一种基于机器学习的跨站脚本攻击识别方法与流程
1.本发明涉及网络数据安全技术领域,具体涉及一种基于机器学习的跨站脚本攻击识别方法。
背景技术:
2.当今,计算机网络技术发展得十分迅速,网络犯罪行为日益增加。网络犯罪行为主要有两种形式,一是非法获取系统数据,二是让系统无法提供服务。在非法获取系统数据方面,跨站脚本攻击利用网站漏洞恶意盗取信息是非常典型的攻击手段。与大多数攻击不同的是,跨站脚本漏洞涉及到攻击者、客户端和网站,而不像大多数攻击一样只有攻击者和受害者。这无疑增加了跨站脚本漏洞的攻防难度。
3.传统的方法是人工动态检测检测方法和静态检测方法两种方式进行。第一种动态检测方法,该方法从黑盒测试入手,又结合了渗透攻击相关的方法,实现了对xss漏洞的检测。当前的动态检测方法都会使用真实的xss攻击代码,或者利用网络爬虫对目标网页进行爬取分析,但是网络爬虫的时间开销十分巨大,且不能保证爬取到的页面数据覆盖了网站的全部页面,并且数据库中存储的攻击代码又无法涵盖所有的攻击场景,存取的开销对服务器的要求也非常。第二种静态检测方法是html5和cors属性规则在浏览器设计一个过滤器来检测xss攻击,并提供了一个系统来判断被拦截的请求是否有恶意企图。通过以上我们不难看出传统的跨站脚本检测方法往往需要花费大量的时间和精力来提取这些攻击数据的特征,而且还需要一定的经验相结合才能取得很好的效果。对人员依赖程度很大,人员能力水平参差不齐,会影响最终的效果,并且对服务器资源的开销也是非常大的。
技术实现要素:
4.本发明是为了解决现有技术中人们在使用互联网数据时无法及时有效预防跨站脚本攻击的技术问题,提供一种基于机器学习的跨站脚本攻击识别方法,能够有效提高跨站脚本攻击识别效率,提高安全性。
5.本发明提供一种基于机器学习的跨站脚本攻击识别方法,包括以下步骤:
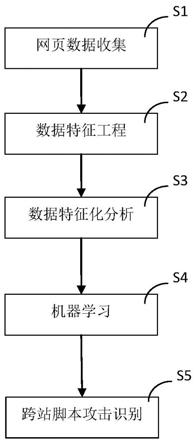
6.s1、网页数据收集:搭建含有跨站脚本攻击漏洞的靶场,使用扫描器和人工渗透的方式收集含有跨站脚本攻击的相关数据,对相关数据进行分类标注;
7.s2、数据特征工程:对相关数据进行数据清洗;
8.s3、数据特征化分析:将跨站脚本攻击语句视为文本信息,进行文本特征抽取,生成分词信息;
9.s4、机器学习:将分词信息通过xgboost集成算法模型进行训练,得到用于跨站脚本攻击识别的分类器模型;
10.s5、跨站脚本攻击识别:将web请求数据经过特征工程及向量化处理后进入分类器模型进行预测,识别跨站脚本攻击。
11.xgboost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。它在
gradient boosting框架下实现机器学习算法。xgboost提供并行树提升(也称为gbdt,gbm),可以快速准确地解决许多数据科学问题。相同的代码在主要的分布式环境上运行,并且可以解决数十亿个示例之外的问题。xgboost是对梯度提升算法的改进,求解损失函数极值时使用了牛顿法,将损失函数泰勒展开到二阶,另外损失函数中加入了正则化项。训练时的目标函数由两部分构成,第一部分为梯度提升算法损失,第二部分为正则化项。
12.本发明所述的一种基于机器学习的跨站脚本攻击识别方法,作为优选方式,相关数据包括请求参数、请求方法、响应内容、响应状态。
13.本发明所述的一种基于机器学习的跨站脚本攻击识别方法,作为优选方式,分类标注包括跨站脚本攻击类和非跨站脚本攻击类。
14.本发明所述的一种基于机器学习的跨站脚本攻击识别方法,作为优选方式,扫描器为wvs或appscan。
15.本发明所述的一种基于机器学习的跨站脚本攻击识别方法,作为优选方式,步骤s2进一步包括以下步骤:
16.s21、采用下采样算法将相关数据中包含缺失值的数据清除;
17.s22、使用xpath将响应内容中的标签去除,只保留页面内容;
18.s23、采用urlparse包中的方法将所述请求参数、ip地址、端口号进行区分;
19.s24、使用pearson相关系数评价相关数据的特征变量跟特征之间的关系,去除和最终类别无关的数据。
20.xpath即为xml路径语言(xml path language),它是一种用来确定xml文档中某部分位置的语言;xpath基于xml的树状结构,提供在数据结构树中找寻节点的能力。
21.pearson相关系数(pearson correlation coefficient)是用来衡量两个数据集合是否在一条线上面,它用来衡量定距变量间的线性关系。
22.本发明具有以下优点:
23.(1)对跨站脚本的识别方式更加灵活多样;
24.(2)减少了对人员的依赖程度;
25.(3)识别结果不依赖于相关人员的经验。识别准确度大幅度提高;
26.(4)识别准确度大幅度提高;
27.(5)进一步提高了跨站脚本的识别效率。
附图说明
28.图1为一种基于机器学习的跨站脚本攻击识别方法流程图;
29.图2为一种基于机器学习的跨站脚本攻击识别方法数据特征工程流程图。
具体实施方式
30.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
31.实施例1
32.如图1所示,一种基于机器学习的跨站脚本攻击识别方法,包括以下步骤:
33.s1、网页数据收集:搭建含有跨站脚本攻击漏洞的靶场,使用wvs、appscan等扫描
器和人工渗透的方式收集含有跨站脚本攻击的相关数据,对相关数据进行分类标注;相关数据包括请求参数、请求方法、响应内容、响应状态;分类标注包括跨站脚本攻击类和非跨站脚本攻击类;
34.s2、数据特征工程:对相关数据进行数据清洗;如图2所示,包括以下步骤:
35.s21、采用下采样算法将相关数据中包含缺失值的数据清除;
36.s22、使用xpath将响应内容中的标签去除,只保留页面内容;
37.s23、采用urlparse包中的方法将所述请求参数、ip地址、端口号进行区分;
38.s24、使用pearson相关系数评价相关数据的特征变量跟特征之间的关系,去除和最终类别无关的数据;
39.s3、数据特征化分析:将跨站脚本攻击语句视为文本信息,进行文本特征抽取,生成分词信息;
40.s4、机器学习:将分词信息通过xgboost集成算法模型进行训练,得到用于跨站脚本攻击识别的分类器模型;
41.s5、跨站脚本攻击识别:将web请求数据经过特征工程及向量化处理后进入分类器模型进行预测,识别跨站脚本攻击。
42.以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
技术特征:
1.一种基于机器学习的跨站脚本攻击识别方法,其特征在于:包括以下步骤:s1、网页数据收集:搭建含有跨站脚本攻击漏洞的靶场,使用扫描器和人工渗透的方式收集含有跨站脚本攻击的相关数据,对所述相关数据进行分类标注;s2、数据特征工程:对所述相关数据进行数据清洗;s3、数据特征化分析:将跨站脚本攻击语句视为文本信息,进行文本特征抽取,生成分词信息;s4、机器学习:将所述分词信息通过xgboost集成算法模型进行训练,得到用于跨站脚本攻击识别的分类器模型;s5、跨站脚本攻击识别:将web请求数据经过特征工程及向量化处理后进入所述分类器模型进行预测,识别所述跨站脚本攻击。2.根据权利要求1所述的一种基于机器学习的跨站脚本攻击识别方法,其特征在于:所述相关数据包括请求参数、请求方法、响应内容、响应状态。3.根据权利要求1所述的一种基于机器学习的跨站脚本攻击识别方法,其特征在于:所述分类标注包括跨站脚本攻击类和非跨站脚本攻击类。4.根据权利要求1所述的一种基于机器学习的跨站脚本攻击识别方法,其特征在于:所述扫描器为wvs或appscan。5.根据权利要求2所述的一种基于机器学习的跨站脚本攻击识别方法,其特征在于:步骤s2进一步包括以下步骤:s21、采用下采样算法将所述相关数据中包含缺失值的数据清除;s22、使用xpath将所述响应内容中的标签去除,只保留页面内容;s23、采用urlparse包中的方法将所述请求参数、ip地址、端口号进行区分;s24、使用pearson相关系数评价所述相关数据的特征变量跟特征之间的关系,去除和最终类别无关的数据。
技术总结
本发明公开了一种基于机器学习的跨站脚本攻击识别方法,包括以下步骤:S1、网页数据收集:搭建含有跨站脚本攻击漏洞的靶场,使用扫描器和人工渗透的方式收集含有跨站脚本攻击的相关数据,对相关数据进行分类标注;S2、数据特征工程:对相关数据进行数据清洗;S3、数据特征化分析:将跨站脚本攻击语句视为文本信息,进行文本特征抽取,生成分词信息;S4、机器学习:将分词信息通过XGBoost集成算法模型进行训练,得到用于跨站脚本攻击识别的分类器模型;S5、跨站脚本攻击识别:将Web请求数据经过特征工程及向量化处理后进入分类器模型进行预测,识别跨站脚本攻击。本发明能够有效提高跨站脚本攻击识别效率,提高安全性。提高安全性。提高安全性。
技术研发人员:刘兵 谢鑫 何召阳 任玉坤 何晓刚 郗朝旭
受保护的技术使用者:北京墨云科技有限公司
技术研发日:2021.10.14
技术公布日:2022/2/28
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1