一种配置文件稽核场景中自动处理变量数据的方法及装置与流程
本发明涉及通信网络运维领域,尤其是一种配置文件稽核场景中自动处理变量数据的方法及装置。
背景技术:
1、在通信网络运维场景中,一个难点是如果对通信设备上的配置文件进行稽核,配置文件的大小从几百k到几十m不等,内容全部是网络配置以及业务配置相关指令,完全由运维人员手工进行配置,配置过程中很容易出现误配、漏配、多配等情况。由于配置信息中包含大量的业务元素,如设备名称、端口ip、网络关系等,在配置文件稽核时,即要检查配置指令的指令部分本身是否正确,也要检查其中的业务信息是否正确。
2、目前的主流方案是使用无监督算法训练,从一组相似的配置文件中提取共性规则。通过如tf-idf算法,从配置文件中找出频率较高的字符串,识别出配置指令中的关键字,将非关键字的字符识别为变量,进而构建出模型。在使用该模型对一个配置文件进行稽核时,根据配置文件中相关指令关键字与变量的位置排列关系,确定稽核指令是否正确。
3、现有的方案中,对于识别出的变量如何构建正则表达式是一大难点。例如某行配置指令的内容为“web-auth-server 12.123.234.34port 12345”,无监督的模型能识别出命令中的两个关键字为“web-auth-server”和“port”,两个变量为“12.123.234.34”和“50100”,“12.123.234.34”还可以通过一定的规则判断出是ip,转成较合适的ip类正则表达式,但是“12345”这样的数字,如何判断数字位数最小几位以及最大几位,从而构建出合适的正则表达式,就比较困难了。
技术实现思路
1、为解决现有技术存在的上述问题,本发明提供一种配置文件稽核场景中自动处理变量数据的方法及装置,用于在使用无监督算法对通信网络设备的配置文件进行配置准确性稽核时,自动识别配置中的变量信息,并构建最适合的正则表达式去匹配变量信息。
2、为实现上述目的,本发明采用下述技术方案:
3、在本发明一实施例中,提出了一种配置文件稽核场景中自动处理变量数据的方法,该方法包括:
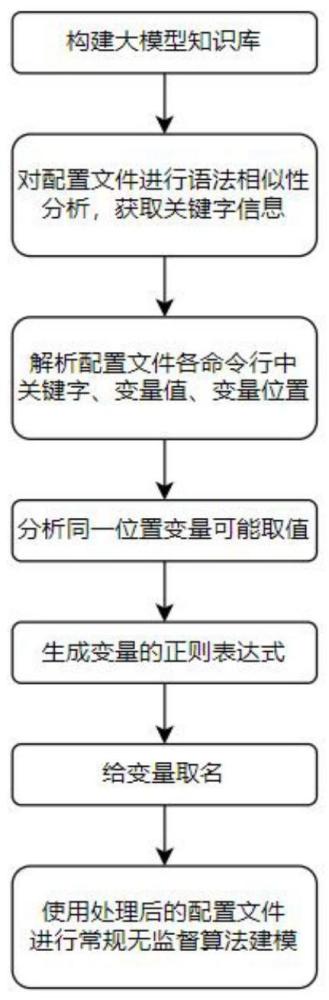
4、构建大模型知识库,在大模型知识库上构建指令关键字检索接口、指令变量检索接口、知识补充接口以及大模型对话接口;
5、对所有收集到的通信设备配置文件进行语法相似度分析,获取关键字信息,进而解析出配置文件各命令行中关键字与变量位置,调用大模型知识库的知识补充接口,将配置文件解析结果添加至大模型知识库中;
6、调用大模型知识库的指令关键字检索接口,根据配置文件各命令行中关键字与变量位置,提取出同一位置变量可能取值,调用大模型知识库的大模型对话接口,生成变量可能取值相关的正则表达式;
7、使用命令行的变量可能取值,调用大模型知识库的指令变量检索接口,获取变量在同一个配置文件中的所有出现位置,将同一个配置文件中取值和正则表达式相同的变量,设定为同一名字。
8、进一步地,生成变量可能取值相关的正则表达式的过程如下:
9、使用命令行中关键字与变量位置,调用知识库的指令关键字检索接口,获取该命令行在所有配置文件中的对应变量位置上可能使用的变量值,将变量所有可能取值转成列表;
10、使用变量可能取值列表,调用知识库的大模型对话接口,通过配置提示词,要求大模型通过变量可能取值的枚举信息,构建正则表达式;
11、读取到正则表达式后,使用该变量位置上所有使用过的变量可能取值,验证正则表达式是否正确;如果正则表达式错误,则将上一次大模型对话接口的请求信息与返回结果以及本次无法匹配正则表达式的变量可能取值,传给大模型知识库的大模型对话接口,要求大模型修正正则表达式;
12、将该变量位置的可能取值定义,设置为大模型生成或修正后的正则表达式。
13、进一步地,变量命名时,可将命令行中关键字与变量位置拼在一起,再拼接序列值或随机数,作为变量名。
14、在本发明一实施例中,还提出了一种配置文件稽核场景中自动处理变量数据的装置,该装置包括:
15、大模型知识库构建模块,用于构建大模型知识库,在大模型知识库上构建指令关键字检索接口、指令变量检索接口、知识补充接口以及大模型对话接口;
16、配置文件解析模块,用于对所有收集到的通信设备配置文件进行语法相似度分析,获取关键字信息,进而解析出配置文件各命令行中关键字与变量位置,调用大模型知识库的知识补充接口,将配置文件解析结果添加至大模型知识库中;
17、正则表达式生成模块,用于调用大模型知识库的指令关键字检索接口,根据配置文件各命令行中关键字与变量位置,提取出同一位置变量可能取值,调用大模型知识库的大模型对话接口,生成变量可能取值相关的正则表达式;使用命令行的变量可能取值,调用大模型知识库的指令变量检索接口,获取变量在同一个配置文件中的所有出现位置,将同一个配置文件中取值和正则表达式相同的变量,设定为同一名字。
18、进一步地,生成变量可能取值相关的正则表达式的过程如下:
19、使用命令行中关键字与变量位置,调用知识库的指令关键字检索接口,获取该命令行在所有配置文件中的对应变量位置上可能使用的变量值,将变量所有可能取值转成列表;
20、使用变量可能取值列表,调用知识库的大模型对话接口,通过配置提示词,要求大模型通过变量可能取值的枚举信息,构建正则表达式;
21、读取到正则表达式后,使用该变量位置上所有使用过的变量可能取值,验证正则表达式是否正确;如果正则表达式错误,则将上一次大模型对话接口的请求信息与返回结果以及本次无法匹配正则表达式的变量可能取值,传给大模型知识库的大模型对话接口,要求大模型修正正则表达式;
22、将该变量位置的可能取值定义,设置为大模型生成或修正后的正则表达式。
23、进一步地,变量命名时,可将命令行中关键字与变量位置拼在一起,再拼接序列值或随机数,作为变量名。
24、在本发明一实施例中,还提出了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现前述配置文件稽核场景中自动处理变量数据的方法。
25、在本发明一实施例中,还提出了一种计算机可读存储介质,计算机可读存储介质存储有执行配置文件稽核场景中自动处理变量数据的方法的计算机程序。
26、有益效果:
27、1、本发明使用大模型知识库的能力,对配置文件中的变量进行分析,找出命令行中对应位置的变量可能的枚举值,进而使用大模型能力生成变量对应的正则表达式。
28、2、本发明使用大模型知识库的能力,分析同一含义的变量,在同一配置文件的不同位置,是否应为相同取值,进而根据变量取值的一致或不同,自动创建合适的变量名,确保相同命名的变量,在同一配置文件的不同位置,取值结果也是完全一致。
技术特征:
1.一种配置文件稽核场景中自动处理变量数据的方法,其特征在于,该方法包括:
2.根据权利要求1所述的配置文件稽核场景中自动处理变量数据的方法,其特征在于,生成变量可能取值相关的正则表达式的过程如下:
3.根据权利要求1所述的配置文件稽核场景中自动处理变量数据的方法,其特征在于,所述变量命名时,可将命令行中关键字与变量位置拼在一起,再拼接序列值或随机数,作为变量名。
4.一种配置文件稽核场景中自动处理变量数据的装置,其特征在于,该装置包括:
5.根据权利要求4所述的配置文件稽核场景中自动处理变量数据的装置,其特征在于,生成变量可能取值相关的正则表达式的过程如下:
6.根据权利要求4所述的配置文件稽核场景中自动处理变量数据的装置,其特征在于,所述变量命名时,可将命令行中关键字与变量位置拼在一起,再拼接序列值或随机数,作为变量名。
7.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1-3任一项所述方法。
8.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有执行权利要求1-3任一项所述方法的计算机程序。
技术总结
本发明公开一种配置文件稽核场景中自动处理变量数据的方法及装置,其中,该方法包括:构建大模型知识库;对所有收集到的通信设备配置文件进行语法相似度分析,获取关键字信息,进而解析出配置文件各命令行中关键字与变量位置,添加至大模型知识库中;根据配置文件各命令行中关键字与变量位置,提取出同一位置变量可能取值,生成变量可能取值相关的正则表达式;使用命令行的变量可能取值,获取变量在同一个配置文件中的所有出现位置,将同一个配置文件中取值和正则表达式相同的变量,设定为同一名字。该方法及装置自动识别配置中的变量信息,并构建最适合的正则表达式去匹配变量信息。
技术研发人员:毛恒
受保护的技术使用者:中盈优创资讯科技有限公司
技术研发日:
技术公布日:2024/6/13
- 还没有人留言评论。精彩留言会获得点赞!