一种视频剪辑方法、设备、介质和程序产品与流程
本申请实施例涉及视频处理,尤其涉及一种视频剪辑方法、设备、介质和程序产品。
背景技术:
1、现有技术中关于动作视频的剪辑通常通过人工或智能剪辑得到摘要片段,但是,人工剪辑的方式用人成本较高且费时费力;智能剪辑虽然无需使用人工,但是对于复杂内容的理解度不高,无法捕捉视频任务运动和动态变化,或剪辑缺乏灵活性。
2、目前基于深度神经网络进行剪辑的方式较为流行,但需要依靠两阶段的模型进行视频的处理,即时序动作检测和关键帧检测需要依靠不同的模型进行预测分析,需要依赖大量的参数训练,且计算用时较长,也容易产生累积误差,预测准确性降低。
技术实现思路
1、本申请实施例提供一种视频剪辑方法、设备、介质和程序产品,以解决现有的剪辑动作视频用时较长和预测准确性降低问题。
2、为了解决上述技术问题,本申请是这样实现的:
3、第一方面,本申请实施例提供了一种视频剪辑方法,包括:
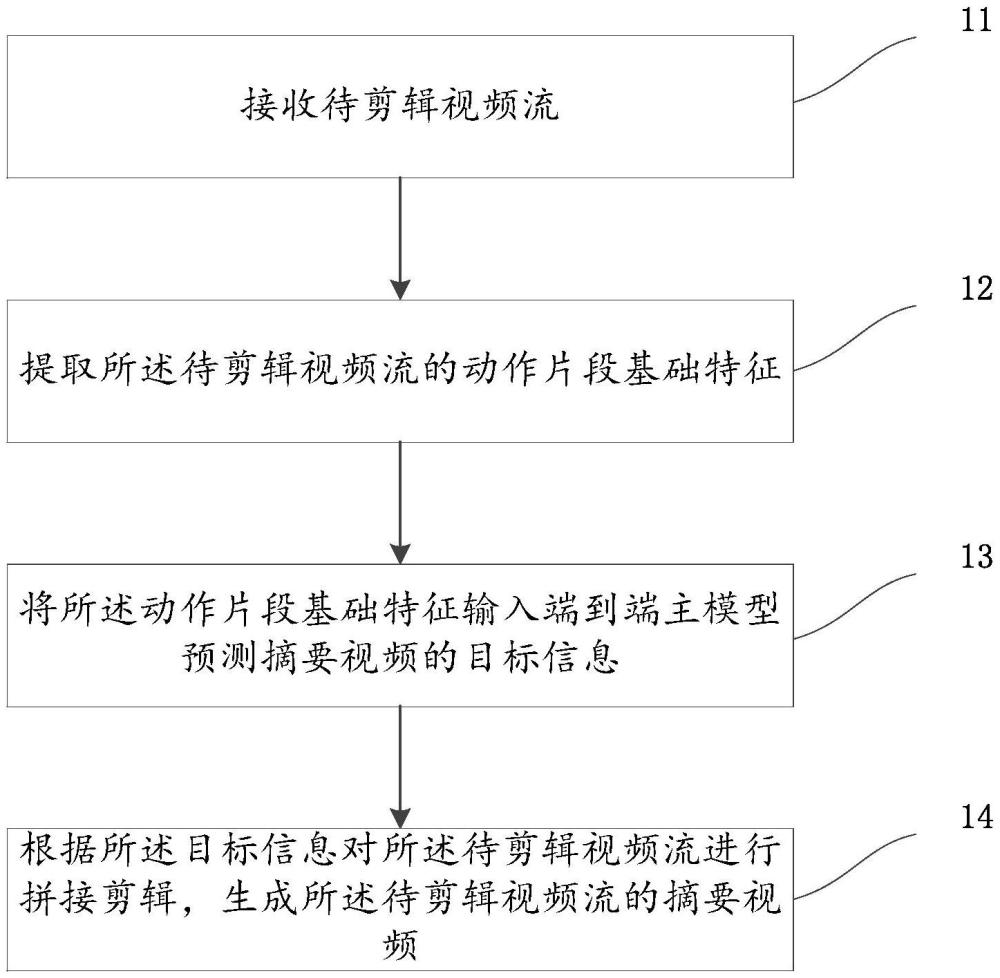
4、接收待剪辑视频流;
5、提取所述待剪辑视频流的动作片段基础特征;
6、将所述动作片段基础特征输入端到端主模型预测摘要视频的目标信息;
7、根据所述目标信息对所述待剪辑视频流进行拼接剪辑,生成所述待剪辑视频流的摘要视频。
8、可选的,所述提取所述待剪辑视频流的动作片段基础特征包括:
9、对所述待剪辑视频流进行预处理,获得多个目标视频片段;
10、将所述多个目标视频片段输入特征提取模型获取所述待剪辑视频流的动作片段基础特征,其中,所述特征提取模对每个所述目标视频片段提取特征向量,将所述多个目标时频片段的特征向量串联为目标特征矩阵,所述目标特征矩阵作为所述待剪辑视频流的动作片段基础特征。
11、可选的,所述端到端主模型包括主干网络、颈部网络和多分支头部网络;
12、所述目标信息包括:所述动作片段的起止时刻点、所述动作片段的动作类别、所述动作片段的关键帧时间位置点和所述关键帧的动作类别;
13、所述将所述动作片段基础特征输入端到端主模型预测摘要视频的目标信息包括:
14、将所述动作片段基础特征输入所述主干网络进行特征提取,得到不同特征尺度的层次特征集合;
15、将所述不同特征尺度的层次特征集合输入所述颈部网络进行特征加强,获得不同特征尺度的层次融合特征;
16、将所述不同特征尺度的层次融合特征输入所述多分支头部网络,预测不同特征尺度下的摘要视频的目标信息。
17、可选的,还包括:
18、训练端对端主模型,其中,所述训练所述端对端主模型包括:
19、接收样本视频流标注的样本动作片段信息;
20、接收预定义的检测锚点信息;
21、根据所述样本动作片段信息和预定义的检测锚点信息,筛选所述样本动作片段的实际标签,所述样本动作片段的实际标签用于优化所述端到端主模型。
22、可选的,所述样本动作片段信息包括:所述样本动作片段的时间点信息、所述样本动作片段的动作类别,所述样本动作片段至少包括一个动作类别;
23、所述检测锚点信息包括:锚点索引、锚点步长、最小偏移量和最大偏移量;
24、所述根据所述样本动作片段信息和预定义的检测锚点信息,筛选所述样本动作片段的实际标签,所述样本动作片段的实际标签用于优化所述端到端主模型包括:
25、计算所述样本动作片段的时间点信息与所述锚点索引对应的偏移量;
26、将超出所述最小偏移量和最大偏移量范围的锚点索引过滤,得到第一锚点索引;
27、根据所述样本动作片段的动作类别标记所述样本动作片段所在的第一锚点索引的动作类别,将所述第一锚点索引的动作类别作为所述样本动作片段的标准动作类别;
28、将所述第一锚点索引与所述样本动作片段的起止时刻偏移量,作为所述样本动作片段的标准起止时刻点;
29、将所述样本动作片段的标准动作类别和标准起止时刻点,作为所述样本动作片段的实际标签,所述样本动作片段的实际标签用于优化所述端到端主模型。
30、可选的,还包括:
31、训练端对端主模型,其中,所述训练所述端对端主模型包括:
32、接收样本视频流标注的样本关键帧信息;
33、接收预定义的检测锚点信息;
34、根据所述样本关键帧信息和预定义的检测锚点信息,筛选所述样本关键帧的实际标签,所述样本关键帧的实际标签用于优化所述端到端主模型。
35、可选的,所述样本关键帧信息包括:所述样本关键帧的时间点信息、所述样本关键帧的动作类别;
36、所述检测锚点信息包括:锚点索引、锚点步长、最小偏移量和最大偏移量;
37、所述根据所述样本关键帧信息和预定义的检测锚点信息,筛选所述样本关键帧的实际标签,所述样本关键帧的实际标签用于优化所述端到端主模型包括:
38、计算所述样本关键帧的时间点信息与所述锚点索引对应的偏移量;
39、将超出所述最小偏移量和最大偏移量范围的锚点索引过滤,得到第二锚点索引;
40、根据所述样本关键帧的动作类别标记所述样本关键帧所在的第二锚点索引的动作类别,将所述第二锚点索引的动作类别作为所述样本关键帧的标准动作类别;
41、将所述第二锚点索引与所述样本关键帧的时间位置偏移量,作为样本动作片段的标准时间位置;
42、将所述样本关键帧的标准动作类别和标准时间位置,作为所述样本关键帧的实际标签,所述样本关键帧的实际标签用于优化所述端到端主模型。
43、第二方面,本申请实施例提供了一种电子设备,包括:处理器、存储器及存储在所述存储器上并可在所述处理器上运行的程序,所述程序被所述处理器执行时实现如上述第一方面所述的视频剪辑方法的步骤。
44、第三方面,本申请实施例提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上述第一方面所述的视频剪辑方法的步骤。
45、第四方面,提供一种计算机程序产品,包括计算机指令,该计算机指令被处理器执行时实现如第一方面所述的视频剪辑方法的步骤。
46、本申请实施例,通过接收待剪辑视频流,并提取所述待剪辑视频流的动作片段基础特征,再将所述动作片段基础特征输入端到端主模型预测摘要视频的目标信息,最后根据所述目标信息对所述待剪辑视频流进行拼接剪辑,生成所述待剪辑视频流的摘要视频。本申请实施例使得在进行动作视频摘要智能剪辑的过程中可直接根据关键帧或动作片段进行合成得到摘要视频,减少了人工干预的过程,并且无需使用多个深度学习网络模型对时间节点和动作信息分别进行预测,用一个端到端主模型能够进行直接预测,提高预测的计算效率;还能同时实现视频剪辑和视频摘要生成,有效提高视频处理的效率。
技术特征:
1.一种视频剪辑方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述提取所述待剪辑视频流的动作片段基础特征包括:
3.根据权利要求1所述的方法,其特征在于,所述端到端主模型包括主干网络、颈部网络和多分支头部网络;
4.根据权利要求1所述的方法,其特征在于,还包括:
5.根据权利要求4所述的方法,其特征在于,所述样本动作片段信息包括:所述样本动作片段的时间点信息、所述样本动作片段的动作类别,所述样本动作片段至少包括一个动作类别;
6.根据权利要求1所述的方法,其特征在于,还包括:
7.根据权利要求6所述的方法,其特征在于,所述样本关键帧信息包括:所述样本关键帧的时间点信息、所述样本关键帧的动作类别;
8.一种电子设备,其特征在于,包括:处理器、存储器及存储在所述存储器上并可在所述处理器上运行的程序,所述程序被所述处理器执行时实现如权利要求1至7中任一项所述的视频剪辑方法的步骤。
9.一种计算机可读存储介质,其特征在于,计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至7中任一项所述的视频剪辑方法的步骤。
10.一种计算机程序产品,其特征在于,包括计算机指令,所述计算机指令被处理器执行时实现如权利要求1至7中任一项所述的视频剪辑方法的步骤。
技术总结
本申请提供一种视频剪辑方法、设备、介质和程序产品,该方法包括:接收待剪辑视频流;提取所述待剪辑视频流的动作片段基础特征;将所述动作片段基础特征输入端到端主模型预测摘要视频的目标信息;根据所述目标信息对所述待剪辑视频流进行拼接剪辑,生成所述待剪辑视频流的摘要视频。本申请在动作视频摘要智能剪辑的过程中可直接根据关键帧或动作片段进行合成得到摘要视频,减少了人工干预的过程,并且用一个端到端主模型能够进行直接预测,提高预测的计算效率;还能同时实现视频剪辑和视频摘要生成,有效提高视频处理的效率。
技术研发人员:琚彬,欧阳谷
受保护的技术使用者:咪咕文化科技有限公司
技术研发日:
技术公布日:2024/10/24
- 还没有人留言评论。精彩留言会获得点赞!