一种视频生成方法、计算机程序产品及系统与流程
本发明涉及视频处理,特别涉及一种视频生成方法、计算机程序产品及系统。
背景技术:
1、随着网络短视频的兴起,越来越多商家通过网络短视频进行广告宣传。商家制作介绍商品或服务的宣传视频,需要工作人员拍摄视频素材之外,还需对视频素材进行视频剪辑、合成、配文、配音等工作,需耗费大量时间精力。
技术实现思路
1、本发明要解决的技术问题是提供一种能够节省制作所需时间精力的视频生成方法。
2、为解决上述技术问题,本发明提供一种视频生成方法,包括如下步骤:
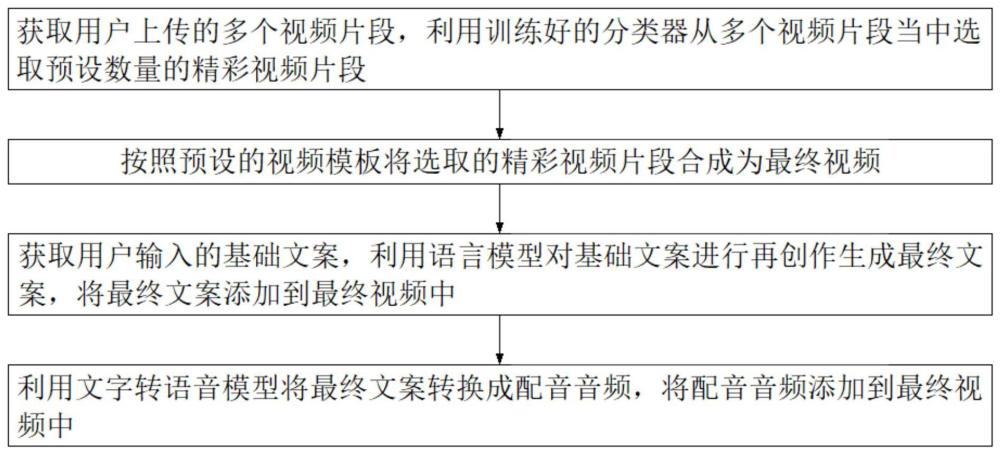
3、a.获取用户上传的多个视频片段,利用训练好的分类器从多个视频片段当中选取预设数量的精彩视频片段;
4、b.按照预设的视频模板将选取的精彩视频片段合成为最终视频;
5、c.获取用户输入的基础文案,利用语言模型对所述基础文案进行再创作生成最终文案,将所述最终文案添加到最终视频中;
6、d.利用文字转语音模型将所述最终文案转换成配音音频,将配音音频添加到最终视频中。
7、进一步地,所述步骤a中,所述分类器的训练过程如下:获取多个已标注好精彩内容的精彩视频片段,然后将这些精彩视频片段按一定比例划分为训练数据集和测试数据集,将训练数据集输入到分类器中对其进行训练,然后将测试数据集输入到分类器中进行测试,评估分类器识别精彩视频片段的准确率,若分类器识别精彩视频片段的准确率达到预设阈值则训练完成,若分类器识别精彩视频片段的准确率未能达到预设阈值则继续获取其他训练数据集输入到分类器中进行训练,直至分类器识别精彩视频片段的准确率达到预设阈值。
8、进一步地,所述步骤a中,对用户上传的多个视频片段进行预处理,具体将视频片段的视频帧提取出来或者对视频片段进行切割得到多个视频帧,再使用计算机视觉技术对视频帧进行特征提取,然后使用降维方法将提取到的视频特征映射到一个向量空间中进行特征表示。
9、进一步地,所述步骤a中,在选取出精彩视频片段之后,通过显示装置输出给用户进行人工审核,并根据用户反馈的审核结果对分类器进行迭代和优化。
10、进一步地,所述步骤c中,对基础文案进行再创作包括改写、扩写和口语化当中的至少一项。
11、本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上所述的视频生成方法中的步骤。
12、本发明还提供一种视频生成系统,包括相互连接的处理器和如上所述的计算机程序产品。
13、本发明具有以下有益效果:本发明利用分类器选取精彩视频片段合成为最终视频,利用语言模型对基础文案进行再创作得到最终文案,利用文字转语音模型将最终文案转换成配音音频,从而减轻工作人员进行视频剪辑、合成、配文、配音等工作,节省时间精力。
技术特征:
1.一种视频生成方法,其特征是,包括如下步骤:
2.根据权利要求1所述的视频生成方法,其特征是,所述步骤a中,所述分类器的训练过程如下:获取多个已标注好精彩内容的精彩视频片段,然后将这些精彩视频片段按一定比例划分为训练数据集和测试数据集,将训练数据集输入到分类器中对其进行训练,然后将测试数据集输入到分类器中进行测试,评估分类器识别精彩视频片段的准确率,若分类器识别精彩视频片段的准确率达到预设阈值则训练完成,若分类器识别精彩视频片段的准确率未能达到预设阈值则继续获取其他训练数据集输入到分类器中进行训练,直至分类器识别精彩视频片段的准确率达到预设阈值。
3.根据权利要求1所述的视频生成方法,其特征是,所述步骤a中,对用户上传的多个视频片段进行预处理,具体将视频片段的视频帧提取出来或者对视频片段进行切割得到多个视频帧,再使用计算机视觉技术对视频帧进行特征提取,然后使用降维方法将提取到的视频特征映射到一个向量空间中进行特征表示。
4.根据权利要求1所述的视频生成方法,其特征是,所述步骤a中,在选取出精彩视频片段之后,通过显示装置输出给用户进行人工审核,并根据用户反馈的审核结果对分类器进行迭代和优化。
5.根据权利要求1所述的视频生成方法,其特征是,所述步骤c中,对基础文案进行再创作包括改写、扩写和口语化当中的至少一项。
6.一种计算机程序产品,包括计算机程序,其特征是,所述计算机程序被处理器执行时实现如权利要求1至5任一项所述的视频生成方法中的步骤。
7.一种视频生成系统,其特征是,包括相互连接的处理器和如权利要求6所述的计算机程序产品。
技术总结
本发明提供一种视频生成方法、计算机程序产品及系统,该方法包括如下步骤:获取用户上传的多个视频片段,利用训练好的分类器从多个视频片段当中选取预设数量的精彩视频片段,按照预设的视频模板将选取的精彩视频片段合成为最终视频,获取用户输入的基础文案,利用语言模型对基础文案进行再创作生成最终文案,将最终文案添加到最终视频中,利用文字转语音模型将最终文案转换成配音音频,将配音音频添加到最终视频中,从而减轻工作人员进行视频剪辑、合成、配文、配音等工作,节省时间精力。
技术研发人员:张俊杰
受保护的技术使用者:广州华数云计算有限公司
技术研发日:
技术公布日:2024/6/20
- 还没有人留言评论。精彩留言会获得点赞!