语音驱动的脸部视频生成方法、装置、电子设备及介质与流程
本发明涉及人工智能,尤其涉及一种语音驱动的脸部视频生成方法、装置、电子设备及介质。
背景技术:
1、语音驱动的脸部视频生成技术,旨在通过一段文字或者语音,驱动一张脸部照片或一段脸部视频,以生成新的视频。新的视频中脸部的嘴型需要和输入文字或语音高度的匹配,同时整体的视频应自然流畅。音唇同步的脸部视频生成技术在视频直播、教育教学等多个行业都具有广泛的应用。
2、目前,脸部视频的生成领域仍存在着音唇同步性不足、脸部细节不足以及真实性差等主要问题。因此,如何控制语音生成真实的脸部形象以及精准动作的唇形,是目前遇到的重要技术挑战。
技术实现思路
1、本发明提供了一种语音驱动的脸部视频生成方法、装置、电子设备及介质,以实时、精准的生成语音驱动的脸部视频。
2、根据本发明实施例的一方面,提供了一种语音驱动的脸部视频生成方法,包括:
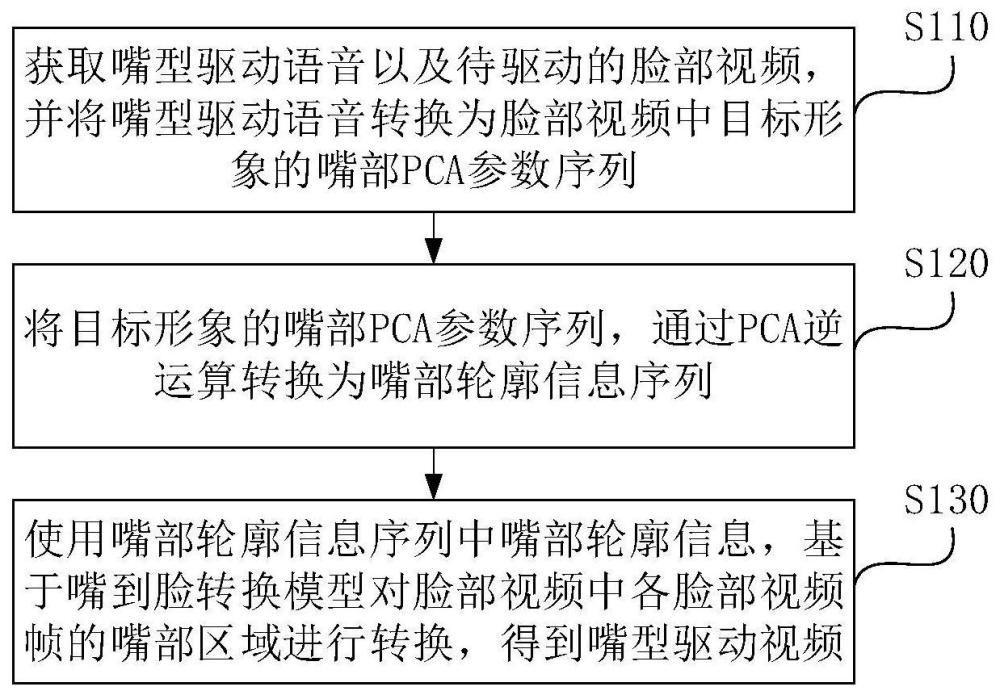
3、获取嘴型驱动语音以及待驱动的脸部视频,并将嘴型驱动语音转换为脸部视频中目标形象的嘴部pca(principal components analysis,主成分分析)参数序列;
4、将目标形象的嘴部pca参数序列,通过pca逆运算转换为嘴部轮廓信息序列;
5、使用嘴部轮廓信息序列中的各嘴部轮廓信息,基于预先训练的嘴到脸转换模型对脸部视频中各脸部视频帧的嘴部区域进行转换,得到嘴型驱动视频。
6、根据本发明实施例的另一方面,提供了一种语音驱动的脸部视频生成装置,包括:
7、嘴部pca参数序列生成模块,用于获取嘴型驱动语音以及待驱动的脸部视频,并将嘴型驱动语音转换为脸部视频中目标形象的嘴部pca参数序列;
8、嘴部轮廓信息序列转换模块,用于将目标形象的嘴部pca参数序列,通过pca逆运算转换为嘴部轮廓信息序列;
9、嘴型驱动视频转换模块,用于使用嘴部轮廓信息序列中的各嘴部轮廓信息,基于预先训练的嘴到脸转换模型对脸部视频中各脸部视频帧的嘴部区域进行转换,得到嘴型驱动视频。
10、根据本发明实施例的另一方面,还提供了一种电子设备,所述电子设备包括:
11、至少一个处理器;以及
12、与所述至少一个处理器通信连接的存储器;其中,
13、所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例所述的语音驱动的脸部视频生成方法。
14、根据本发明实施例的另一方面,还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于使处理器执行时实现本发明任一实施例所述的语音驱动的脸部视频生成方法。
15、本发明实施例的技术方案,通过获取嘴型驱动语音以及待驱动的脸部视频,并将嘴型驱动语音转换为脸部视频中目标形象的嘴部pca参数序列;将目标形象的嘴部pca参数序列,通过pca逆运算转换为嘴部轮廓信息序列;使用嘴部轮廓信息序列中的各嘴部轮廓信息,基于预先训练的嘴到脸转换模型对脸部视频中各脸部视频帧的嘴部区域进行转换,得到嘴型驱动视频的技术手段,将音频特征与人脸图像特征进行解耦,采用嘴部特征作为中间变量,实现语音驱动的脸部视频生成。本发明实施例的技术方案可以在有效提升语音驱动的脸部视频生成速度的同时,最大程度的保证视频中的音唇同步性以及脸部形象的自然度,有效满足应用脸部视频生成技术的各类应用场景。
16、应当理解,本部分所描述的内容并非旨在标识本发明的实施例的关键或重要特征,也不用于限制本发明的范围。本发明的其它特征将通过以下的说明书而变得容易理解。
技术特征:
1.一种语音驱动的脸部视频生成方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,将嘴型驱动语音转换为脸部视频中的目标形象的嘴部pca参数序列,包括:
3.根据权利要求2所述的方法,其特征在于,在将各音频特征向量依次输入至预先训练的音频到唇部特征转换模型中之前,还包括:
4.根据权利要求2或3所述的方法,其特征在于,将参考形象的嘴部pca参数序列,转换为目标形象的嘴部pca参数序列,包括:
5.根据权利要求1所述的方法,其特征在于,使用嘴部轮廓信息序列中的各嘴部轮廓信息,基于预先训练的嘴到脸转换模型对脸部视频中各脸部视频帧的嘴部区域进行转换,得到嘴型驱动视频,包括:
6.根据权利要求5所述的方法,其特征在于,在将所述目标遮挡视频帧和所述目标嘴部轮廓信息输入至所述嘴到脸转换模型中之前,还包括:
7.根据权利要求5或6所述的方法,其特征在于,嘴到脸转换模型中包括生成器、判别器以及预训练的视觉几何组网络,所述视觉几何组网络与所述生成器的输出端相连的,其中:
8.一种语音驱动的脸部视频生成装置,其特征在于,包括:
9.一种电子设备,其特征在于,所述电子设备包括:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于使处理器执行时实现权利要求1-7中任一项所述的语音驱动的脸部视频生成方法。
技术总结
本发明公开了一种语音驱动的脸部视频生成方法、装置、电子设备及介质。该方法包括:获取嘴型驱动语音以及待驱动的脸部视频,并将嘴型驱动语音转换为脸部视频中目标形象的嘴部PCA参数序列;将目标形象的嘴部PCA参数序列,通过PCA逆运算转换为嘴部轮廓信息序列;使用嘴部轮廓信息序列中的各嘴部轮廓信息,基于预先训练的嘴到脸转换模型对脸部视频中各脸部视频帧的嘴部区域进行转换,得到嘴型驱动视频。本发明实施例的技术方案将音频特征与人脸图像特征进行解耦,采用嘴部特征作为中间变量,实现语音驱动的脸部视频生成,可以在有效提升语音驱动的脸部视频生成速度的同时,最大程度的保证视频中的音唇同步性以及脸部形象的自然度。
技术研发人员:苏绪平,杜伟
受保护的技术使用者:上海智臻智能网络科技股份有限公司
技术研发日:
技术公布日:2024/2/8
- 还没有人留言评论。精彩留言会获得点赞!