的实时发布。针对主播端场景中主播与嘉宾的互动,利用实时网络传输系统,例如sd-rtn网络(software-definedrealtimenetwork软件定义实时传输网络)实现主播端和嘉宾端交互数据的快速路由和实时传输,保证交互的实时性品质(即qos服务质量等级)。通常主播端发起与嘉宾端的交互过程,交互过程中主播端与嘉宾端间的交互信息通过通用音视频编码器形成信息封装发送对方,对方通过通用音视频解码器形成信息合成,在主播端或嘉宾端形成交互信息展现场景。主播端的展现场景形成标准的媒体流实时传送至流媒体服务器,通常流媒体服务器设置在cdn网络中,通过流媒体服务器向观众发布。现有技术中主播端与嘉宾端间的交互过程采用的主要实时传输技术方案还会包括基于rtmp协议(realtimemessageprotocol实时信息传输协议)的多路技术方案,以及基于webrtc(webreal-timecommunication网页实时通信)的p2p技术方案,媒体流向观众传输可以是基于rtmp或hls(httplivestreaming),流格式可以是flv(flashvideo)等,交互场景中的音视频编解码可以采用h.26x等编码技术。现有技术基本可以满足在有限分辨率的简单场景中连麦直播各方的音视频交互信息的实时传输控制。
连麦直播平台需要消耗的数据带宽属于高服务质量等级,由于直播场景中的交互对象缺乏有效技术手段实现交互信息融合和优化,导致主播端与嘉宾端的交互音视频数据量较大可能对传输实时性造成影响。随着主播端与嘉宾端间连麦直播的视频清晰度向高分辨率发展,就会对规划路由上的网络带宽持续快速消耗,增加骨干网络边缘的数据突发流量,造成主播、嘉宾与观众间的实时带宽控制手段逐渐失效,极大影响直播过程的流畅度。
受实时带宽质量的限制,连麦直播场景中交互对象的类型、数量和分辨率也受到影响很难统一调度,只能消耗有限资源采用分层叠加的方式简单合成,造成主播端与嘉宾端间的交互方式死板,冗余信息和无效信息较多。
技术实现要素:
有鉴于此,本发明实施例提供了一种连麦直播方法和系统,用于解决连麦直播平台的交互场景中缺乏交互对象的优化手段,交互信息量无法有效控制的技术问题。
本发明的连麦直播方法,应用于连麦直播的互动过程,包括:
在建立所述连麦直播的过程中,在主播端和嘉宾端分别设置本端真实对象,所述主播端和所述嘉宾端中至少有一端设置与所述本端真实对象同步变化的本端虚拟对象;
在所述连麦直播的过程中,在所述主播端和所述嘉宾端中至少有一端将所述本端虚拟对象替代所述本端真实对象传送至主播场景中,被传送的所述本端虚拟对象接收对应的所述本端真实对象的动作控制数据形成同步变化;
将所述主播场景中形成的交互变化过程转换为流媒体,向观众直播。
本发明一实施例中,所述在建立所述连麦直播的过程中,在主播端和嘉宾端分别设置本端真实对象,所述主播端和所述嘉宾端中至少有一端设置与所述本端真实对象同步变化的本端虚拟对象包括:
在所述主播端建立坐标空间;
在所述坐标空间中建立所述本端真实对象,形成控制参考点;
获取虚拟对象和对应的模型控制点,形成所述本端虚拟对象;
建立所述模型控制点与所述控制参考点间的映射规则;
采集所述控制参考点的变化,根据所述映射规则形成所述动作控制数据。
本发明一实施例中,所述在建立所述连麦直播的过程中,在主播端和嘉宾端分别设置本端真实对象,所述主播端和所述嘉宾端中至少有一端设置与所述本端真实对象同步变化的本端虚拟对象包括:
在所述嘉宾端建立与所述主播端相关的坐标空间;
在所述坐标空间中建立所述本端真实对象,形成控制参考点;
获取虚拟对象和对应的模型控制点,形成所述本端虚拟对象;
建立所述模型控制点与所述控制参考点间的映射规则;
采集所述控制参考点的变化,根据映射规则形成所述本端虚拟对象的动作控制数据。
本发明一实施例中,所述在所述连麦直播的过程中,在所述主播端和所述嘉宾端中至少有一端将所述本端虚拟对象替代所述本端真实对象传送至主播场景中,被传送的所述本端虚拟对象接收对应的所述本端真实对象的动作控制数据形成同步变化包括:
所述主播端利用所述本端虚拟对象替代所述主播场景中的所述本端真实对象;
所述主播端向所述嘉宾端发起连麦请求,接受所述嘉宾端响应;
所述主播端发送本端真实对象给嘉宾端;
所述主播端接收所述嘉宾端的真实对象;
所述主播端通过所述主播场景中的所述本端虚拟对象和所述嘉宾端的真实对象进行交互。
本发明一实施例中,所述在所述连麦直播的过程中,在所述主播端和所述嘉宾端中至少有一端将所述本端虚拟对象替代所述本端真实对象传送至主播场景中,被传送的所述本端虚拟对象接收对应的所述本端真实对象的动作控制数据形成同步变化包括:
所述主播端在所述主播场景中采用本端真实对象;
所述主播端向所述嘉宾端发起连麦请求,接受所述嘉宾端响应;
所述主播端发送所述本端真实对象给所述嘉宾端;
所述主播端接收所述嘉宾端的虚拟对象;
所述主播端通过所述主播场景中的所述本端真实对象和所述嘉宾端的虚拟对象进行交互。
本发明一实施例中,所述在所述连麦直播的过程中,在所述主播端和所述嘉宾端中至少有一端将所述本端虚拟对象替代所述本端真实对象传送至主播场景中,被传送的所述本端虚拟对象接收对应的所述本端真实对象的动作控制数据形成同步变化包括:
所述主播端利用所述本端虚拟对象替代所述主播场景中的所述本端真实对象;
所述主播端向所述嘉宾端发起连麦请求,接受所述嘉宾端响应;
所述主播端发送所述本端虚拟对象给所述嘉宾端;
所述主播端接收所述嘉宾端的虚拟对象;
所述主播端通过所述主播场景中的所述本端虚拟对象和所述嘉宾端的虚拟对象进行交互。
本发明一实施例中,所述在所述连麦直播的过程中,在所述主播端和所述嘉宾端中至少有一端将所述本端虚拟对象替代所述本端真实对象传送至主播场景中,被传送的所述本端虚拟对象接收对应的所述本端真实对象的动作控制数据形成同步变化包括:
所述主播端在所述主播场景中采用所述本端真实对象;
所述主播端向所述嘉宾端发起连麦请求,接受所述嘉宾端响应;
所述主播端发送所述本端虚拟对象给若干个所述嘉宾端;
所述主播端接收每个所述嘉宾端的真实对象;
所述主播端通过所述主播场景中的所述本端真实对象和所述嘉宾端的真实对象进行交互。
本发明一实施例中,所述在所述连麦直播的过程中,在所述主播端和所述嘉宾端中至少有一端将所述本端虚拟对象替代所述本端真实对象传送至主播场景中,被传送的所述本端虚拟对象接收对应的所述本端真实对象的动作控制数据形成同步变化包括:
所述主播端在所述主播场景中采用所述本端虚拟对象;
所述主播端向所述嘉宾端发起连麦请求,接受所述嘉宾端响应;
所述主播端发送所述本端虚拟对象给若干个所述嘉宾端;
所述主播端接收每个所述嘉宾端的虚拟对象;
所述主播端通过所述主播场景中的所述本端虚拟对象和所述嘉宾端的虚拟对象进行交互。
本发明一实施例中,所述被传送的所述本端虚拟对象接收对应的所述本端真实对象的动作控制数据形成同步变化包括:
在所述主播端和所述嘉宾端间的物理链路上,所述本端真实对象在交互过程中的音视频数据与所述动作控制数据平行向所述本端虚拟对象传输。
本发明一实施例中,所述被传送的所述本端虚拟对象接收对应的所述本端真实对象的动作控制数据形成同步变化包括:
在主播端和嘉宾端间的物理链路上,所述本端真实对象在交互过程中的音视频数据与所述动作控制数据同步向所述本端虚拟对象传输。
本发明的连麦直播系统,包括:
对象关联模块,用于在建立所述连麦直播的过程中,在主播端和嘉宾端分别设置本端真实对象,所述主播端和所述嘉宾端中至少有一端设置与所述本端真实对象同步变化的本端虚拟对象;
对象交互模块,用于在所述连麦直播的过程中,在所述主播端和所述嘉宾端中至少有一端将所述本端虚拟对象替代所述本端真实对象传送至主播场景中,被传送的所述本端虚拟对象接收对应的所述本端真实对象的动作控制数据形成同步变化;
场景发布模块,用于将所述主播场景中形成的交互变化过程转换为流媒体,向观众直播。
本法马宁的连麦直播系统,包括:处理器和存储器,其中:
所述存储器,用于存储上述连麦直播方法的步骤程序;
所述处理器,用于执行双数连麦直播方法的步骤程序。
本发明的连麦直播方法和系统将主播端和嘉宾端的交互主体分别对象化和虚拟化,将各交互主体的动作表达参数化,将各交互主体的真实对象或虚拟对象配置在同一场景空间中,利用交互主体在交互中形成的连续动作表达形成控制参数以控制交互主体的虚拟对象做出准确交互动作,通过同一场景空间将连续时间内主播端和嘉宾端间的连贯交互表现形成实时媒体流进行发布直播。本发明实施例的连麦直播方法将主播端和嘉宾端间需要实时传输的真实对象的大数据量视频流转换为仅需要实时传输的小数据量动作表达参数和准实时传输的交互主体的虚拟对象,大大减小了实时数据传输的带宽需求,减轻了对实时数据传输系统的高质量带宽压力,使得数据传输系统的实时性服务质量可以进一步提高,为进一步形成多个嘉宾端与主播端的实时连麦直播互动、形成主播端与有限观众间的直播互动提供了重要的技术保证。本发明的连麦直播方法和系统同时丰富了交互主体的表现形式,使得单一交互主体的视觉表达类型和表达形象可以获得极大的丰富,使得连麦直播的场景内容灵活多变,较好地提升了观众的用户体验。
附图说明
图1为现有连麦直播技术中的数据传输架构示意图。
图2为本发明实施例连麦直播方法的流程图。
图3为本发明实施例的连麦直播方法的前置处理流程图。
图4为本发明实施例的连麦直播方法连麦直播的互动过程流程图(一)。
图5为本发明实施例的连麦直播方法连麦直播的互动过程流程图(二)。
图6为本发明实施例的连麦直播方法连麦直播的互动过程流程图(三)。
图7为本发明实施例的连麦直播方法连麦直播的互动过程流程图(四)。
图8为本发明实施例的连麦直播方法连麦直播的互动过程流程图(五)。
图9为本发明实施例的连麦直播系统的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
附图中的步骤编号仅用于作为该步骤的附图标记,不表示执行顺序。
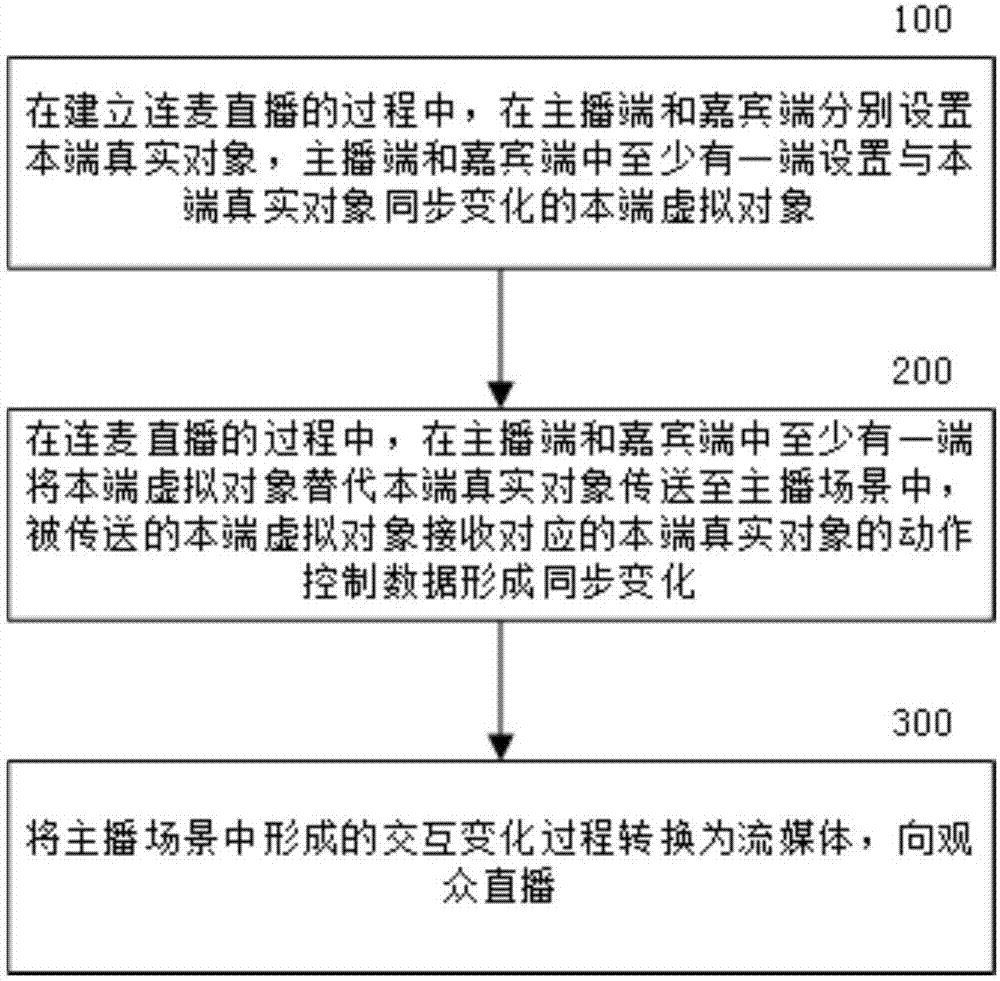
图2为本发明实施例的连麦直播方法的流程图。如图2所示包括:
步骤100:在建立连麦直播的过程中,在主播端和嘉宾端分别设置本端真实对象,主播端和嘉宾端中至少有一端设置与本端真实对象同步变化的本端虚拟对象。真实对象包括真实人、物形成的真实静态形象和真实动态形象等,例如静态表情和固定肢体姿态、动态表情和连续肢体动作等。虚拟对象为经立体建模形成的三维模型或二维模型,包括素材贴图。虚拟对象可以是根据真实主播对象形成的模型或创作作品形成的模型。
步骤200:在连麦直播的过程中,在主播端和嘉宾端中至少有一端将本端虚拟对象替代本端真实对象传送至主播场景中,被传送的本端虚拟对象接收对应的本端真实对象的动作控制数据形成同步变化。主播场景处于主播端的有效控制,使得主播场景可以形成复杂的场景调度,使得主播场景作为连麦场景或者包括连麦场景。例如场景调度形成的全景化的连麦场景,画中画的连麦场景,多个画中画的连麦场景等。
步骤300:将主播场景中形成的交互变化过程转换为流媒体,向观众直播。
本发明实施例的连麦直播方法将主播端和嘉宾端的交互主体(主播和嘉宾)分别对象化(真实对象)和虚拟化(虚拟对象),将各交互主体的动作表达参数化(利用参考点和参考点的变化记录动作),将各交互主体的真实对象或虚拟对象配置在同一场景空间(主播场景)中,利用交互主体在交互中形成的连续动作表达形成控制参数以控制交互主体的虚拟对象做出准确交互动作,通过同一场景空间将连续时间内主播端和嘉宾端间的连贯交互表现形成实时媒体流进行发布直播。本发明实施例的连麦直播方法将主播端和嘉宾端间需要实时传输的真实对象的大数据量视频流转换为仅需要实时传输的小数据量动作表达参数和准实时传输的交互主体的虚拟对象,大大减小了实时数据传输的带宽需求,减轻了对实时数据传输系统的高质量带宽压力,使得数据传输系统的实时性服务质量可以进一步提高,为进一步形成多个嘉宾端与主播端的实时连麦直播互动、形成主播端与有限观众间的直播互动提供了重要的技术保证。
图3为本发明实施例的连麦直播方法的前置处理流程图。如图3所示,在本发明一实施例中,步骤100中在建立连麦直播的过程中,包括:
步骤110:在主播端建立坐标空间。相应的在嘉宾端建立相关的坐标空间。相关的坐标基础使得一端的真实对象或虚拟对象可以在对端的坐标空间中合理展现,通过适当的调整和设置可以使两端的真实对象或虚拟对象在一端的坐标空间中形成需要的场景。
通过运行在主播端和嘉宾端的通用直播框架可以提供相同的坐标空间,以及对象们在场景合成中的比例、位置和相互关联的控制手段。
在本发明一实施例中,步骤100中在主播端和嘉宾端中至少有一端设置与本端真实对象的动作同步变化的本端虚拟对象包括:
步骤120:在主播端的坐标空间中建立本端真实对象,形成控制参考点。通常是指在主播端获得主播本身的形象,在嘉宾端获得嘉宾本身的形象,具体形象可以是主播本身或嘉宾本身的整个躯体或躯体的局部。获取真实对象可以采用摄像头进行视频采集的方式获得。通过形象识别可以在躯体或躯体的局部形成控制参考点,控制参考点随躯体或躯体的局部运动,控制参考点的位置变化可以反映真实对象的动作变化。
步骤130:获取虚拟对象和对应的模型控制点,形成本端虚拟对象。虚拟对象可以是根据主播本身形成的立体或平面建模模型,也可以是根据文学作品或其他真实对象形成的立体或平面建模模型。模型包括可调整形状的模型顶点和素材贴图,通过调整模型顶点的相对位置可以形成模型局部形状和素材贴图的相应变形变化,模型顶点可以作为改变模型形状的模型控制点。获取的虚拟对象可以是几个,分别对应不同虚拟形象。
步骤140:建立模型控制点与控制参考点间的映射规则。真实对象的模型控制点与每个虚拟对象的控制参考点间的映射可以是一对一、一对多或多对一。
步骤150:采集本端真实对象的控制参考点的变化,根据映射规则形成本端虚拟对象的动作控制数据。
步骤120至步骤150同样也可以应用在嘉宾端,嘉宾端也可以与主播端一样,形成与本端真实对象相应的本端虚拟对象之间的动作控制数据。
采集本端真实对象的动作变化,根据映射规则形成本端虚拟对象的动作控制数据。真实对象的动作变化由坐标空间中的主播本身或嘉宾本身的控制参考点的位置变化获得,根据选定的本端虚拟对象与对应的映射规则改变本端虚拟对象的模型控制点相对位置变化,形成对应的动作同步变化,本端虚拟对象随本端真实对象的动作同步变化。
通过现有的高速数据传输系统可以建立经过路由优化的主播端和嘉宾端间的物理链路,物理链路用于主播端和嘉宾端间的交互音视频对象以及真实对象、虚拟对象和动作控制数据的实时传输。
图4为本发明实施例的连麦直播方法连麦直播的互动过程流程图(一)。如图4所示在本发明一实施例中,步骤200中在主播端和嘉宾端中至少有一端将本端虚拟对象替代本端真实对象传送至主播场景中形成的交互过程包括:
步骤210:主播端利用本端虚拟对象替代主播场景中的本端真实对象。
步骤211:主播端向嘉宾端发起连麦请求,接受嘉宾端响应。
步骤212:主播端发送本端真实对象给嘉宾端。
步骤213:主播端接收嘉宾端的真实对象。
步骤214:主播端通过主播场景中的本端虚拟对象和嘉宾端的真实对象进行交互。
相应的在嘉宾端,嘉宾端通过嘉宾场景中的本端真实对象和主播端的真实对象进行交互。
在本实施例中,主播端利用本端的一个虚拟对象替代主播场景中对应的真实对象,使得主播端的主播形象和风格可以结合本端虚拟对象的人设特性形成更丰富直播情景,增加向观众直播的吸引力。主播端与嘉宾端的交互通过两端的真实对象交互,可以利用实时网络传输系统(例如sd-rtn网络)的服务质量保证表达丰富的交互情感和肢体动作细节,而在向观众直播中主播采用虚拟对象在保证交互品质的同时,有效降低了对观众直播带宽的需求,保证了向小范围高密度观众直播的实时性。
图5为本发明实施例的连麦直播方法连麦直播的互动过程流程图(二)。如图5所示在本发明一实施例中,步骤200中在主播端和嘉宾端中至少有一端将本端虚拟对象替代本端真实对象传送至主播场景中形成的交互过程包括:
步骤220:主播端在主播场景中采用本端真实对象。
步骤221:主播端向嘉宾端发起连麦请求,接受嘉宾端响应。
步骤222:主播端发送本端真实对象给嘉宾端。
步骤223:主播端接收嘉宾端的虚拟对象。
步骤224:主播端通过主播场景中的本端真实对象和嘉宾端的虚拟对象进行交互。
相应的在嘉宾端,嘉宾端通过嘉宾场景中的本端虚拟对象和主播端的真实对象进行交互。
在本实施例中,在主播端的主播场景中利用本端真实对象和嘉宾端的真实对象形成互动,而利用主播端的真实对象在嘉宾端的嘉宾场景中诱导嘉宾产生更丰富的主播形象和风格,可以使得嘉宾的人设特性形成更丰富直播情景,增加主播场景面向观众直播的吸引力。主播端与嘉宾端的交互通过两端间真实对象与虚拟对象交互,可以将对端间交互的部分视频数据转换为交互的动作控制数据,有效降低了对实时网络传输系统服务质量等级的需求,满足了嘉宾与主播交互过程中上下行链路不平衡或交互数据量不平衡的带宽需求,保证了交互过程的实时性。
图6为本发明实施例的连麦直播方法连麦直播的互动过程流程图(三)。如图6所示在本发明一实施例中,步骤200中在主播端和嘉宾端中至少有一端将本端虚拟对象替代本端真实对象传送至主播场景中形成的交互过程包括:
步骤230:主播端利用本端虚拟对象替代主播场景中的本端真实对象。
步骤231:主播端向嘉宾端发起连麦请求,接受嘉宾端响应。
步骤232:主播端发送本端虚拟对象给嘉宾端。
步骤233:主播端接收嘉宾端的虚拟对象。
步骤234:主播端通过主播场景中的本端虚拟对象和嘉宾端的虚拟对象进行交互。
相应的在嘉宾端,嘉宾端通过嘉宾场景中的本端真实对象或本端虚拟对象和主播端的虚拟对象进行交互。
在本实施例中,主播端利用本端的一个虚拟对象替代主播场景中对应的真实对象,同时利用嘉宾端的虚拟对象代替相应的嘉宾端的真实对象,使得主播和嘉宾的形象与风格可以结合本端虚拟对象的人设特性形成更丰富直播情景,增加向观众直播吸引力。主播端与嘉宾端的交互通过两端的虚拟对象交互,可以充分利用实时网络传输系统的服务质量保证表达丰富的交互情感和肢体动作细节,而在向观众直播中主播和嘉宾尽量采用虚拟对象可以将对端真实对象间交互的视频数据转换为交互的动作控制数据,有效降低了对实时网络传输系统服务质量等级的需求,可以满足主播与嘉宾间的高分辨率高帧率的实时游戏互动。
图7为本发明实施例的连麦直播方法连麦直播的互动过程流程图(四)。如图7所示在本发明一实施例中,步骤200中在主播端和嘉宾端中至少有一端将本端虚拟对象替代本端真实对象传送至主播场景中形成与上述交互过程结合的一种交互过程包括:
步骤240:主播端在主播场景中采用本端真实对象。
步骤241:主播端向嘉宾端发起连麦请求,接受嘉宾端响应。
步骤242:主播端发送本端虚拟对象给若干个嘉宾端。
步骤243:主播端接收每个嘉宾端的真实对象。
步骤244:主播端通过主播场景中的本端真实对象和若干嘉宾端的真实对象进行交互。
相应的在各嘉宾端,嘉宾端通过嘉宾场景中的本端真实对象和主播端的虚拟对象进行交互。
在本实施例中,在主播端的主播场景中利用本端真实对象和各嘉宾端的真实对象形成互动,而利用主播端的虚拟对象在各嘉宾端的嘉宾场景中诱导嘉宾产生更丰富的主播形象和风格,可以使得嘉宾的人设特性形成更丰富直播情景,增加主播场景面向观众直播的吸引力。主播端与各嘉宾端的交互通过两端间虚拟对象与真实对象交互,可以将对端间交互的部分视频数据转换为交互的动作控制数据,有效降低了群直播中主播对实时网络传输系统服务质量等级的需求,满足了多嘉宾与主播交互过程中上下行链路不平衡或交互数据量不平衡的带宽需求,保证了交互过程的实时性。
图8为本发明实施例的连麦直播方法连麦直播的互动过程流程图(五)。如图8所示在本发明一实施例中,步骤200中在主播端和嘉宾端中至少有一端将本端虚拟对象替代本端真实对象传送至主播场景中形成一种交互过程包括:
步骤250:主播端在主播场景中采用本端虚拟对象。
步骤251:主播端向嘉宾端发起连麦请求,接受嘉宾端响应。
步骤252:主播端发送本端虚拟对象给若干个嘉宾端。
步骤253:主播端接收每个嘉宾端的虚拟对象。
步骤254:主播端通过主播场景中的本端虚拟对象和若干嘉宾端的虚拟对象进行交互。
相应的在各嘉宾端,嘉宾端通过嘉宾场景中的本端虚拟对象和主播端的虚拟对象进行交互。
在本实施例中,主播端利用本端的一个虚拟对象替代主播场景中对应的真实对象,同时利用嘉宾端的虚拟对象代替相应的嘉宾端的真实对象,使得主播和嘉宾的形象与风格可以结合本端虚拟对象的人设特性形成更丰富直播情景,增加向观众直播吸引力。主播端与嘉宾端的交互通过对端的虚拟对象交互,可以充分利用实时网络传输系统服务质量保证表达丰富的交互情感和肢体动作细节,而在向观众直播中主播和嘉宾尽量采用虚拟对象可以将对端真实对象间交互的视频数据转换为交互的动作控制数据,有效降低了对实时网络传输系统服务质量等级的需求,可以在现有高速数据传输系统中实现主播与较多嘉宾间的实时互动。
有些真实对象会进一步包括真实声音等,例如原生声音等。虚拟对象会进一步包括虚拟声音,包括根据词汇、短语、语句形成的情绪表达声音。在本发明一实施例中,步骤200中被传送的本端虚拟对象接收对应的本端真实对象的动作控制数据形成同步变化包括:
在主播端和嘉宾端间的物理链路上,本端真实对象在交互过程中的音视频数据与动作控制数据平行向本端虚拟对象传输。
平行向虚拟对象传输是指在真实对象侧对交互过程中的音视频数据进行封装形成音视频封装数据,同时将真实对象侧形成的动作控制数据进行封装形成控制封装数据,音视频封装数据与控制封装数据采用不同的封装协议在不同的传输协议控制下进行传输。例如利用音视频封装数据采用h.264协议进行封装,控制封装数据采用rtmp或其他协议进行封装。采用本方法可以适应贷款服务等级较低时的路由重定向带来的延时。
在本发明一实施例中,步骤200中被传送的本端虚拟对象接收对应的本端真实对象的动作控制数据形成同步变化包括:
在主播端和嘉宾端间的物理链路上,本端真实对象在交互过程中的音视频数据与动作控制数据同步向本端虚拟对象传输。
同步向虚拟对象传输是指在真实对象侧对交互过程中的音视频数据和在真实对象侧形成的动作控制数据进行统一封装形成统一封装数据,音视频数据与动作控制数据采用统一的封装协议在相同的传输协议控制下进行传输。例如采用h.264协议进行对音视频数据封装,同时利用h.264协议封装格式中的保留字节封装动作控制数据,形成的统一封装数据可以充分利用h.264协议的纠错控制机制,保证数据的完整性。
图9为本发明实施例的连麦直播系统的结构示意图。如图9所示包括:
对象关联模块400:用于在建立连麦直播的过程中,在主播端和嘉宾端分别设置本端真实对象,主播端和嘉宾端中至少有一端设置与本端真实对象同步变化的本端虚拟对象。
对象交互模块500:用于在连麦直播的过程中,在主播端和嘉宾端中至少有一端将本端虚拟对象替代本端真实对象传送至主播场景中,被传送的本端虚拟对象接收对应的本端真实对象的动作控制数据形成同步变化。
场景发布模块600:用于将主播场景中形成的交互变化过程转换为流媒体,向观众直播。
对象关联模块400中包括:
场景规划子单元410:用于在主播端建立坐标空间。
真实对象获取单元420:用于在主播端的坐标空间中建立本端真实对象,形成控制参考点。
虚拟对象获取单元430:用于获取虚拟对象和对应的模型控制点,形成本端虚拟对象。
对象关联单元440:用于建立模型控制点与控制参考点间的映射规则。
数据采集单450:用于采集本端真实对象的控制参考点的变化,根据映射规则形成本端虚拟对象的动作控制数据。
对象交互模块500包括:
真实对象替换单元511,用于主播端利用本端虚拟对象替代主播场景中的本端真实对象。
真实对象布置单元512,用于主播端在主播场景中采用本端真实对象。
虚拟对象布置单元513,用于主播端在主播场景中采用本端虚拟对象。
还包括:
发送真实对象单元521,用于主播端发送本端真实对象给嘉宾端。
第一发送虚拟对象单元522,用于主播端发送本端虚拟对象给嘉宾端。
第二发送虚拟对象单元523,用于主播端发送本端虚拟对象给若干个嘉宾端。
还包括:
连麦直播建立单元530,用于主播端向嘉宾端发起连麦请求,接受嘉宾端响应。
还包括:
第一接收真实对象单元541,用于主播端接收嘉宾端的真实对象。
第一接收虚拟对象单元542,用于主播端接收嘉宾端的虚拟对象。
第二接收真实对象单元543,用于主播端接收每个嘉宾端的真实对象。
第二接收虚拟对象单元544,用于主播端接收每个嘉宾端的虚拟对象。
还包括:
第一场景交互单元551,用于主播端通过主播场景中的本端虚拟对象和嘉宾端的真实对象进行交互。
第二场景交互单元552,用于主播端通过主播场景中的本端真实对象和嘉宾端的虚拟对象进行交互。
第三场景交互单元553,用于主播端通过主播场景中的本端虚拟对象和嘉宾端的虚拟对象进行交互。
第四场景交互单元554,用于主播端通过主播场景中的本端真实对象和若干嘉宾端的真实对象进行交互。
第五场景交互单元555,用于主播端通过主播场景中的本端虚拟对象和若干嘉宾端的虚拟对象进行交互。
还包括:
第一传输单元561,用于在主播端和嘉宾端间的物理链路上,本端真实对象在交互过程中的音视频数据与动作控制数据平行向本端虚拟对象传输。
第二传输单元562,用于在主播端和嘉宾端间的物理链路上,本端真实对象在交互过程中的音视频数据与动作控制数据同步向本端虚拟对象传输。
本发明实施例的连麦直播系统包括处理器和存储器,其中:
存储器用于存储上述本发明实施例的连麦直播系统中的程序化的各装置和单元,或者存储上述本发明实施例的连麦直播方法中的程序化的步骤。
处理器用于执行存储器中的各装置和单元的程序,或者步骤的程序。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!