一种基于深度学习的帧内编码方法
本发明涉及深度学习、视频编码领域,尤其涉及一种基于深度学习的帧内编码方法。
背景技术:
1、随着互联网信息技术的快速发展和智能移动终端广泛普及,多媒体视频服务已经渗透到现代社会的方方面面,例如:数字电视、视频会议、在线课程、网络直播、沉静式体验等。为了高效压缩视频数据,itu-t和iso/iec联合推出了通用视频编码(versatile videocoding,vvc)标准。
2、对于彩色视频来说,同一帧图像内亮度分量和色度分量三个通道之间具有高度相关性。为了高效去除分量间冗余,vvc在传统角度预测模式的基础上新引入了分量间线性模型(cross component liner model,cclm)预测技术,并取得了较好的编码性能提升。然而,基于cclm技术的色度帧内预测方法均假设亮度分量和色度分量之间满足线性关系,对于包含复杂纹理的编码块,由于线性拟合的方法难以准确表示分量间的复杂关系,因此色度预测的准确性受限。
3、近年来,深度学习技术在计算机视觉领域取得巨大成功。受此启发,一些研究人员开始探索深度学习技术,用于增强或代替传统混合编码框架中的cclm预测技术。li等人首先提出将卷积神经网络用于色度帧内预测,该方法先利用卷积层提取当前编码单元(coding unit,cu)的亮度特征,再利用全连接层从相邻已重建的亮度和色度参考像素中提取空域特征,最后将两部分特征级联融合,预测得到当前编码单元的色度分量。blanch等人将注意力机制引入到神经网络中,在色度预测过程中计算每个边界参考像素的重要程度,进一步提高了色度分量的预测准确度。然而现有基于深度学习的色度帧内预测方法未能充分考虑到边界参考像素与当前编码单元像素之间的相对位置关系,限制了色度预测准确度的提升。此外,现有方法未考虑分量间颜色统计量的相关性,色度分量的编码效率仍有较大提升空间。
技术实现思路
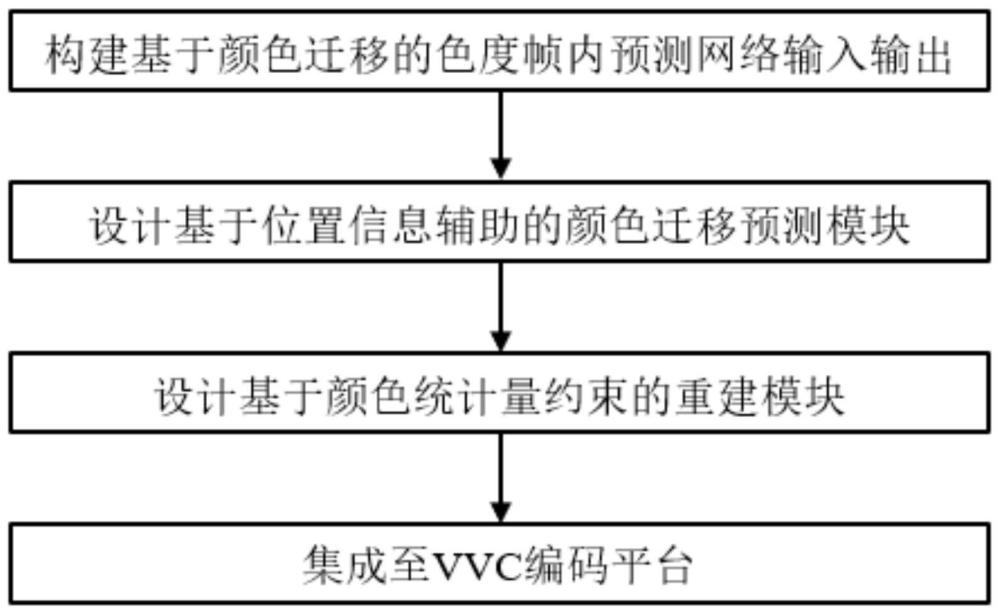
1、本发明提供了一种基于深度学习的帧内编码方法,本发明设计了一个基于颜色迁移的色度帧内预测网络,通过充分利用当前编码单元亮度信息和边界参考信息,准确预测得到当前编码单元的色度分量,从而高效去除分量间冗余,详见下文描述:
2、一种基于深度学习的帧内编码方法,所述方法包括:
3、构建基于颜色迁移的色度帧内预测网络的输入输出,输入为当前编码单元亮度分量和边界参考像素,输出为当前编码单元的色度分量预测结果;
4、设计基于位置信息辅助的颜色迁移预测模块,模块的输入为当前编码单元亮度分量和边界参考像素,利用多尺度卷积块分别从两个输入中提取特征,并通过位置编码单元和颜色统计量对齐单元获得颜色迁移后的精细化预测特征;
5、设计基于颜色统计量约束的重建模块,模块的输入为颜色迁移后的预测特征fc′,通过2个3×3卷积层获得当前编码单元对应的重建色度分量通过构建颜色直方图一致性损失,使得重建模块更加关注于生成具有准确纹理边缘的色度预测结果;
6、利用上述提到的颜色直方图一致性损失和以均方误差计算的重建损失作为总损失训练基于颜色迁移的色度帧内预测网络,并将训练好的网络模型集成到vvc编码平台,输出最后的编码结果。
7、其中,所述基于位置信息辅助的颜色迁移预测模块包括:多尺度卷积块、位置编码单元和颜色统计量对齐单元,
8、通过多尺度卷积块分别从当前编码单元亮度分量il和边界参考像素ir中提取对应的特征表达fc和fs;
9、设计一位置编码单元,通过获取像素间位置信息辅助颜色迁移预测过程;
10、将增强后的特征fc_pos和fs_pos送入颜色统计量对齐单元,在特征层面对齐fc_pos和fs_pos的均值、方差,获得颜色迁移后的特征fct;
11、将特征fct与所提取的当前编码单元亮度分量的原始特征fc级联,经过1个3×3卷积融合获得预测特征fc′。
12、其中,所述多尺度卷积块由1个1×1和1个3×3卷积并联构成,卷积核个数均为128,利用不同尺度的卷积使得提取到的特征包含更丰富的信息,如下:
13、fc=fe1(il)
14、fs=fe2(ir)
15、其中,fe1(·)和fe2(·)分别表示用于提取当前编码单元亮度分量和边界参考像素特征的多尺度卷积块。
16、其中,所述获取像素间位置信息辅助颜色迁移预测过程为:
17、先通过一组可学习参数训练得到代表当前编码单元亮度分量和边界参考像素整体空间位置关系的向量posall,再经过拆分得到二者各自的位置向量posc和poss,分别将其与特征fc和fs级联,对fc和fs进行位置信息增强,公式表达如下:
18、posc,poss=split(posall)
19、fc_pos=[fc,posc]
20、fs_pos=[fs,poss]
21、其中,[·]表示级联操作,split(·)表示在空间维度对特征向量进行拆分。
22、其中,颜色迁移后的特征fct、预测特征fc′的公式表达如下:
23、fct=csau(fc_pos,fs_pos)
24、f′c=conv([fct,fc])
25、其中,conv(·)表示卷积操作,csau(·)表示基于adaattn的颜色统计量对齐单元,adaattn用于在通道维度对两个特征进行均值和方差对齐。
26、其中,所述颜色直方图一致性损失函数为:
27、
28、此外,本方法也使用均方误差计算重建损失来约束重建色度分量的质量,公式表达如下:
29、
30、整体网络的总损失l的表示如下:
31、l=lrec+2lch
32、其中,λ表示两个损失之间的平衡参数,分别表示重建色度分量,cb、cr分别表示原始色度分量,hcb、hcr分别表示重建色度分量和原始色度分量图对应的颜色直方图。
33、本发明提供的技术方案的有益效果是:
34、1、本发明设计了一种基于深度学习的帧内编码方法,通过高效去除分量间冗余提升色度分量编码效率;
35、2、本发明设计了一个基于颜色迁移的色度帧内预测网络,以获得更加准确的色度预测,所设计的网络将色度帧内预测建模为颜色迁移任务,利用像素间的位置关系辅助边界参考像素进行颜色迁移,获得准确的色度预测结果;同时,构建颜色直方图一致性损失,通过约束色度分量预测值的颜色直方图分布以减少纹理边缘平滑问题;
36、3、本发明将所提出的色度帧内编码方法集成到vvc参考软件vtm7.0中,与vvc参考软件vtm7.0相比,所提出的方法能够有效提升色度分量编码效率。
技术特征:
1.一种基于深度学习的帧内编码方法,其特征在于,所述方法包括:
2.根据权利要求1所述的一种基于深度学习的帧内编码方法,其特征在于,所述基于位置信息辅助的颜色迁移预测模块包括:多尺度卷积块、位置编码单元和颜色统计量对齐单元,
3.根据权利要求2所述的一种基于深度学习的帧内编码方法,其特征在于,所述多尺度卷积块由1个1×1和1个3×3卷积并联构成,卷积核个数均为128,利用不同尺度的卷积使得提取到的特征包含更丰富的信息,如下:
4.根据权利要求2所述的一种基于深度学习的帧内编码方法,其特征在于,所述获取像素间位置信息辅助颜色迁移预测过程为:
5.根据权利要求2所述的一种基于深度学习的帧内编码方法,其特征在于,颜色迁移后的特征fct、预测特征f′c的公式表达如下:
6.根据权利要求1所述的一种基于深度学习的帧内编码方法,其特征在于,所述颜色直方图一致性损失为:
技术总结
本发明公开了一种基于深度学习的帧内编码方法,包括:构建基于颜色迁移的色度帧内预测网络,输入为当前编码单元亮度分量和边界参考像素,输出为当前编码单元的色度分量预测结果;设计基于位置信息辅助的颜色迁移预测模块,利用多尺度卷积块分别从两个输入中提取特征,并通过位置编码单元和颜色统计量对齐单元获得颜色迁移后的精细化预测特征;设计基于颜色统计量约束的重建模块,通过构建颜色直方图一致性损失,使得重建模块更加关注于生成具有准确纹理边缘的色度预测结果。本发明借助深度学习的特征提取与表达能力,通过充分利用当前编码单元亮度信息和边界参考信息,准确预测当前编码单元的色度分量,进一步提高视频帧内编码性能。
技术研发人员:章文,汪清,彭勃,李戈,雷建军
受保护的技术使用者:天津大学
技术研发日:
技术公布日:2024/5/12
- 还没有人留言评论。精彩留言会获得点赞!