基于SparkStreaming的异常流量检测方法与流程
本发明涉及信息安全技术领域,具体的说,是一种基于sparkstreaming的异常流量检测方法。
背景技术:
网络的开放性在方便大众的同时带来了恶意访问、恶意攻击。这是各开放网站都面临的问题,怎样防止这些问题,降低服务器恶意载荷,增强服务器的安全是各开放网站的研究重点。当下的处理技术,一般是通过基于规则的waf进行过滤拦截,这样的处理技术可扩展性不强,与业务相关性不紧密。
技术实现要素:
本发明的目的在于提供一种基于sparkstreaming的异常流量检测方法,用于解决现有技术中基于waf进行过滤拦截,可扩展性不强,与业务相关性不紧密的问题。
本发明通过下述技术方案解决上述问题:
一种基于sparkstreaming的异常流量检测方法,包括:
步骤a,根据分布式数据存储中的数据创建参数访问模型;
步骤b,使用参数访问模型对分布式消息系统中的数据进行异常流量检测。
进一步地,所述步骤a具体包括:
步骤a1,由数据采集清洗单元采集线上流量,并对采集的流量进行预处理,然后将处理后的数据发送到分布式消息系统;
步骤a2,由数据转移存储单元将分布式消息系统中的数据存储到指定的分布式数据存储单元;
步骤a3,由访问参数训练单元将分布式数据存储单元的数据使用隐马尔可夫模型建立各请求参数以及参数顺序的参数访问模型。
进一步地,所述步骤b具体包括:
步骤b1,异常检测单元从分布式数据存储单元载入参数访问模型;
步骤b2,异常检测单元对分布式消息系统中的数据使用参数访问模型进行异常检测,并给出异常检测结果。
进一步地,所述分布式数据存储单元为由hadoop集群组成的分布式数据存储系统。
进一步地,所述分布式消息系统用于对清洗的数据进行暂存,生成sparkstreaming所需消费的主题数据,不同的业务生成各自的topic。
本发明与现有技术相比,具有以下优点及有益效果:
本发明提出了一种基于sparkstreaming的异常流量检测方法。对服务器端的流量进行收集、标准化清洗,然后将标准化数据传递给kafka消息系统,sparkstreaming通过隐马尔可夫模型建立业务的参数访问模型,由参数访问模型检测异常请求流量,业务关联紧密,且易于扩展。
附图说明
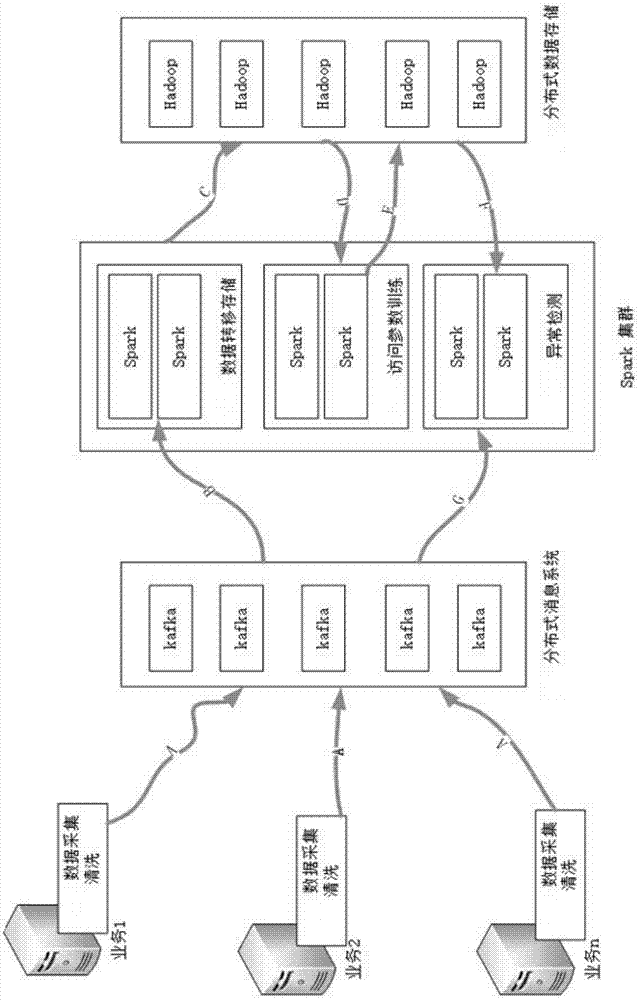
图1为本发明的结构框图。
具体实施方式
下面结合实施例对本发明作进一步地详细说明,但本发明的实施方式不限于此。
实施例1:
结合附图1所示,一种基于sparkstreaming的异常流量检测方法,包括两个阶段:
学习阶段:
步骤a:由数据采集清洗单元采集线上流量,对流量进行预处理、标准化处理,然后将处理的数据发送到分布式消息系统,等待被消费;
步骤b:由数据转移存储单元读取分布式消息系统中的数据;
步骤c:数据转移存储单元将读取的数据存储到指定的分布式数据存储单元;
步骤d:由访问参数训练单元将分布式数据存储单元的数据使用隐马尔可夫模型建立各请求参数以及参数顺序的参数访问模型;
步骤e:访问参数训练单元将参数访问模型存储到分布式数据存储单元中;
步骤f:异常检测单元从分布式数据存储单元载入参数访问模型;
步骤g:异常检测单元将分布式消息系统中的数据使用参数访问模型进行异常检测,并给出异常检测结果。
spark是一个分布式计算框架,其核心是弹性分布式数据集,可以快速在内存中对数据集进行多次迭代,以支持复杂的机器学习算法。sparkstreaming是一种构建在spark上的实时计算框架,它扩展了spark处理大规模流式数据的能力。同时具有以下优势:
能运行在多个节点上,并达到毫秒级延迟;
使用基于内存的spark作为执行引擎,具有高效性、容错性;
为实现复杂的算法提供和批处理类似地简单接口
结合spark计算框架,硬件支撑,合理的机器学习算法,能够有效检测异常流量。本发明基于sparkstreaming的异常流量检测方法。对服务器端的流量进行收集、标准化清洗,然后将标准化数据传递给kafka消息系统,sparkstreaming通过隐马尔可夫模型建立业务的参数访问模型。由参数访问模型检测异常请求流量。既降低了延时,提高了扩展性,又增强了与检测结果的交互性。
尽管这里参照本发明的解释性实施例对本发明进行了描述,上述实施例仅为本发明较佳的实施方式,本发明的实施方式并不受上述实施例的限制,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本技术公开的原则范围和精神之内。
技术特征:
技术总结
本发明公开了一种基于Spark Streaming的异常流量检测方法,包括:由数据采集清洗单元采集线上流量、预处理,将处理后的数据发送到分布式消息系统;由数据转移存储单元将分布式消息系统中的数据存储到指定的分布式数据存储单元;由访问参数训练单元建立各请求参数以及参数顺序的参数访问模型;使用参数访问模型进行异常流量检测。本发明对服务器端的流量进行收集、标准化清洗,将标准化数据传递给kafka消息系统,Spark Streaming通过隐马尔可夫模型建立业务的参数访问模型,由参数访问模型检测异常请求流量,与业务关联紧密,易于扩展。
技术研发人员:付强
受保护的技术使用者:四川长虹电器股份有限公司
技术研发日:2018.12.06
技术公布日:2019.02.19
- 还没有人留言评论。精彩留言会获得点赞!