一种智能相框设备
本发明涉及智能相框,尤其涉及一种智能相框设备。
背景技术:
1、生活中总是存在一些可望而不可得的东西。比如亲人离去后,进门后听不到亲人打招呼的声音了。比如偶像离我们很遥远,疲惫的时候、想放弃的时候,希望能听到偶像的鼓励。智能相框就是这样一个发明,智能相框是一种能够显示数字图片或视频片段并提供其他智能功能的设备。
2、智能相框实现原理方面,智能相框通常由硬件和软件两部分组成。硬件包括显示屏、处理器、存储器、连接接口等,用于显示图片和处理相关的操作。软件方面,智能相框通常运行基于操作系统的应用程序,用于管理照片、提供用户界面、与云端或社交网络进行数据同步等功能。一些智能相框还可以通过wi-fi或蓝牙与其他设备进行连接,例如手机、摄像头等。
3、现有的智能相框解决了图像或者视频展示以及怎么展示的问题。比如从云端下载图像展示、从社交媒体共享图像展示。比如根据环境光照条件调节展示效果、按照语音指令控制展示内容等。但展示的前提是存在,现有的智能相框只能展示已经真实存在的照片或者视频。而很多美好的回忆没有被捕捉,比如已经去世亲人的叮嘱。还有很多期望的事情没有真实存在过,比如篮球爱好者期望听到科比对他说加油,为解决上述问题,本发明提出一种。
技术实现思路
1、本发明提供了一种智能相框设备,以解决上述背景技术中提出的问题。
2、为了实现上述目的,本发明采用了如下技术方案:
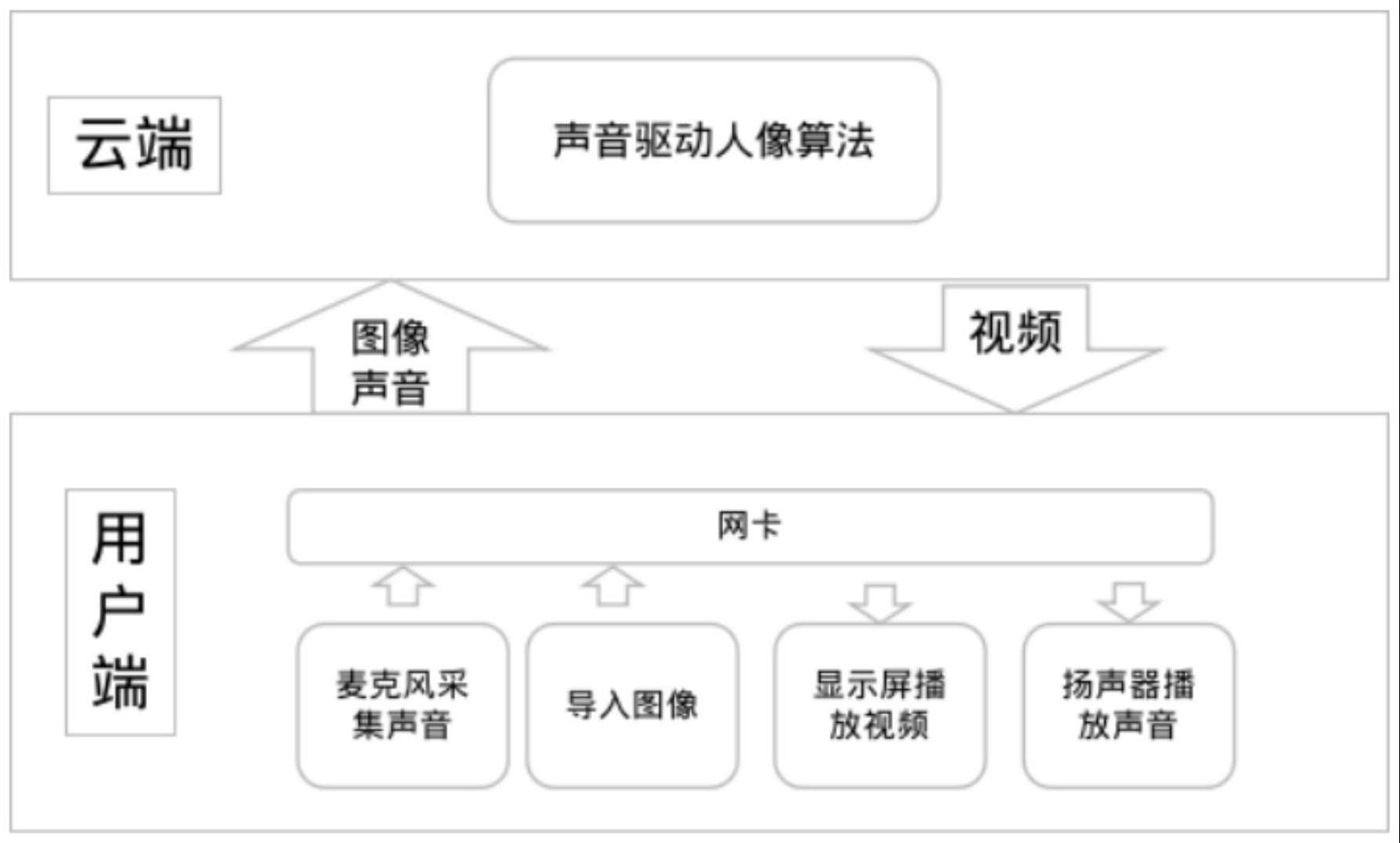
3、一种智能相框设备,包括包括云端和用户端,所述用户端包括显示屏、麦克风、扬声器、处理器、红外感应器以及网卡和电源,所述显示屏、麦克风、扬声器、红外感应器、网卡、电源均与处理器电信号连接,所述处理器通过网卡无线电连接有云端,所述云端内设有声音驱动人像算法。
4、作为本技术方案的进一步改进方案:所述云端为服务器。
5、作为本技术方案的进一步改进方案:所述声音驱动人像算法核心算法包括但不限于wav2lip、audio2face、agora lipsync等模型
6、作为本技术方案的进一步改进方案:所述声音驱动人像算法可以将图像和音频融合成视频,视频中人像表情自然,唇形与声音匹配。
7、作为本技术方案的进一步改进方案:所述云端和用户端交互包括编辑流程和播放流程。
8、作为本技术方案的进一步改进方案:所述编辑流程包括以下步骤:
9、s1,用户通过网络在用户端中上传一张或多张清晰图像;
10、s2,用户播放一段声音,并通过智能相框设备中的麦克风将声音上传到用户端中;
11、s3,将声音和选定的图像上传到云端,等待云端处理结束返回一段视频;
12、s4,选择保存视频,并设置播放时间段。
13、作为本技术方案的进一步改进方案:所述s2中,用户播放一段声音包括微信中的一段语音、视频软件中的一段台词。
14、作为本技术方案的进一步改进方案:所述播放流程包括以下步骤:
15、s1,智能相框在设置的播放时间段通过红外感应器检测到有人靠近时,会自动播放视频;
16、s2,用户根据时间段选择指定视频用于播放;
17、s3,播放视频通过相框的显示屏展示出来;
18、s4,当智能相框一段时间内没有检测到人体接近时,可以自动关闭显示屏或者进入待机模式以节省能源。
19、作为本技术方案的进一步改进方案:所述s2中,用户根据时间段选择指定视频用于播放,具体为:用户设置早晨播放偶像为自己加油打气的视频,晚上播放父母欢迎自己回家的视频。
20、与现有技术相比,本发明的有益效果是:
21、本发明可以将图像、语音和文本进行整合和处理,通过这种技术,人们可以更加方便地记录和分享自己的故事,同时也可以激发更多的创意和想象力,促进人与人之间的交流和理解,使得距离和时间的限制不再成为阻碍。
22、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。本发明的具体实施方式由以下实施例及其附图详细给出。
技术特征:
1.一种智能相框设备,其特征在于,包括包括云端和用户端,所述用户端包括显示屏、麦克风、扬声器、处理器、红外感应器以及网卡和电源,所述显示屏、麦克风、扬声器、红外感应器、网卡、电源均与处理器电信号连接,所述处理器通过网卡无线电连接有云端,所述云端内设有声音驱动人像算法。
2.根据权利要求1所述的一种智能相框设备,其特征在于,所述云端为服务器。
3.根据权利要求1所述的一种智能相框设备,其特征在于,所述声音驱动人像算法核心算法包括但不限于wav2lip、audio2face、agora lipsync等模型。
4.根据权利要求1所述的一种智能相框设备,其特征在于,所述声音驱动人像算法可以将图像和音频融合成视频,视频中人像表情自然,唇形与声音匹配。
5.根据权利要求1所述的一种智能相框设备,其特征在于,所述云端和用户端交互包括编辑流程和播放流程。
6.根据权利要求5所述的一种智能相框设备,其特征在于,所述编辑流程包括以下步骤:
7.根据权利要求6所述的一种智能相框设备,其特征在于,所述s2中,用户播放一段声音包括微信中的一段语音、视频软件中的一段台词。
8.根据权利要求7所述的一种智能相框设备,其特征在于,所述播放流程包括以下步骤:
9.根据权利要求8所述的一种智能相框设备,其特征在于,所述s2中,用户根据时间段选择指定视频用于播放,具体为:用户设置早晨播放偶像为自己加油打气的视频,晚上播放父母欢迎自己回家的视频。
技术总结
本发明公开了一种智能相框设备,包括包括云端和用户端,所述用户端包括显示屏、麦克风、扬声器、处理器、红外感应器以及网卡和电源,所述显示屏、麦克风、扬声器、红外感应器、网卡、电源均与处理器电信号连接,所述处理器通过网卡无线电连接有云端,所述云端内设有声音驱动人像算法。本发明可以将图像、语音和文本进行整合和处理,通过这种技术,人们可以更加方便地记录和分享自己的故事,同时也可以激发更多的创意和想象力,促进人与人之间的交流和理解,使得距离和时间的限制不再成为阻碍。
技术研发人员:叶文靖,张宇恒,陈达之,张支皓,陈煜馨,韦宪巧,朱鹏举,孙可艺
受保护的技术使用者:杭州医学院
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!