用于调节麦克风阵列的方法及装置、语音设备和存储介质与流程
本申请涉及智能语音设备控制,例如涉及一种用于调节麦克风阵列的方法及装置、语音设备和存储介质。
背景技术:
1、目前,随着计算机技术的普及,人们的生活也变得越来越智能化,语音智能设备在生活中的应用也变得越来越广泛。而在智能语音设备中,基本都具有声源定位功能,通过多个麦克风之间的增强和抑制关系来实现优化拾音。但是在真正的用户交互场景中,在唤醒语音助手后,用户可能会离开原先的位置,此时麦克风阵列中原先的控制逻辑就无法准确分辨所接受到的音频信号是杂音还是交互内容。
2、相关技术公开了一种基于麦克风阵列的机器人拾音方法,包括:启用第一麦克风阵列在全方向上搜索音频信号;通过比对确定信号最强的目标音频信号及其所在的方向,并计算得到所述目标音频信号的声源角度信息;根据所述声源角度信息控制所述机器人转动至面向所述声源的方向并靠近所述声源;切换至第二麦克风阵列对所述声源的方向上进行拾音。
3、在实现本公开实施例的过程中,发现相关技术中至少存在如下问题:
4、通过设置两组麦克风阵列,第一组麦克风阵列确定声源方向,第二组麦克风阵列进行收音,在确定声源方向时,无法对音频信息做出判断,受到杂音的影响可能性较大,从而影响对用户指令的接收准确度。
5、需要说明的是,在上述背景技术部分公开的信息仅用于加强对本申请的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、为了对披露的实施例的一些方面有基本的理解,下面给出了简单的概括。所述概括不是泛泛评述,也不是要确定关键/重要组成元素或描绘这些实施例的保护范围,而是作为后面的详细说明的序言。
2、本公开实施例提供了一种用于调节麦克风阵列的方法及装置、语音设备和存储介质,可以提高对用户指令的接收准确度。
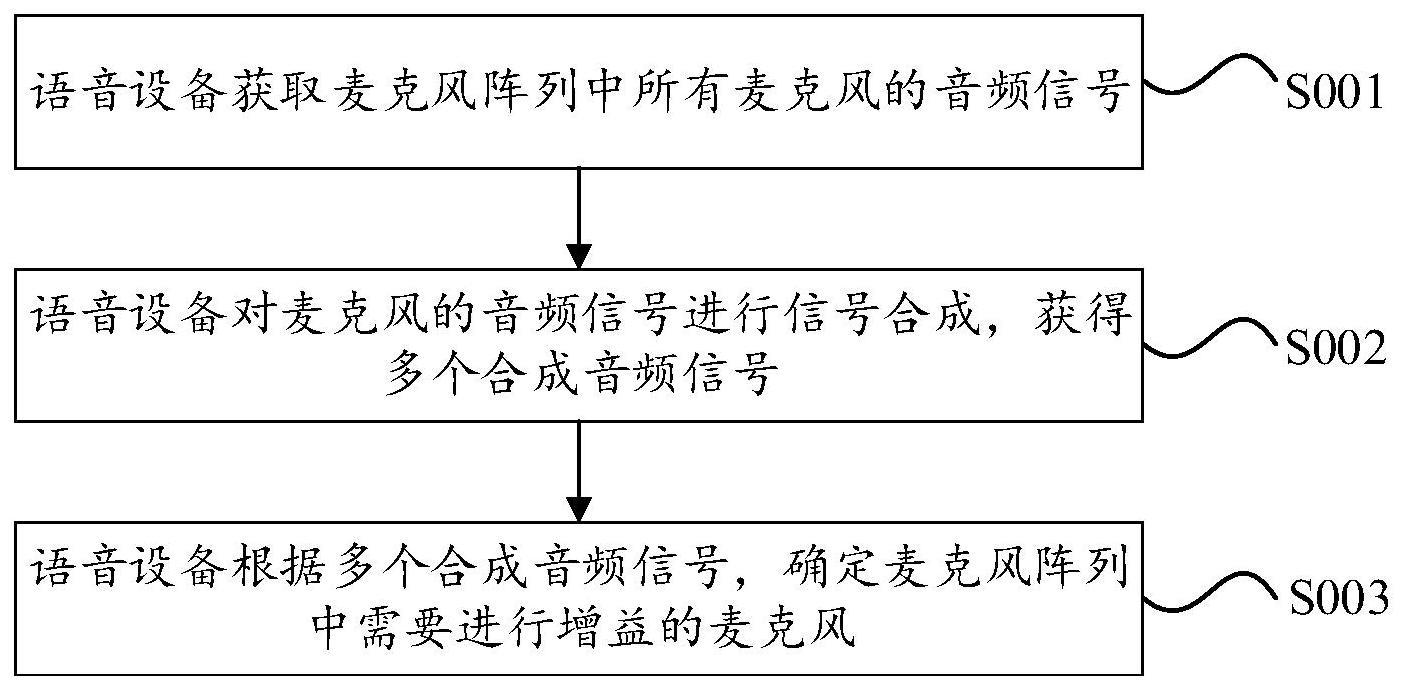
3、在一些实施例中,所述方法包括:获取麦克风阵列中所有麦克风的音频信号;对麦克风的音频信号进行信号合成,获得多个合成音频信号;根据多个合成音频信号,确定麦克风阵列中需要进行增益的麦克风。
4、可选地,所述对麦克风的音频信号进行信号合成,获得多个合成音频信号,包括:依次将第i个麦克风的音频信号作为增益,其他麦克风的音频信号作为抑制,进行信号合成,获得第i个合成音频信号;对所有麦克风的音频信号重复此步骤,直至获得n个合成音频信号;其中,i=1,…,n;n为麦克风阵列中麦克风的数量,且n≥2。
5、可选地,所述根据合成音频信号,确定麦克风阵列中需要进行增益的麦克风,包括:获取n个合成音频信号的文字识别结果;通过自然语言理解算法分析文字识别结果的意图与槽位,获得n组语义分类结果;将语义分类结果符合自然语言理解算法的意图与槽位的文字识别结果对应的麦克风,确定为需要进行增益的麦克风。
6、可选地,所述获取n个合成音频信号的文字识别结果,包括:将n个合成音频信号发送给自动语音识别服务器;接收自动语音识别服务器发送的n个合成音频信号的文字识别结果。
7、可选地,所述将语义分类结果符合自然语言理解算法的意图与槽位的文字识别结果对应的麦克风,确定为需要进行增益的麦克风,包括:若只有一个文字识别结果符合自然语言理解算法的意图与槽位,则将该文字识别结果对应的麦克风确定为需要进行增益的麦克风;若有多个文字识别结果符合自然语言理解算法的意图与槽位,则将该多个文字识别结果对应的麦克风确定为第一增益备选麦克风。
8、可选地,所述若有多个麦克风的文字识别结果符合自然语言理解算法的意图与槽位,则将该多个麦克风确定为第一增益备选麦克风后,还包括:再次获取麦克风阵列中所有麦克风的音频信号,将该次获取过程中需要进行增益的麦克风确定为第二增益备选麦克风;若第一增益备选麦克风与第二增益备选麦克风中只有一个麦克风是相同的,则将该麦克风确定为需要进行增益的麦克风;若第一增益备选麦克风与第二增益备选麦克风中有多个麦克风是相同的,则将这多个麦克风中位于中央位置的麦克风确定为需要进行增益的麦克风。
9、可选地,在确定麦克风阵列中需要进行增益的麦克风后,还包括:将需要进行增益的麦克风的判定结果反馈给终端进行物理增益。
10、在一些实施例中,所述装置包括处理器和存储有程序指令的存储器,其特征在于,所述处理器被配置为在运行所述程序指令时,执行如上述的用于调节麦克风阵列的方法。
11、在一些实施例中,所述语音设备包括麦克风阵列本体;以及如上述的用于调节麦克风阵列的装置,被安装于所述语音设备本体。
12、在一些实施例中,所述存储介质存储有程序指令,所述程序指令在运行时,执行如上述的用于调节麦克风阵列的方法。
13、本公开实施例提供的用于调节麦克风阵列的方法及装置、语音设备和存储介质,可以实现以下技术效果:
14、语音设备在被唤醒后,可以根据各个麦克风接收到的音频信号,获得相应的合成音频信号,及时调整麦克风阵列中的增益麦克风,提高对用户指令的接收准确度。
15、以上的总体描述和下文中的描述仅是示例性和解释性的,不用于限制本申请。
技术特征:
1.一种用于调节麦克风阵列的方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述对麦克风的音频信号进行信号合成,获得多个合成音频信号,包括:
3.根据权利要求2所述的方法,其特征在于,所述根据合成音频信号,确定麦克风阵列中需要进行增益的麦克风,包括:
4.根据权利要求3所述的方法,其特征在于,所述获取n个合成音频信号的文字识别结果,包括:
5.根据权利要求3所述的方法,其特征在于,所述将语义分类结果符合自然语言理解算法的意图与槽位的文字识别结果对应的麦克风,确定为需要进行增益的麦克风,包括:
6.根据权利要求5所述的方法,其特征在于,所述若有多个文字识别结果符合自然语言理解算法的意图与槽位,则将该多个文字识别结果对应的麦克风确定为第一增益备选麦克风后,还包括:
7.根据权利要求1至6任一项所述的方法,其特征在于,在确定麦克风阵列中需要进行增益的麦克风后,还包括:
8.一种用于调节麦克风阵列的装置,包括处理器和存储有程序指令的存储器,其特征在于,所述处理器被配置为在运行所述程序指令时,执行如权利要求1至7任一项所述的用于调节麦克风阵列的方法。
9.一种语音设备,其特征在于,包括:
10.一种存储介质,存储有程序指令,其特征在于,所述程序指令在运行时,执行如权利要求1至7任一项所述的用于调节麦克风阵列的方法。
技术总结
本申请涉及智能语音设备控制技术领域,公开一种用于调节麦克风阵列的方法,包括:获取麦克风阵列中所有麦克风的音频信号;对麦克风的音频信号进行信号合成,获得多个合成音频信号;根据多个合成音频信号,确定麦克风阵列中需要进行增益的麦克风。在本公开实施例中,语音设备可以根据各个麦克风接收到的音频信号,获得相应的合成音频信号,从而及时调整麦克风阵列中的增益麦克风,提高对用户指令的接收准确度。本申请还公开一种用于调节麦克风阵列的装置及语音设备。
技术研发人员:张宁,张景瑞,孔令磊,赵伟敏
受保护的技术使用者:青岛海尔电冰箱有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!