基于深度强化学习的智能建筑网络任务调度优化算法
本发明涉及智能建筑,具体为基于深度强化学习的智能建筑网络任务调度优化算法。
背景技术:
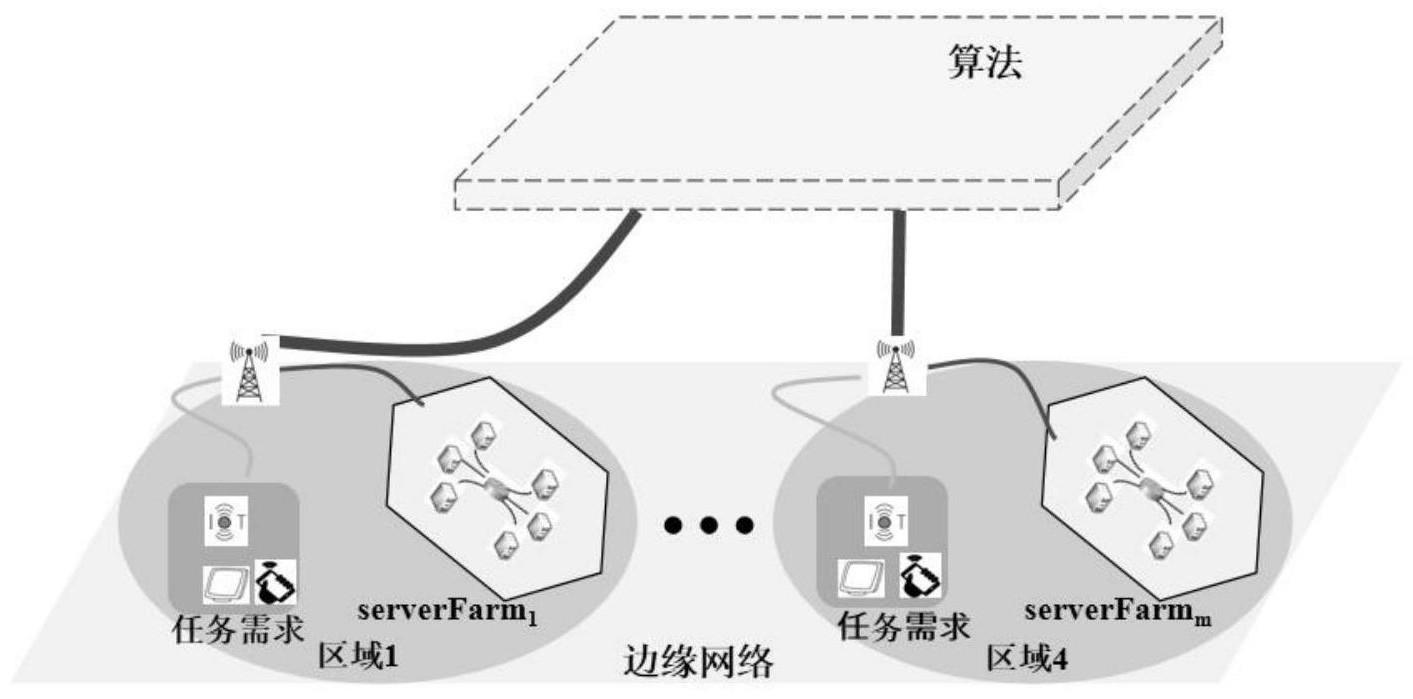
1、智能建筑是通过人工智能和物联网技术,根据用户需求,将建筑物的结构、系统、服务和管理有机地结合起来,为用户提供绿色、高效、舒适、方便的人性化建筑环境。而随着先进通信技术和新型物联网(iot)系统的快速发展,智能建筑网络往往会产生具有关联性的任务,同时对计算量和时延的需求越来越高。这时,如何实时调度任务并分配适当的边缘资源,同时共同考虑它们的关联性,以降低时延和能耗,提高调度成功率已成为一个热点问题。
2、传统的大多数边缘任务调度和资源分配解决方案都基于集中式架构,它们依赖于全局任务调度和分配中心来发现边缘资源、处理卸载请求、调度任务和分配资源。然而,这种集中式架构存在单点故障(spof)的问题,当面临大量卸载请求时,容易因为优化爆炸问题而导致调度效率和实时性低下。
3、近年来,很多专家学者对分布式架构的任务调度方法进行了研究。像短任务优先调度、时间片轮转调度(rr)、先来先服务调度(fcfs)等传统方法以及基于模糊逻辑、神经网络、遗传算法等人工智能算法,很大程度上改善了任务调度的服务质量和服务效率。但这些方法,大多对任务调度进行了简化,比较适合任务模式、运行环境比较固定的静态环境,对于动态变化比较大的环境不太适合。
4、针对状态变化频繁、不易建模的动态系统,强化学习(reinforcement learning,rl)基于它无模型的优势能够很好地通过学习过去的调度策略来适应计算任务卸载中复杂、时变的网络,逐渐成为一类热门的解决方法。近年来结合强化学习算法优化卸载策略的研究逐渐增加。而q-learning作为强化学习的经典算法受学者的喜爱。但在具体应用过程中,也存在着多任务调度过程中动作空间和状态空间规模过大的问题,导致任务调度成功率低,系统整体的时延和能耗高。
技术实现思路
1、本发明的目的在于提供基于深度强化学习的智能建筑网络任务调度优化算法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:基于深度强化学习的智能建筑网络任务调度优化算法,包括以下步骤:
3、s1:将用户负载设为任务集合t,并将用户负载视为由多个有向无环图dag组成,以记录任务之间的关系,并以此处理大量用户请求作为输入;
4、s2:将智能建筑网络中关联性任务调度优化问题建模为一个马尔科夫决策过程模型,对其中的状态空间、动作空间及立即奖赏函数进行建模,其中,采用两阶段的ddqn深度强化学习算法求解最优调整方案;
5、s3:输出总的能耗、时延和任务调度成功率。
6、所述步骤s2包括以下步骤:
7、s21:利用处理器进行第一步选择:根据当前环境资源状态信息选择服务器场;
8、s22:进行第二步选择:根据第一步所选择的服务器场中的资源状态信息和任务信息来选择服务器和虚拟机;
9、所述步骤s2中的状态空间定义了主体可能感知的状态范围,在两阶段的ddqn决策过程中,每个阶段的ddqn将从环境中获取当前状态信息和任务信息作为输入。
10、步骤s21中的服务器场的动作空间表示为:astage1={serverfarm1,serverfarm2,......,serverfarm10}。
11、步骤s22中的服务器场的动作空间表示为:
12、步骤s21中的立即奖赏函数表示为:r1=p[tn,pwrf(tn-1)-pwrf(tn)],步骤s22中的立即奖赏函数表示为:r2=p[tn,pwem(tn-1)-pwrm(tn)],其中,tn表示当前时间,pwrf(t)表示在时间t内场内服务器的总功率,owrm(t)表示单个服务器在时间t上的功率。
13、与现有技术相比,本发明的有益效果是:
14、本基于深度强化学习的智能建筑网络任务调度优化算法,能够考虑智能建筑网络任务之间的关联性,通过有向无环图dag和两阶段的ddqn处理器来实现最合理的任务调度,以提高任务调度成功率,减少系统整体的时延和能耗。
技术特征:
1.基于深度强化学习的智能建筑网络任务调度优化算法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于深度强化学习的智能建筑网络任务调度优化算法,其特征在于:所述步骤s2包括以下步骤:
3.根据权利要求2所述的基于深度强化学习的智能建筑网络任务调度优化算法,其特征在于:所述步骤s2中的状态空间定义了主体可能感知的状态范围,在两阶段的ddqn决策过程中,每个阶段的ddqn将从环境中获取当前状态信息和任务信息作为输入。
4.根据权利要求2所述的基于深度强化学习的智能建筑网络任务调度优化算法,其特征在于:步骤s21中的服务器场的动作空间表示为:astage1={serverfarm1,serverfarm2,......,serverfarm10}。
5.根据权利要求2所述的基于深度强化学习的智能建筑网络任务调度优化算法,其特征在于:步骤s22中的服务器场的动作空间表示为:
6.根据权利要求1所述的基于深度强化学习的智能建筑网络任务调度优化算法,其特征在于:步骤s21中的立即奖赏函数表示为:r1=p[tn,pwrf(tn-1)-pwrf(tn),步骤s22中的立即奖赏函数表示为:r2=p(tn,pwrm(tn-1)-pwrm(tn)],其中,tn表示当前时间,pwrf(t)表示在时间t内场内服务器的总功率,pwrm(t)表示单个服务器在时间t上的功率。
技术总结
本发明公开了基于深度强化学习的智能建筑网络任务调度优化算法,包括以下步骤:S1:将用户负载设为任务集合T,并将用户负载视为由多个有向无环图DAG组成,以记录任务之间的关系,并以此处理大量用户请求作为输入;S2:将智能建筑网络中关联性任务调度优化问题建模为一个马尔科夫决策过程模型,对其中的状态空间、动作空间及立即奖赏函数进行建模,其中,采用两阶段的DDQN深度强化学习算法求解最优调整方案;S3:输出总的能耗、时延和任务调度成功率。本发明能够考虑智能建筑网络任务之间的关联性,通过有向无环图DAG和两阶段的DDQN处理器来实现最合理的任务调度,以提高任务调度成功率,减少系统整体的时延和能耗。
技术研发人员:陆悠,陈宇豪,张哲,许犇,傅启明,王蕴哲,陈建平
受保护的技术使用者:苏州科技大学
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!