一种基于大模型微调的视频摘要生成方法
本发明属于多模态和语言大模型领域,具体涉及一种基于大模型微调的视频摘要生成方法。
背景技术:
1、多模态大模型具有融合多模态信息的能力,可以同时处理视频、图像和音频多种数据,它可以将这些信息结合在一起,以理解和生成更复杂、更丰富的内容。但现有的多模态大模型缺乏领域知识,泛化能力较差,无法针对特定领域的视频数据生成有针对性的摘要,因此,针对各种领域场景下的视频对多模态大模型进行微调,可以扩展大模型的使用场景,实现大模型在特定领域的实用化应用。
2、现有的多模态大模型主要是使用openai公司发布的语言大模型chatgpt生成指令数据集,将多模态特征对齐后在llm模型上微调,其所使用的数据大都来自于公开的视频、图像和音频数据集,虽然这些模型可以处理各种类型的数据,但无法对特定领域的数据进行深入的理解和处理,缺乏对模态数据中各种事物的细化理解。一个泛用的多模态模型,无法理解医学影像、工业设计这些特定领域的内容。
3、本发明提出的一种基于大模型微调的视频摘要生成方法通过收集特定领域的视频数据,经人工标注对应摘要后通过chatgpt构建领域多模态多轮对话数据集,并使用视频和音频模态上的最佳模型提取特征,通过大模型微调技术微调腾讯公司公开发布的macaw-llm多模态大模型,提高模型对专业领域视频数据的理解能力,生成包含更多领域信息的高质量摘要。现有的多模态大模型大多使用的是统一的模态编码器,使用线性投影对齐多模态特征后在macaw-llm模型上微调。
4、多模态大模型具有文本化表达多模态信息的独特优势,可以输出对视频、图像、音频数据进行分析的文本摘要。将这一能力应用到特定领域的视频摘要生成任务中,可以实现快速、自动化地解析复杂的多模态数据,获得关键信息。例如多模态大模型可以针对法院的各种审讯过程视频进行自动化流程描述,同时可以判断出视频中的违规行为,起到监管作用。这相比人工分析视频可以节省大量时间和精力。同时,使用各个模态的最佳模型可以保证多模态大模型的多模态特征提取能力,从而得到更准确的摘要。
技术实现思路
1、为解决现有多模态大模型缺乏领域知识,泛化能力较差,无法对特定领域的数据进行深入的理解和处理的问题。本发明提出一种基于大模型微调的视频摘要生成方法,通过少量样本的微调使大模型具备专业领域知识,提高视频摘要的专业性和合理性。
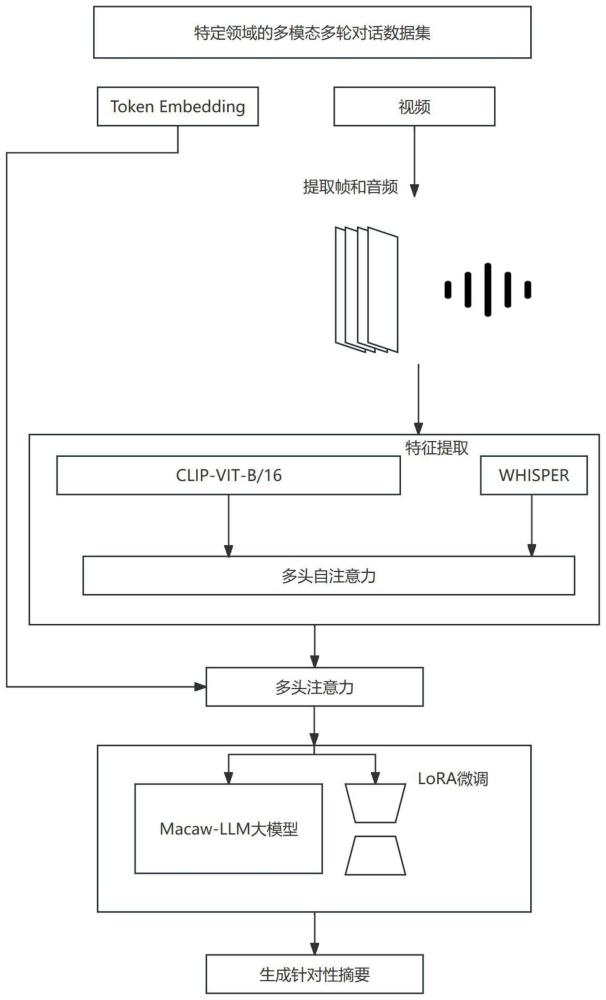
2、本发明的技术方案是这样实现的:
3、一种基于大模型微调的视频摘要生成方法,包括步骤:
4、步骤1:收集大量相关领域的视频资料。这些资料有各种来源,包括公开的数据库、社交媒体平台、学术研究机构或者专门的内容提供者。使用人工标注这些数据,为视频数据构建符合语义的摘要,形成视频摘要数据集;
5、步骤2:构建领域多模态多轮对话数据集,使用步骤1中的视频摘要数据集,构建特定的prompt,将prompt和人工摘要输入openai发布的gpt-3.5turbo版本大模型中,让gpt-3.5turbo根据摘要中的信息自动生成多个问题和答案,去除脏数据后形成多模态多轮对话数据集;
6、步骤3:视频帧提取,对于不同长度的视频,均只采样120帧,若视频长度超过120帧,则从视频中按相同间隔采样至120帧,若视频长度不足120帧,则采样一些重复帧以满足120帧的要求。
7、步骤4:音频提取,使用python的moviepy库提取视频摘要数据集中所有视频的音频片段;
8、步骤5:大模型读取,读取腾讯公司公开发布的在多个模态数据集上预训练过的macaw-llm多模态大模型;
9、步骤6:多模态特征提取,使用huggingface公司公开发布的clip-vit-b/16模型提取视频特征,whisper模型提取音频特征。使用1维卷积核调整转置后的三种模态的特征矩阵,压缩特征长度至较小且相等的值,使用线性投影层调整三种模态的特征矩阵隐藏维度,表示为:
10、h'v=linear(conv1d(hv))
11、h'a=linear(conv1d(ha))
12、步骤7:多模态特征对齐,使用多头自注意力机制让视频和音频两种模态特征对齐。再使用多头注意力机制,以对齐后的视频和音频拼接特征为query,macaw-llm大模型的词表嵌入矩阵token embedding为key和value,令所有模态的特征都在特征空间中对齐;
13、步骤8:使用lora技术微调macaw-llm大模型,具体包括:冻结macaw-llm大模型权重,增加两个旁路矩阵a和b。其中r<<min(d,k)。令输入为x时的前向传播过程为由h=wx变为wx+bax。
技术特征:
1.一种基于大模型微调的视频摘要生成方法,其特征在于:包括以下步骤:
2.根据权利要求1所述的一种基于大模型微调的视频摘要生成方法,其特征在于:所述的视频摘要数据集的构建包括以下步骤:
3.根据权利要求1所述的一种基于大模型微调的视频摘要生成方法,其特征在于:所述的多模态多轮对话数据集的构建,包括以下步骤:
4.根据权利要求1所述的一种基于大模型微调的视频摘要生成方法,其特征在于:使用python的opencv库采样视频帧,设置采样视频帧上限为120,视频总帧数超过120则从所有视频帧中均匀采样,视频总帧数小于120则从所有帧中随机抽取120帧,此时关键帧中存在重复帧。
5.根据权利要求1所述的一种基于大模型微调技术的视频摘要生成方法,其特征在于:步骤s4所述的特征转换,基于s3提取的视频特征hv与音频特征ha,使用一维卷积层来压缩多模态特征的序列长度,使用线性投影层压缩多模态特征的,得到h′v与h′a,计算如下式所示,压缩后的视频模态特征h′v和音频模态特征h′a的序列长度和序列维度均相等,且为固定值。
6.根据权利要求1所述的一种基于大模型微调技术的视频摘要生成方法,其特征在于:步骤s5所述的特征对齐,将基于步骤s4得到的h′v与h′a使用多头自注意力机制进行对齐,通过h=self-attn(h′v:h′a)计算获得,其中,h是对齐后的两种模态的表示,由h′v和h′a组成,操作符[:]代表级联操作,self-attn是多头自注意力算法。
7.根据权利要求1所述的一种基于大模型微调技术的视频摘要生成方法,其特征在于:步骤s5所述的特征对齐,将h与大模型macaw-llm的文本嵌入层e使用多头注意力机制进行对齐,通过h=attn(h,e)计算得到,其中,h是对齐后的表示,由hv和ha组成,e是macaw-llm大模型的token embedding,attn是多头注意力算法。
8.根据权利要求1所述的一种基于大模型微调技术的视频摘要生成方法,其特征在于:步骤s7所述的模态集成,是将步骤s5得到的和与文本指令进行融合,通过下式计算得到,
技术总结
本发明公开一种基于大模型微调的视频摘要生成方法。视频摘要生成是使用文字对原有视频内容进行总结与概括,在多模态领域应用广泛。本发明提出的基于大模型微调技术的视频摘要生成方法包括以下步骤:(1)利用MACAW‑LLM大模型多模态融合的特点,将视频特征与文本特征进行跨模态交互;(2)采用CLIP、WHISPER完成对视频和音频特征提取;(3)使用GPT‑3.5Turbo生成指令辅助摘要生成算法;(4)使用注意力机制算法完成模态对齐,并与指令进行融合;(5)采用LoRA微调技术进行模型训练,最小化负对数似然函数对大模型参数进行迭代更新并生成视频摘要。本发明使用少量训练数据就可完成零样本迁移学习,最终生成的视频摘要答案准确、条理清晰、内容丰富。
技术研发人员:周睿,吴臻,侯玉峰,王金强,郭岚,周庆国
受保护的技术使用者:兰州大学
技术研发日:
技术公布日:2024/1/22
- 还没有人留言评论。精彩留言会获得点赞!