基于张量分解的移动基站协作缓存方法
本发明涉及计算机网络,具体涉及基于张量分解的移动基站协作缓存方法。
背景技术:
1、随着移动终端的大规模应用和新应用服务的不断出现,全球移动数据流量出现了爆发式的增长,给现有的移动通信系统带来了挑战。移动数据流量的爆炸性增长严重加重了回程负担,增加了远程服务器到基站的总回程延迟,降低了用户体验率。大多数快速增长的数据流量主要是由用户通过回程链接反复从远程服务器上复制少量流行内容的产生的。为了避免大量重复的数据传输,在网络中引入了边缘缓存技术。用户感兴趣的内容可以直接缓存在靠近用户的基站中,这样可以满足用户的请求,而无需从远程服务器获取内容项目。同时内容缓存距离用户更近,可明显降低移动用户内容请求时延,为用户提供更高质量的网络体验。
2、传统的缓存策略中,每个基站在没有与其他基站协作的情况下存储最流行的文件,这样的缓存策略会导致多个基站缓存内容的冗余以及存储资源的浪费,因此,为了有效地利用有限的存储资源,基站之间的协作缓存便成为了必然趋势。基站之间协作缓存,可以有效利用存储资源,同时可以提高内容的多样性,从而提高缓存命中率,提升用户体验。
3、目前,已知的协作缓存的研究探索了基站合作的缓存设计,以协作传输或内容共享的方式进行合作,制定缓存和交付策略,以提升用户体验质量。但关于协作基站集合如何确定这一问题的研究较少,且这些研究主要基于基站地理位置对基站进行聚类,未兼顾到基站侧的内容访问行为。协作缓存的目的即是卸载流量与优化用户体验,那么在制定内容缓存策略时考虑基站侧的内容访问行为是有必要的。
技术实现思路
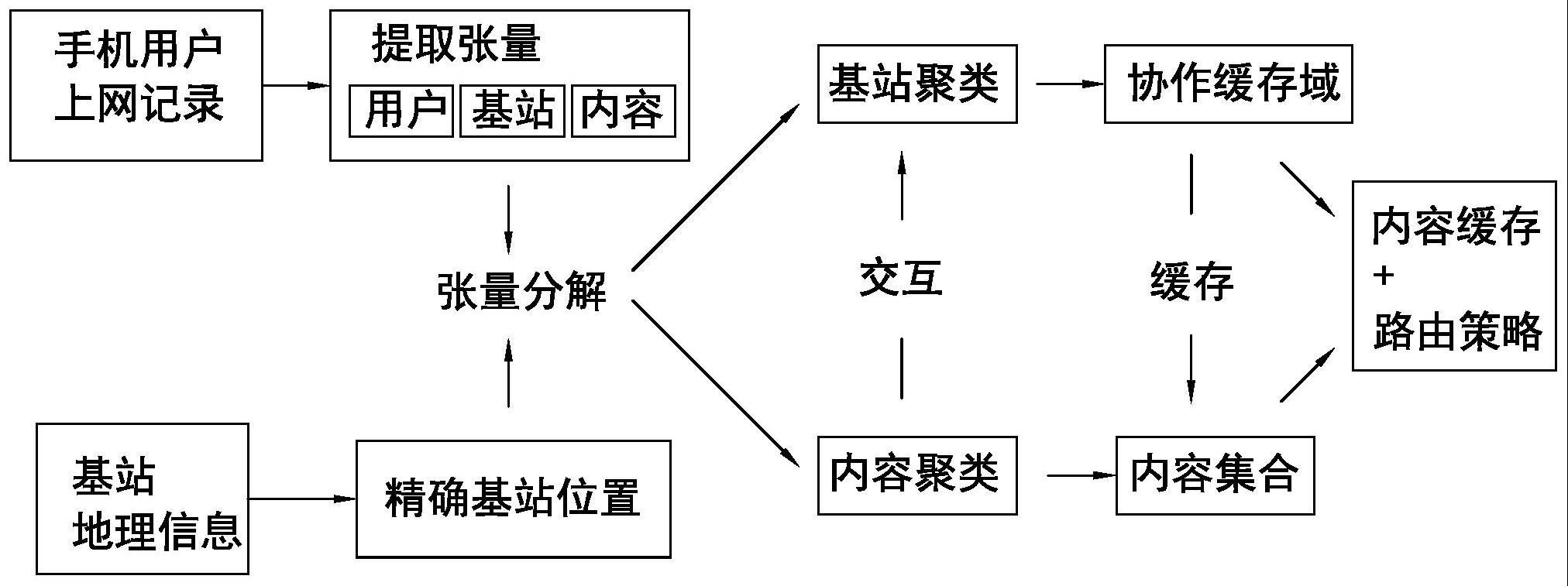
1、本发明的目的在于克服现有技术之不足,提供基于张量分解的移动基站协作缓存方法。针对基站侧内容访问行为规律性,首先对基站、用户、内容记录数据进行张量分解,挖掘基站的社区结构,并且提取协作缓存域和与协同缓存域中基站交互强烈的内容集。然后,综合考虑缓存内容击中率与内容传输代价,优化内容缓存与传输策略,在协作缓存域以及与之交互密切的内容集合上实施分布式协作缓存策略,提升基站缓存资源的利用率,改善用户体验、提升网络性能。
2、本发明解决其技术问题所采用的技术方案是:
3、基于张量分解的移动基站协作缓存方法,其包括以下步骤:
4、步骤(1),从原始数据集中提取内容访问行为,同时获得精确的基站地理分布;
5、步骤(2),对用户、基站、内容三元组构建张量,然后进行tucker分解提取基站、用户、内容的交互关系并进行建模;进一步地,基于内容访问模式进行基站聚类,得到可协作的基站集合以及基站集合与内容的交互关系;;
6、步骤(3),考虑缓存击中率最大化、协作代价最小化目标,将协作缓存问题建模优化,得到最佳缓存策略和内容分发策略。
7、在另一较佳实施例中,所述步骤(1)还包括:对数据集进行初步清洗,删除重复记录,补全或者噪声剔除字段缺失的记录。
8、在另一较佳实施例中,所述步骤(2)的具体过程是:基于用户上网记录提取出的基站b、内容c、用户u记录聚合成三维张量t=[b,u,c]且t∈rm×n×k,其中,t中的元素tmnk代表经由基站bm(1≤m≤m)的用户un(1≤n≤n)访问内容ck(1≤k≤k)的次数,m代表基站b的个数,n代表用户u的个数,k代表内容c的个数;然后进行tucker张量分解;进一步,引入基站的地理距离信息作为正则化信息并将其编码为拉普拉斯矩阵:其中,d(bi,bj)表示基站i和基站j的地理距离。约束条件以修正协方差矩阵的形式融入到张量分解中:c(m)=x(m)x(m)t+μ(m)l(m),其中x(m)是张量x在第m维的矩阵化,c(m)为第m维特征的协方差矩阵,μ(m)代表权重,l(m)为第m维特征的相似度的拉普拉斯矩阵。,该约束的引入使得空间距离较近的基站间的相关性增加;在将多维信息和约束纳入张量分解后,基于基站、内容及其交互作用进行聚类,集群内基站为相似移动用户提供请求内容。
9、在另一较佳实施例中,所述步骤(3)的具体过程是:协作代价定义为基站之间的地理距离:cij=d(bi,bj)=f(dij);;
10、定义每个基站的缓存空间大小为s,m个基站构成p个协作缓存域br(1≤p≤p),bj(1≤j≤m)在其所处协作域内的活跃程度或概率记为wj,所有用户可以访问到的内容的个数为k,内容ck(1≤k≤k)在基站bj上的受欢迎程度为内容放置决策矩阵其中指示在基站bj(1≤j≤m)上是否缓存内容ck(1≤k≤k),1代表内容cf缓存于基站bsj上,0则代表内容cf不缓存基站bsj上;内容分发决策矩阵其中指示当用户向基站bj请求其本地未缓存的内容ck,基站bj是否可以向bi(1≤i≤m,i≠j)请求该内容;
11、建立以缓存击中率最大化、协作代价最小化为优化目标的内容分发模型,并满足五个约束条件:确保如果请求的内容在本地可获得,则该内容请求不会被推送到其他基站;保证本地缓存的内容个数不超过本地缓存容量;确保内容请求推送不发生在相同基站;缓存决策采用0-1整数规划;内容传送决策采用0-1整数规划;定义该优化模型为:
12、
13、
14、约束:
15、
16、
17、
18、
19、
20、本发明的有益效果是:本发明的基于张量分解的移动基站协作缓存方法,为解决移动互联网内容服务请求的爆炸性增长带来的沉重流量负载的问题,采用基于基站、用户、内容数据的张量分解挖掘内容访问模式较为相似且空间距离较近的基站集合以及与之交互较为密切的内容集合,这些基站集合构成协作缓存域以内容共享的方式具备合作关系。然后,综合考虑缓存击中率与协作代价,计算最优化协作式内容缓存与传递策略。本发明提供的方法可以提高缓存资源利用率同时尽可能响应用户内容请求,缓解回程拥塞并提升用户服务质量。
21、以下结合附图及实施例对本发明作进一步详细说明;但本发明的基于张量分解的移动基站协作缓存方法不局限于实施例。
技术特征:
1.基于张量分解的移动基站协作缓存方法,其特征在于:其包括以下步骤:
2.根据权利要求1所述的基于张量分解的移动基站协作缓存方法,其特征在于:所述步骤(1)还包括:对数据集进行初步清洗,删除重复记录,补全或者噪声剔除字段缺失的记录。
3.根据权利要求1所述的基于张量分解的移动基站协作缓存方法,其特征在于:所述步骤(2)的具体过程是:基于用户上网记录提取出的基站b、内容c、用户u记录聚合成三维张量t=[b,u,c]且t∈rm×n×k,其中,t中的元素tmnk代表经由基站bm(1≤m≤m)的用户un(1≤n≤n)访问内容ck(1≤k≤k)的次数,m代表基站b的个数,n代表用户u的个数,k代表内容c的个数;然后进行tucker张量分解;进一步,引入基站的地理距离信息作为正则化信息并将其编码为拉普拉斯矩阵:其中,d(bi,bj)表示基站i和基站j的地理距离。约束条件以修正协方差矩阵的形式融入到张量分解中:c(m)=x(m)x(m)t+μ(m)l(m),其中x(m)是张量x在第m维的矩阵化,c(m)为第m维特征的协方差矩阵,μ(m)代表权重,l(m)为第m维特征的相似度的拉普拉斯矩阵。在将多维信息和约束纳入张量分解后,基于基站、内容及其交互作用进行聚类。集群内基站为相似移动用户提供请求内容。
4.根据权利要求3所述的基于张量分解的移动基站协作缓存方法,其特征在于:所述步骤(3)的具体过程是:协作代价定义为基站之间的地理距离:cij=d(bi,bj)=f(dij);
技术总结
本发明公开了基于张量分解的移动基站协作缓存方法,包括以下步骤:步骤(1),从原始数据集中提取内容访问行为,同时获得精确的基站地理分布;步骤(2),对用户、基站、内容三元组构建张量,然后进行Tucker分解提取基站、用户、内容的交互关系并进行建模;进一步地,基于内容访问模式进行基站聚类,得到可协作的基站集合以及基站集合与内容的交互关系;步骤(3),考虑缓存击中率最大化、协作代价最小化目标,将协作缓存问题建模优化,得到最佳缓存策略和内容分发策略。本发明提供的基站协作缓存方法能提升基站缓存资源的利用率,改善用户体验、提升网络性能。
技术研发人员:章余,杨林涛,胡记伟,熊云飞,高鹏,徐萍
受保护的技术使用者:华中师范大学
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!