一种面向众包的强化协同训练室内定位方法与流程
本发明属于室内定位,具体的说是涉及一种面向众包的强化协同训练室内定位方法。
背景技术:
1、随着近些年智能终端和物联网的发展,室内的定位信息可以为用户提供更多个性化的服务,相关研究得到的越来越多的关注。基于无线信号rssi的指纹室内定位技术,更是由于其不受限于多径效应和非视距遮挡等优点被广泛的关注。基于信号强度rssi的指纹室内定位技术通常需要事先构建带标签的指纹数据库,需要对环境划分网格后并对采集到的rssi指纹信息人工打上标签,这一过程需要花费的时间成本和人力成本是巨大的。随着半监督和无监督技术的发展,人们尝试用少量的带标签数据配合大量众包无标签数据构建指纹数据库。文献“zhou z h,li m.semi-supervised regression with co-training[c]ijcai-05,proceedings of the nineteenth international joint conference onartificial intelligence,edinburgh,scotland,uk,july 30-august 5,2005.morgankaufmann publishers inc.2005”中的协同训练就是一种使用广泛的半监督学习方法,该方法通过在数据中建立两个不同的分类器,利用两个分类器来“互补”地为无标签数据打上标签从而实现标签数据库的扩展构建。
2、协同训练模型中,每一轮迭代需要为无标签数据打上标签并将对应样本放入带标签集合中以至进一步训练两个分类器。为了保证后加入数据的标签可靠性,不同的协同训练算法会按照不同的策略来计算出置信度最高的样本并加入数据集。大多算法都面临以下问题:
3、1)训练迭代过程中,每次都按照固定的计算策略选择置信度较高的样本,这种训练可能造成模型的“短视”。与当前模型更好匹配的数据集更有机会被选中,最后导致模型陷入局部最优解,而不能扩大到完整的样本空间。
4、2)带标签的数据集和众包得到的无标签数据集在数据分布上是存在一定差异的,忽略这种差异在迭代一段时间后,模型可能会向无标签数据偏移,偏差的累计导致最终模型的性能下降。
技术实现思路
1、本发明针对协同训练算法构建指纹数据库每轮迭代选择候选数据集时面临的:按照固定策略选择数据造成模型局部最优解、忽略标签数据与众包数据在分布上的差异带来的模型性能问题。
2、在dqn强化学习算法中,强化学习的机制是训练一个q智能体(q-agent)。智能体通过观察当下的环境(state)选择离散动作中的某一个动作(action)得到奖赏系统反馈的奖励值(reward)。模型在奖赏函数的指引下希望每一步能做出正确的动作,以获得更高的全局奖励。强化学习通常被应用于决策问题,因为其不断与环境互动的特性让其具有以下优点:1)在dqn算法中,有相关的环境探索机制防止模型陷入局部最优解;2)dqn算法不仅仅关注于眼下获取的奖励,更能获得全局的高奖励。
3、本发明设计了一种面向众包的强化协同训练室内定位方法,在传统协同训练中引入强化学习,将每次迭代中对候选数据集的选择过程建模成一个连续决策问题。定义选取数据加入指纹库后带来的定位效果提升作为激励,模型在反复的与环境的互动中对数据分布有整体的感知。相比于传统算法中按照固定的计算策略来评估候选数据的置信度,本发明的方法能对数据空间有更完备的感知,能做出更符合长远利益的决策,最终会取得更好的模型效果。
4、本发明的技术方案是:
5、一种面向众包的强化协同训练室内定位方法,包括以下步骤:
6、s1、在目标定位环境采集带标签的指纹数据集l,通过众包的方式采集无标签的指纹数据集u,其中l<u;从l中选择出测试集t;
7、s2、训练决策网络,具体包括:
8、s21、构建分类器,分类器的输入为指纹数据,输出为估计的坐标值;
9、s22、采用l的数据初步训练分类器,得到用于定位模型;
10、s23、利用定位模型为无标签的指纹数据打上标签得到候选样本,将候选样本分为n组得到k组候选集:k=[k1,k2…kn],将每一组候选集中第一个被划分进的候选样本定义为质心si;
11、s24、构建dqn网络,dqn网络的输入为当前观测到的状态st,该状态表示一个候选集分组中的质心在分类器分类结果中的置信度:
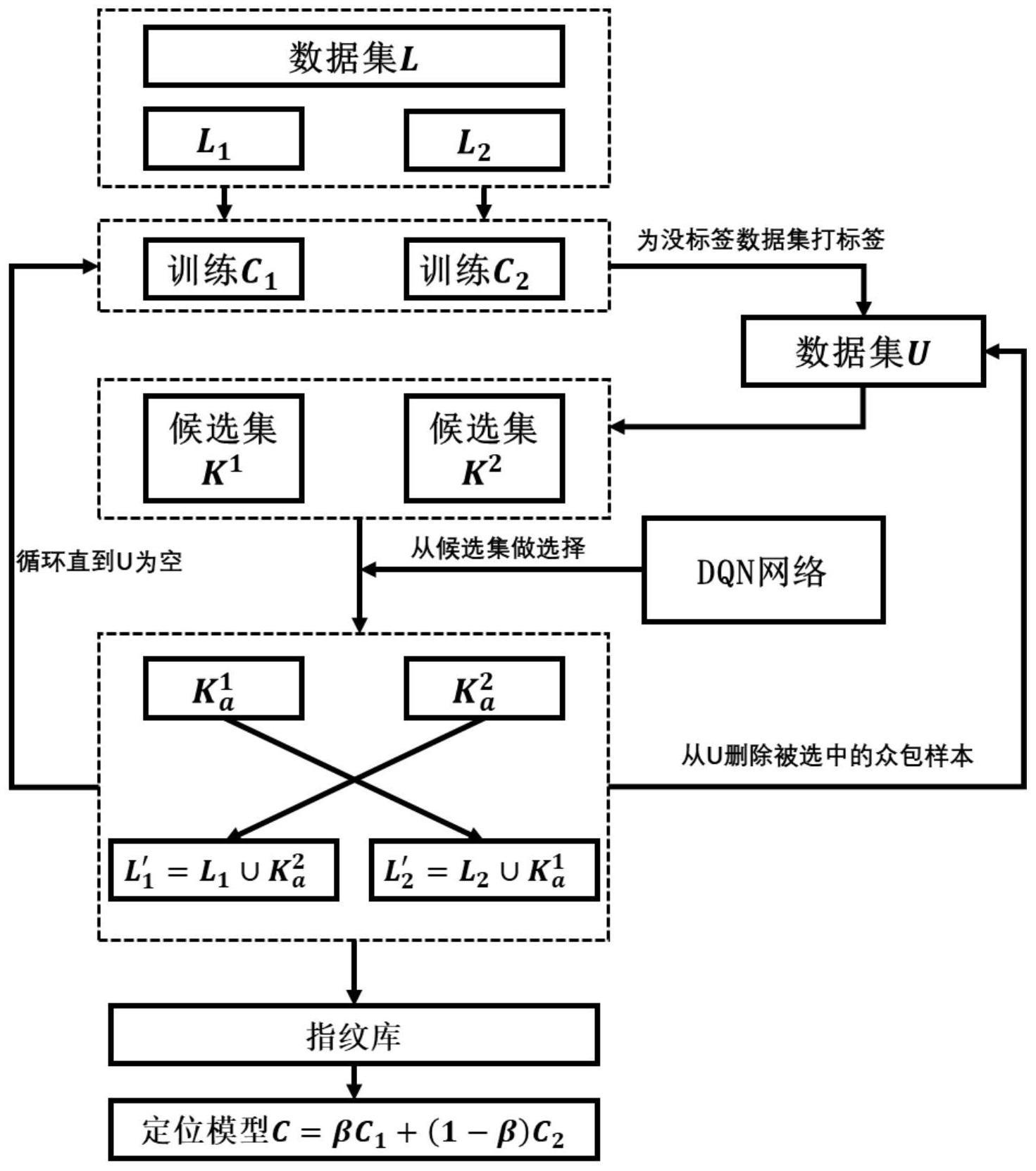
12、st=[p1,p2,p3…pn]t
13、dqn网络的输出为1×n的向量,表示选择每个分组得到的q值,根据输出选择q最大的编号,作为此轮决策的动作at,其对应的批次的候选集作为加入指纹库的候选集
14、s25、用分类器c在测试集t中完成一轮测试,并记录下分类器的定位精度accc(t);用l′完成分类器的更新得到c′并得到accc′(t),dqn网络每一次决策的奖赏值定义为:
15、rt=accc′(t)-accc(t)
16、s26、根据[st,at,rt]完成dqn网络的更新,l=l′,c=c′;
17、s27、回到步骤s22,直到模型收敛,训练完成;
18、s3、通过协同训练得到指纹数据库以及最终的定位模型,具体为:
19、s31、将l随机划分为l1和l2,并构建两个参数不同的分类器c1和c2;
20、s32、从u中随机选择设定量的样本构建u′,同时从u中删除u′;
21、s33、采用步骤s21-s23的方法,通过l1和l2分别训练c1和c2,然后对u′中的样本分别用c1和c2完成定位生成两个候选集candi1和candi2,并各自分成n组子集
22、s34、利用训练好的dqn网络,从两个候选集中各自选出子集和随后加入对方的带标签数据库中:
23、s35、重复执行s32,直至u为空,完成指纹数据库的构建;
24、s36、通过加权两个分类器得到最终的定位模型c=βc1+(1-β)c2,β是加权系数;
25、s4、利用得到的指纹数据库和最终的定位模型,得到定位分类器进行室内定位。
26、本发明的有益效果是:本发明提出在协同训练中引入强化学习作为候选集样本选择的策略工具,因为dqn算法是一种离线策略算法,需要先对dqn网络进行训练再用于候选集样本的选择。dqn算法通过与环境的充分互动探索可以让网络对数据空间有整体的感知,这种策略相比于传统的固定策略更能防止局部最优解的情况发生。
技术特征:
1.一种面向众包的强化协同训练室内定位方法,其特征在于,包括以下步骤:
技术总结
本发明属于室内定位技术领域,具体的说是涉及一种面向众包的强化协同训练室内定位方法。本发明提出在协同训练中引入强化学习作为候选集样本选择的策略工具,因为DQN算法是一种离线策略算法,需要先对DQN网络进行训练再用于候选集样本的选择。DQN算法通过与环境的充分互动探索可以让网络对数据空间有整体的感知,这种策略相比于传统的固定策略更能防止局部最优解的情况发生。
技术研发人员:郭贤生,张明恒,段林甫,司皓楠,钱博诚,纪文静
受保护的技术使用者:四川混构定位科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!