本发明涉及到计算机数据安全和密码学领域,尤其涉及一种用于自然语言处理的深度学习模型的同态加密方法。
背景技术:
1、基于深度学习的自然语言处理提供的服务已经越来越普遍,基于自然语言、大数据的推荐、识别等服务给用户带来了更大的便利。与此同时,用户提交的数据的过程可能会导致用户牺牲了自己的隐私信息。为了在保护用户隐私的前提下保持服务商提供服务的能力,在隐私计算的研究领域内已有一些处于研究之中的技术。需要说明的是,隐私计算不是一个单一的技术,相反,是一门融合了密码学、人工智能、计算机科学乃至安全硬件的跨学科交叉领域。目前被广泛研究的技术方向包括:多方安全计算、联邦学习和可信执行环境技术、差分隐私和同态加密。
2、其一是以多方安全计算(smpc或mpc:secure multi-party computation)技术为代表的纯基于密码学的技术;其二是以联邦学习(federated learning)为代表的人工智能和密码学融合的技术;第三类是以可信执行环境(tee:trusted execution environment)为基础的基于可信硬件的技术。同时,除了罗列的三大技术方向,诸如同态加密、差分隐私等技术也被广泛采用,或融入上述方向中作为方案的一部分,或被独立来用。值得一提的是,这几类技术并不互斥,在实现业务目标时往往根据场景特定,按需使用,甚至协同使用。隐私计算技术主要对比如下。
3、多方安全计算和全同态加密算法对安全性有较高的保障,但是相对应的需要巨大的工程改造,而且在计算和存储性能方面也会造成非常显著的下降,导致在实用中难以落地。可信执行环境通常需要使用特有的硬件系统来实现,虽然安全性和计算性能都比较优越,但是使用的场景受到较大限制。差分隐私技术和联邦学习技术在安全性和计算性能上做了一定的折中妥协,但总体而言,计算速度性能和准确度仍然有一定下降。
4、总体而言,这些算法有的虽然对安全性有较高的保障,但是会造成存储的巨大膨胀,也会造成计算性能的显著下降。有的虽然在计算速度方面仍然有竞争力,但是需要巨大的工程改造,对传输和深度学习计算过程进行全面重开发,而深度学习的准确率也会下降。
技术实现思路
1、针对现有技术的不足,本发明提供一种用于自然语言处理的深度学习模型的同态加密方法,该加密方法在计算性能上十分优越,可以完成毫秒级别的加密和解密,也不会影响基于深度学习模型的速度。
2、一种用于自然语言处理的深度学习模型的同态加密方法,包含以下步骤:
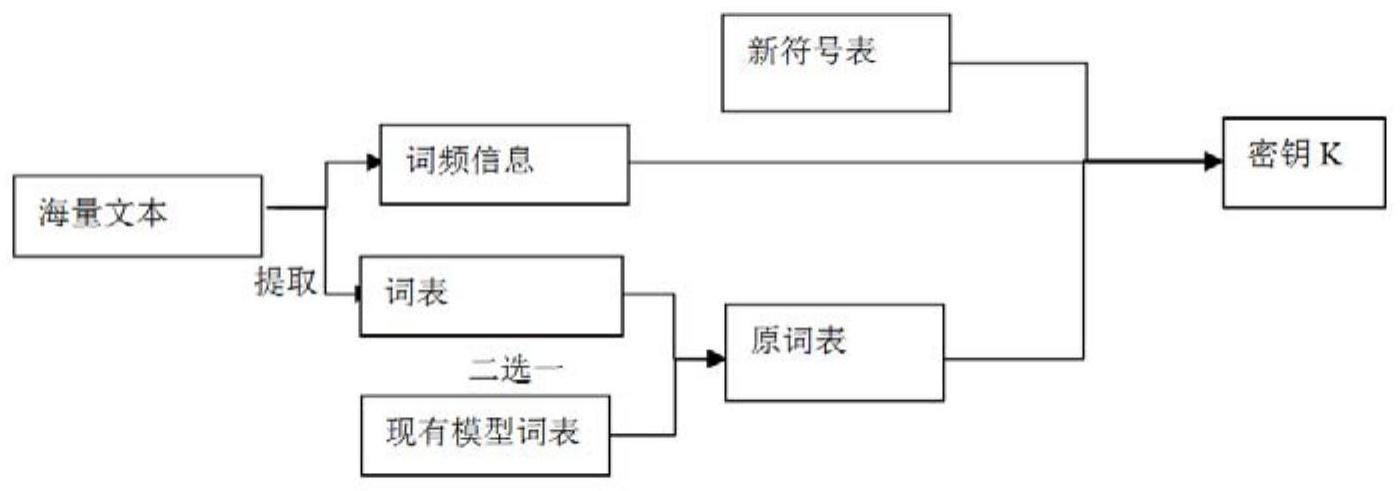
3、步骤一:密钥生成;
4、根据需要加密的数据或者需要使用的深度学习模型获得原始符号表;根据所述原始符号表生成一份不包含重复符号的随机符号表,所述随机符号表的大小不小于所述原始符号表,且所述原始符号表中的符号与所述随机符号表中的符号形成一对一或一对多的映射关系;所述随机符号表作为密钥k;
5、步骤二:数据加密;
6、步骤(2.1):通过分词算法将一份明文数据分成符号串;
7、步骤(2.2):将所述符号串中的符号按照所述密钥k,从原符号映射成新符号;其中,如果映射关系是一对一的映射,则直接映射到新符号;如果映射关系是一对多的,则从原符号映射到的多个符号中,随机选取一个符号作为新符号;
8、步骤(2.3):将所述新符号串联,生成利用密钥k加密后的密文m。
9、进一步地,根据所述原始符号表生成一份不包含重复符号的随机符号表,具体包括:
10、将所述将原始符号表随机打乱顺序,生成一份随机符号表;此时,所述原始符号表中的符号与随机符号表中的符号形成一对一的映射关系;
11、或者,选取一份大小不小于所述原始符号表的全新的符号表,随机打乱顺序,生成一份随机符号表。
12、进一步地,将所述将原始符号表随机打乱顺序,生成一份随机符号表,具体包括:
13、选取原始符号表中的部分符号打乱顺序,剩余的保持原样,生成随机符号表;
14、或者,将整个原始符号表打乱顺序,生成一份随机符号表。
15、进一步地,选取的新符号表的大小大于原始符号表时,形成一对多的映射;此时,统计语料中符号出现的频率,中高频的符号优先映射成多个新符号,使得最终的映射结果中各个符号出现的频率相对平均,无法出现频率分析攻击。
16、进一步地,当新符号表大于原符号表,形成一对多的映射时,在每次加密的过程中加入随机种子数s,从而使一对多映射的过程都由哈希函数h(s)决定,从而使得加密结果的完整性由s得到验证。
17、进一步地,在获得原始符号表时,若希望将加密后的密文m应用在已训练好的深度学习模型上时,则获取已有的深度学习模型的词汇表,并去除分词算法自动添加的符号后,生成所述原始符号表;若希望将加密后的密文m应用在未训练的深度学习模型上,则直接利用加密数据的全量词汇表生成所述原始符号表。
18、进一步地,所述分词算法选用基于字的分词算法。
19、进一步地,所述分词算法选用基于单词的分词算法。
20、一种由加密方法生成的密文在深度学习模型训练中的应用,包括:
21、(1)将深度学习模型的符号编码表中的每个符号按照密钥k的映射规则映射成加密的符号;
22、(2)利用所述密文m对所述深度学习模型进行训练或预测。
23、进一步地,将所述深度学习模型的符号编码表中的每个符号按照密钥k的映射规则映射成加密的符号后,在符号查找表中对向量进行扰动,提高密文的安全性。
24、本发明的有益效果如下:
25、(1)本发明的加密算法不需要更改深度学习模型的结构和计算逻辑,因此,没有额外计算开销,也不会损失模型精度。
26、(2)本发明的加密算法简介明了,易于实现,不受开发语言和开发框架的限制,适用性强。
27、(3)本发明的加密算法的数据加密效率高,能达到0.3毫秒量级,更易于部署于线上环境。
28、(4)当映射关系为一对多时,本发明还提供了增加随机性和加密校验的选择,可以验证加密文本的完整性,同时可以应对频率分析类的攻击。
技术特征:1.一种用于自然语言处理的深度学习模型的同态加密方法,其特征在于,包含以下步骤:
2.根据权利要求1所述的用于自然语言处理的深度学习模型的同态加密方法,其特征在于,根据所述原始符号表生成一份不包含重复符号的随机符号表,具体包括:
3.根据权利要求2所述的用于自然语言处理的深度学习模型的同态加密方法,其特征在于,将所述将原始符号表随机打乱顺序,生成一份随机符号表,具体包括:
4.根据权利要求2所述的用于自然语言处理的深度学习模型的同态加密方法,其特征在于,选取的新符号表的大小大于原始符号表时,形成一对多的映射;此时,统计语料中符号出现的频率,中高频的符号优先映射成多个新符号,使得最终的映射结果中各个符号出现的频率相对平均,无法出现频率分析攻击。
5.根据权利要求2所述的用于自然语言处理的深度学习模型的同态加密方法,其特征在于,当新符号表大于原符号表,形成一对多的映射时,在每次加密的过程中加入随机种子数s,从而使一对多映射的过程都由哈希函数h(s)决定,从而使得加密结果的完整性由s得到验证。
6.根据权利要求1所述的用于自然语言处理的深度学习模型的同态加密方法,其特征在于,在获得原始符号表时,若希望将加密后的密文m应用在已训练好的深度学习模型上时,则获取已有的深度学习模型的词汇表,并去除分词算法自动添加的符号后,生成所述原始符号表;若希望将加密后的密文m应用在未训练的深度学习模型上,则直接利用加密数据的全量词汇表生成所述原始符号表。
7.根据权利要求1所述的用于自然语言处理的深度学习模型的同态加密方法,其特征在于,所述分词算法选用基于字的分词算法。
8.根据权利要求1所述的用于自然语言处理的深度学习模型的同态加密方法,其特征在于,所述分词算法选用基于单词的分词算法。
9.一种由权利要求1所述的加密方法生成的密文在深度学习模型训练中的应用,其特征在于,包括:
10.根据权利要求9所述的应用,其特征在于,将所述深度学习模型的符号编码表中的每个符号按照密钥k的映射规则映射成加密的符号后,在符号查找表中对向量进行扰动,提高密文的安全性。
技术总结本发明公开一种用于自然语言处理的深度学习模型的同态加密方法,首先根据需要加密的数据或者需要使用的深度学习模型获得原始符号表;根据原始符号表生成一份不包含重复符号且大小不小于原始符号表的随机符号表,原始符号表中的符号与随机符号表中的符号形成一对一或一对多的映射关系;随机符号表作为密钥K;通过分词算法将深度学习模型对应的一份明文数据分成符号串;将符号串中的符号按照密钥K,映射成新符号,并串联,生成利用密钥K加密后的密文m。采用本发明的方法进行加密,产出的密文在深度学习中可以保持计算同态,也就是说深度学习模型可以基于密文训练和预测,不影响训练的计算效率,也不改变预测结果,不改变准确率和召回率效果。
技术研发人员:陈圆谜,黄程韦,朱晓明,阚保春,魏伟,郑海天,刘海丰
受保护的技术使用者:之江实验室
技术研发日:技术公布日:2024/1/11