一种视频数据处理的方法和系统与流程
本发明涉及一种数据处理方法,尤其涉及一种视频数据处理的方法和系统。
背景技术:
1、随着计算机技术的发展,视频在日常消费生活中得到了广泛的应用,例如短视频平台\直播带货\网上教育等场景都需要视频方式传播。录制视频慢慢成为人们社交和传递信息的手段,与之相应的,视频录制后的后期处理也成为必不可少的工作。
2、但视频的录制和制作是一项很耗时的工作,通常还需要特定的录制环境,还有专业的录制设备,在这种情况如果出现一些录制错误,或者需要修订一些台词,就需要重新录制视频片段,不仅耗时耗力,还要考虑新录制的视频和原视频的剪接问题。同样,在电影拍摄的过程中,也会遇到上述问题。由于拍摄的设备更加专业,配合拍摄的人员更多,录制视频的成本也会更高。除此以外,电影译制片、方言电影的普通话配音版制作等情形,也会遇到配音和唇形不一致的问题。这时候,有必要提供一种技术,能够根据音频修改人物嘴型、生成音频和嘴型一致的视频,从而能够极大地提高工作效率,降低视频制作成本,并让观众获得更好的观赏体验。
技术实现思路
1、本发明提供了一种视频数据处理方法和系统,能够解决视频录制或电影拍摄后期无法根据用户需求高效、简洁地调整视频内人物嘴型,使之与音频匹配的问题。
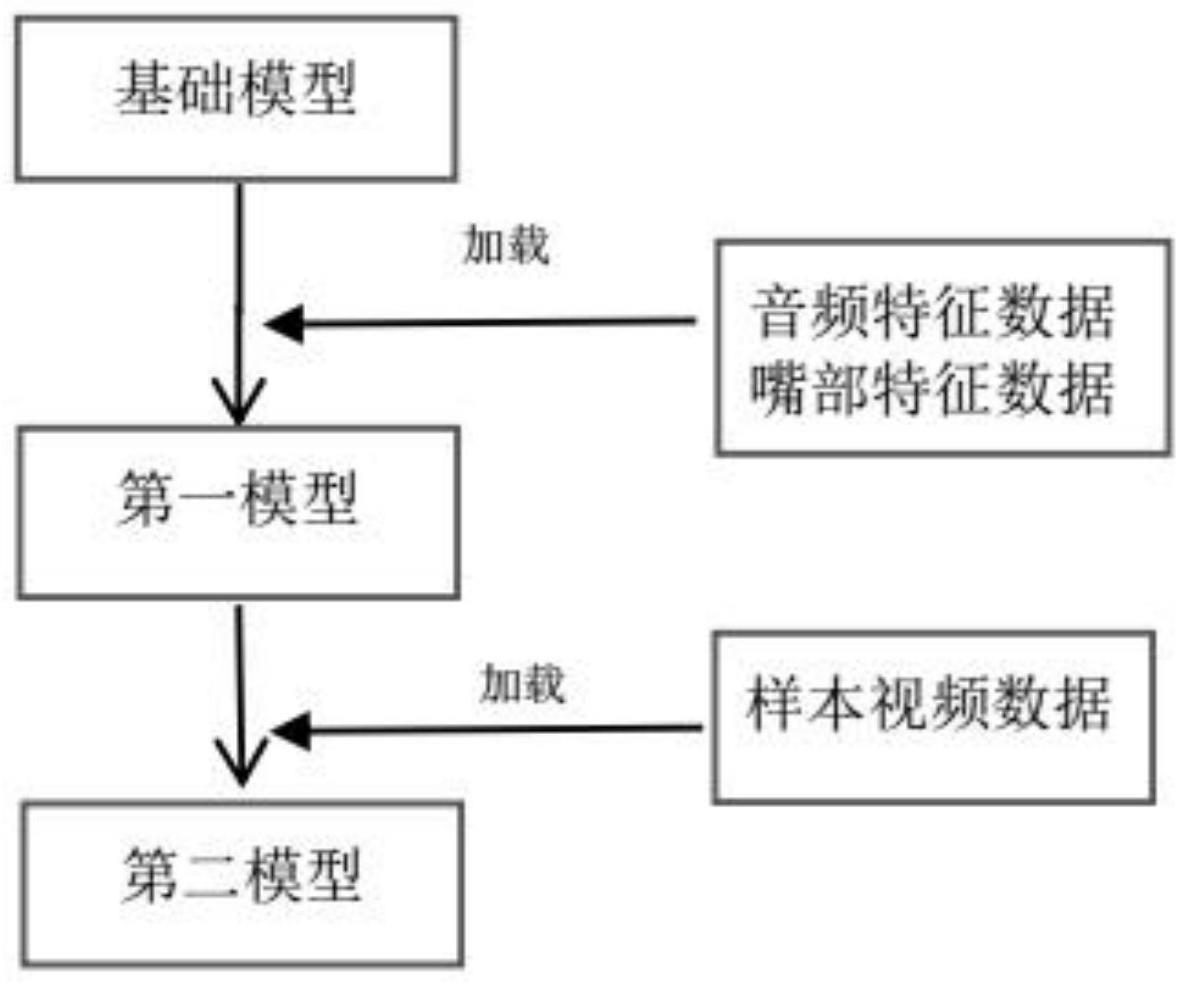
2、一方面,本发明提供了一种视频数据处理方法,包括:
3、获取用于基础模型训练的基础视频数据;
4、针对所述基础视频数据进行数据预处理;所述数据预处理包括提取音频特征和提取人脸数据,从而获得音频特征数据和嘴部特征数据;
5、通过所述音频特征数据和所述嘴部特征数据对所述基础模型进行基础训练,生成第一模型;
6、获取用于第一模型训练的样本视频数据,通过所述样本视频数据对所述第一模型进行微调训练,生成第二模型;
7、根据待处理音频和所述第二模型,生成与所述待处理音频对应的目标嘴部数据;
8、根据所述目标嘴部数据和待处理视频数据,生成目标视频数据。
9、可选地,所述基础视频数据要求所述基础视频数据完整露出嘴部,所述嘴部与所述基础视频数据的音频同步,所述基础视频足够清晰。
10、可选地,所述提取音频特征是指能够提取到语义信息的特征。
11、可选地,所述提取音频特征是指提取所述基础视频数据的语音识别特征作为数据预处理后的音频特征。
12、可选地,所述提取人脸数据,是指先截取视频中的人脸区域作为基础图片,然后对所述基础图片的嘴部区域进行处理作为嘴部特征数据。
13、可选地,所述通过所述音频特征数据和所述嘴部特征数据对所述基础模型进行基础训练,是指用所述音频特征数据和所述嘴部特征数据作为模型输入,用所述基础图片作为输出,对所述基础模型进行训练。
14、可选地,所述生成目标视频数据,是指根据所述目标嘴部数据修正待处理视频数据的相应部分,从而生成所述目标视频数据。
15、可选地,对所述样本视频数据进行数据预处理,获得第二音频特征数据和第二嘴部特征数据,通过所述第二音频特征数据和所述第二嘴部特征数据对所述第一模型进行微调训练。
16、可选地,针对所述目标嘴部数据进行融合处理。
17、另一方面,本发明提供了一种视频数据处理系统,包括:
18、视频获取模块,获取用于基础模型训练的基础视频数据;
19、数据预处理模块,针对所述基础视频数据进行数据预处理;所述数据预处理包括提取音频特征和提取人脸数据,从而获得音频特征数据和嘴部特征数据;
20、第一训练模块,通过所述音频特征数据和所述嘴部特征数据对所述基础模型进行基础训练,生成第一模型;
21、第二训练模块,获取用于第一模型训练的样本视频数据,通过所述样本视频数据对所述第一模型进行微调训练,生成第二模型;
22、视频生成模块,根据待处理音频和所述第二模型,生成与所述待处理音频对应的目标嘴部数据;
23、视频输出模块,根据所述目标嘴部数据和待处理视频数据,输出目标视频数据。
24、上述技术方案中的优点或有益效果至少包括:
25、本发明是根据音频修改视频嘴部数据的技术,能够广泛应用于电影、短视频等场景。在视频拍摄完成后,花费很小的成本通过音频重新生成嘴型,避免重新拍摄耗费大量成本。同样,本发明也能用于译制电影、方言电影等的配音制作,能够根据音频生成和配音相匹配的嘴型,提高观赏体验。
26、本发明能应用在所有设计口型的视频创作领域,比如电影拍摄、新闻的广播、自媒体视频创作、电影译制、动画片制作等领域。在电影的拍摄中,经常会出现需要修改台词、增加台词的情况,而往往电影剪辑的时候已经完成了拍摄工作,这时候再进行增加拍摄,往往要很大的成本,更多的时候由于环境的变换、场景的破坏,甚至难以再次进行拍摄。
27、这个时候本发明就是很合适的解决方案,只需要裁剪一分钟特定演员的视频进行微调训练,就能够任意改动该演员的口型,使其和修改后的台词准确对应。甚至能够根据新台词直接生成视频,增加更大剧情。这样极大地降低了成本,艺术创作者也有了更大的创作空间。
28、当前社会越来越涌现出了很多视频自媒体,其拍摄过程和电影类似,但是要求比电影更低的拍摄成本,更自由的拍摄环境,类似于电影,这也是该发明很好的应用场景。
29、上述概述仅仅是为了说明书的目的,并不意图以任何方式进行限制。除上述描述的示意性的方面、实施方式和特征之外,通过参考附图和以下的详细描述,本发明进一步的方面、实施方式和特征将会是容易明白的。
技术特征:
1.一种视频数据处理的方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述基础视频数据要求所述基础视频数据完整露出嘴部,所述嘴部与所述基础视频数据的音频同步,所述基础视频足够清晰。
3.根据权利要求1所述的方法,其特征在于,所述提取音频特征是指能够提取到语义信息的特征。
4.根据权利要求1所述的方法,其特征在于,所述提取音频特征是指提取所述基础视频数据的语音识别特征作为数据预处理后的音频特征。
5.根据权利要求1所述的方法,其特征在于,所述提取人脸数据,是指先截取视频中的人脸区域作为基础图片,然后对所述基础图片的嘴部区域进行处理作为嘴部特征数据。
6.根据权利要求5所述的方法,其特征在于,所述通过所述音频特征数据和所述嘴部特征数据对所述基础模型进行基础训练,是指用所述音频特征数据和所述嘴部特征数据作为模型输入,用所述基础图片作为输出,对所述基础模型进行训练。
7.根据权利要求1所述的方法,其特征在于,所述生成目标视频数据,是指根据所述目标嘴部数据修正待处理视频数据的相应部分,从而生成所述目标视频数据。
8.根据权利要求1所述的方法,其特征在于,对所述样本视频数据进行数据预处理,获得第二音频特征数据和第二嘴部特征数据,通过所述第二音频特征数据和所述第二嘴部特征数据对所述第一模型进行微调训练。
9.根据权利要求1所述的方法,其特征在于,针对所述目标嘴部数据进行融合处理。
10.一种视频数据处理的系统,其特征在于,所述系统包括:
技术总结
本发明提出一种视频数据处理的方法,该方法包括获取用于基础模型训练的基础视频数据;针对所述基础视频数据进行数据预处理;通过预处理的视频数据对所述基础模型进行基础训练,生成第一模型;通过样本视频数据对所述第一模型进行微调训练,生成第二模型;根据待处理音频和所述第二模型,生成与所述待处理音频对应的目标嘴部数据;根据所述目标嘴部数据和待处理视频数据,输出目标视频数据。本发明还提出了相应的系统。本发明提供的方法及系统,解决了现有的视频录制错误不易更正的问题,能够花费很小的成本通过音频重新生成嘴型,避免重新拍摄耗费大量成本,提高观赏体验。
技术研发人员:司马华鹏,王培雨
受保护的技术使用者:南京硅基智能科技有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!