低轨卫星平面间星间链路规划和功率分配的联合优化方法
本发明涉及卫星通信,尤其涉及一种低轨卫星平面间星间链路规划和功率分配的联合优化方法。
背景技术:
1、近年来,低地球轨道(leo)卫星星座已成为一种新兴且有前途的技术,低轨卫星系统被认为是未来6g时代空天地一体化网络的关键组成部分。许多头部公司,如spacex、oneweb和亚马逊,都试图部署一个大型的leo卫星星座,以提供稳定的宽带互联网服务。由于低轨卫星的高速运动,其星座拓扑具有高度动态性,导致在实时连接时星间链路切换频繁。由于低轨卫星相对位置时变、业务量时变和有限的电池能量,频繁切换导致的消耗将降低轨道卫星网络的整体性能。因此亟需设计一种低轨卫星星间链路规划和功率分配的联合优化方法,在卫星可用能量范围内优化星间链路传输功率,实现更高的数据传输速率,以提高低轨卫星网络的整体性能。
技术实现思路
1、本发明提供一种低轨卫星平面间星间链路规划和功率分配的联合优化方法,以解决由于低轨卫星网络位置时变、业务量时变、频繁切换的特点,导致建立平面间星间链路切换成本高,网络的整体性能降低的问题。
2、本发明通过下述技术方案实现:
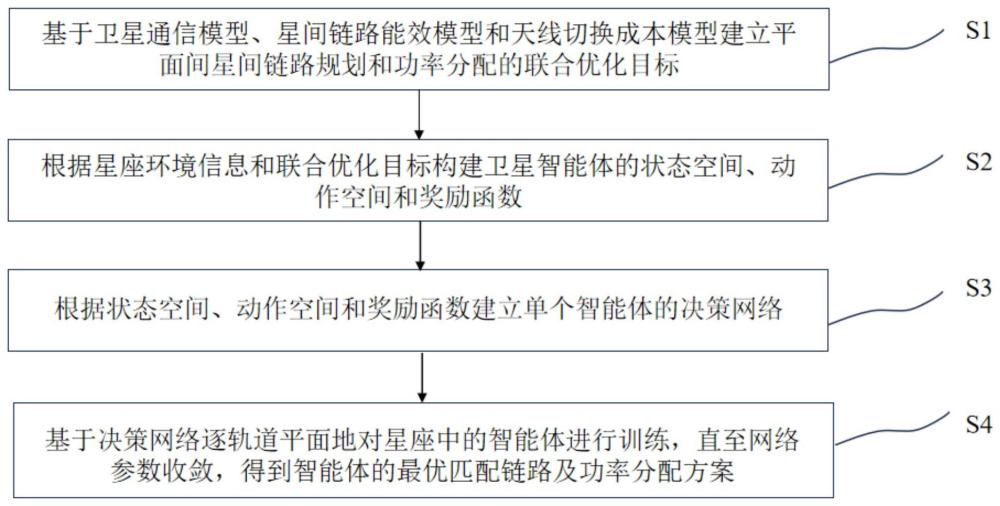
3、一种低轨卫星平面间星间链路规划和功率分配的联合优化方法,包括以下步骤:
4、步骤s1,基于卫星通信模型、星间链路能效模型和天线切换成本模型建立星间链路规划和功率分配的联合优化目标,所述联合优化目标包括星间链路通信速率、星间链路传输能效和天线切换成本;
5、步骤s2,根据星座环境信息和所述联合优化目标构建卫星智能体的状态空间、动作空间和奖励函数;
6、步骤s3,根据所述状态空间、动作空间和奖励函数建立单个智能体的决策网络;
7、步骤s4,基于所述决策网络逐轨道平面地对星座中的智能体进行训练,直至网络参数收敛,得到智能体所在卫星与其它卫星之间的最优匹配链路及功率分配方案。
8、本发明针对低轨卫星相对位置时变、业务量时变和有限的电池能量,提出一种低轨卫星平面间星间链路规划和功率分配联合优化方法,以星间链路通信速率、星间链路传输能效和天线切换成本为联合优化目标,建立单个智能体决策网络,动态规划星间链路和分配发射功率,在算法收敛后,每个智能体都可以做出最优的决策,从而提高星座整体能效和总吞吐量,同时降低平面间星间链路的切换成本。
9、进一步地,所述星间链路通信速率表示为:
10、
11、其中,euv表示可建链卫星对(u,v)之间的星间链路,是卫星u和卫星v之间的通信速率,b为信道带宽,snruv为卫星u和卫星v之间的信噪比;
12、所述星间链路传输能效表示为:
13、
14、其中,是在第t时隙卫星u和卫星v之间链路传输消耗的能量,为t时隙卫星u和卫星v之间的链路通信速率,为卫星u和卫星v之间的链路传输功率;
15、所述天线切换成本表示为:
16、
17、其中,是第t个时隙建立卫星u和卫星v之间的通信链路euv所需的天线转向角,为卫星u的平均天线转向角,为卫星v的平均天线转向角,et-1表示第(t-1)个时隙星座中星间链路的集合;
18、进一步地,所述可建链卫星对之间的视线距离小于欧几里得距离。
19、进一步地,所述状态空间表示为:si,t={di,t,ci,t,ωi,t},
20、其中,di,t为智能体i所在卫星在第t个时隙与视距范围内的下一轨道平面上的各个卫星之间的距离的集合,ci,t为智能体i所在卫星在第t个时隙时的电池容量,ωi,t为智能体i所在卫星在第t个时隙待转发到下一轨道平面上的数据量,si,t表示智能体i在第t个时隙的状态空间。
21、进一步地,所述动作空间表示为:
22、其中,vi,t∈vi,t,vi,t为卫星i在第t个时隙视距范围内的下一轨道平面上的卫星集合,表示智能体i与卫星vi,t建立星间链路时,分配给新建立的星间链路的功率,ai,t表示智能体i在第t个时隙的动作空间。
23、进一步地,所述奖励函数表示为:
24、其中,表示在第t个时隙、智能体i与所选择的动作vi,t对应的卫星的星间链路,表示星间链路的能效,表示星间链路的数据传输速率,表示建立星间链路时产生的天线切换成本,α1、α2和α3为权重因子,κi为链路冲突因子;
25、当星间链路没有链路冲突时,κi=1;
26、当存在链路冲突时,如果星间链路的传输能效和传输速率的加权和大于智能体i与其它卫星建立的星间链路的传输能效和传输速率的加权和,则κi=0.6,否则κi=0.05。
27、进一步地,所述步骤s3包括:
28、定义智能体i的动作值函数:
29、
30、其中,si为智能体i的状态,ai为智能体i的动作。vi为智能体i的星间链路规划动作,为智能体i为链路规划动作vi分配的传输功率。智能体i在状态si,t下选择动作得到关于智能体i的贝尔曼方程:
31、
32、其中,表示在状态si,t下执行即从这个状态和动作开始,智能体i在未来可以获得的期望累积奖励;ri,t是智能体i在第t个时隙的获得的即时奖励;γ为折扣因子;表示下一时刻的最大动作值,指智能体i会选择在下一步中能够带来最大值的动作,其中si,t+1是智能体i在下一个时隙的状态,sup()表示最小上界;si,t=si表示当前时刻智能体i的状态,si,t为智能体i在第t个时隙的状态,而si指状态空间中的一个具体状态。
33、根据确定的q函数,对于任意给定的vi,得到状态空间si的函数:
34、
35、使用深度神经网络来近似价值网络使用确定性策略网络来近似得到单个智能体决策网络:
36、
37、其中,wi为价值网络参数,θi为策略网络参数。
38、进一步地,所述步骤s4中的智能体训练过程包括以下步骤:
39、步骤s310,初始化价值网络参数wi、策略网络参数θi、价值网络的学习率α、策略网络的学习率β和探索率ξ,
40、步骤s320,初始化一个经验回放池d,所述经验回放池d用于存储状态转移数据;
41、步骤s330、从经验回放池d中随机采样小批量的状态转移数据,计算目标值yi,b、θi的损失函数lt(θi)和wi的损失函数lt(wi),更新价值网络参数wi、策略网络参数θi,直到网络参数收敛,得到智能体i所在卫星与其它卫星之间的最优匹配链路及功率分配方案。
42、进一步地,步骤s320包括:
43、步骤s321,初始化经验回放池d;
44、步骤s322,在第t个时隙,智能体i观测当前状态信息si,t,通过策略网络输出连续参数,即传输功率分配值通过贝尔曼方程最大化获取星间链路规划动作vi,t。具体地,通过获取“←”表示参数的更新,指将策略网络的输出值赋给通过获取离散动作vi,t,在和vi,t基础上根据ξ-greedy策略选择动作ai,t,并执行ai,t,在系统中建立相应的星间链路并为其分配功率;
45、步骤s323,观测下一时隙智能体i的状态空间si,t+1,并获取奖励数据ri,t,将状态转移数据[si,t,si,t+1,ai,t,ri,t]存储到经验回放池d中。
46、进一步地,步骤s330包括:
47、步骤s331,在经验回放池中随机采样小批量状态转移数据[si,b,si,b+1,ai,b,ri,b],b指采样的小批量中第b个样本,每个状态转移元组包括智能体i当前状态si,b、下一个状态si,b+1、选择的动作ai,b以及即时奖励ri,b;
48、步骤s332,计算每个样本的目标值:以用于训练值网络,其中,γ为折扣因子;
49、步骤s333,计算价值网络的损失函数lt(wi)和策略网络的损失函数lt(θi):
50、
51、其中,yi,b是目标值,是当前价值网络在状态si,b、动作情况下的预测值,通过最小化预测值和目标值之间的均方误差,使得价值网络逐渐逼近真实的最优值函数。
52、
53、其中,表示当前价值网络在状态si,b、星间链路规划动作vi,b和策略网络所输出的传输功率分配值情况下的预测值,通过最大化当前状态下各个的价值,来优化策略网络的参数,使得策略网络选择更合适的功率分配值。
54、步骤s334,更新价值网络参数和策略网络参数,更新公式为:
55、
56、
57、其中,α和β分别是价值网络和策略网络的学习率,是智能体i的价值网络损失函数关于参数wi的梯度,是智能体i的策略网络损失函数关于参数θi的梯度,“←”表示参数的更新;
58、步骤s335,重复步骤s331-s334,直到智能体i的策略网络和价值网络收敛。
59、本发明与现有技术相比,具有如下的优点和有益效果:
60、1、以星间链路通信速率、星间链路传输能效和天线切换成本为联合优化目标,建立单个智能体决策网络,动态规划星间链路和分配发射功率,每个智能体都可以做出最优的决策,从而提高星座整体能效和总吞吐量,同时降低平面间星间链路的切换成本。
61、2、针对联合优化时存在的离散和连续混杂行动空间问题以及高维高动态特性,引入参数化动作空间,根据当前星座环境信息构建状态空间、动作空间和奖励函数,基于参数化深度强化对智能体进行训练,直至收敛,实现能效感知的精细化星间链路动态适配。
62、3、为了避免“维数诅咒”问题,对智能体进行逐轨训练,并设计了一种链路切换冲突惩罚机制来权衡卫星之间的决策,从而得到最优的决策结果。
- 还没有人留言评论。精彩留言会获得点赞!