基于大模型的数字人直播方法、装置、设备以及存储介质与流程
本公开涉及人工智能,尤其涉及生成式大模型、自然语言处理、机器学习与信息检索等。
背景技术:
1、当前直播是重要新媒体形式,常见的直播形式是真人直播。伴随着人工智能(ai)的到来,出现了数字人直播。数字人是运用数字技术创造出来的、与人类形象接近的数字化人物形象。数字人也可以称为虚拟形象、数字虚拟人、虚拟数字人等。通过数字人直播可以长时间连播,解放直播的人力。但是数字人直播的通常直播内容比较固定,难以与用户灵活互动。
技术实现思路
1、本公开提供了一种基于大模型的数字人直播方法、装置、设备以及存储介质。
2、根据本公开的一方面,提供了一种基于大模型的数字人直播方法,包括:
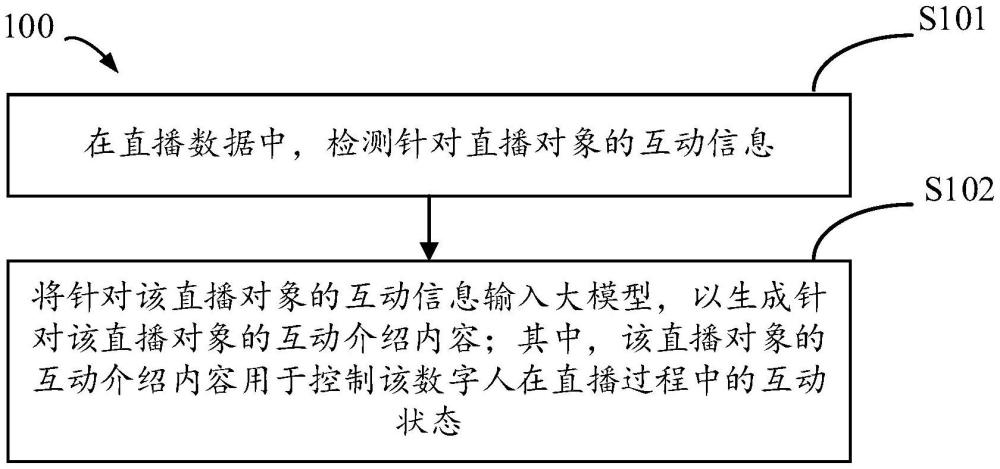
3、在直播数据中,检测针对直播对象的互动信息;
4、将针对该直播对象的互动信息输入大模型,以生成针对该直播对象的互动介绍内容;其中,该直播对象的互动介绍内容用于控制该数字人在直播过程中的互动状态。
5、根据本公开的另一方面,提供了一种基于大模型的数字人直播装置,包括:
6、检测模块,用于在直播数据中,检测针对直播对象的互动信息;
7、第一生成模块,用于将针对该直播对象的互动信息输入大模型,以生成针对该直播对象的互动介绍内容;其中,该直播对象的互动介绍内容用于控制该数字人在直播过程中的互动状态。
8、根据本公开的另一方面,提供了一种电子设备,包括:
9、至少一个处理器;以及
10、与该至少一个处理器通信连接的存储器;其中,
11、该存储器存储有可被该至少一个处理器执行的指令,该指令被该至少一个处理器执行,以使该至少一个处理器能够执行本公开实施例中任一的方法。
12、根据本公开的另一方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,该计算机指令用于使该计算机执行根据本公开实施例中任一的方法。
13、根据本公开的另一方面,提供了一种计算机程序产品,包括计算机程序,该计算机程序在被处理器执行时实现根据本公开实施例中任一的方法。
14、根据本公开,大模型可以基于直播数据中针对直播对象的互动信息生成针对直播对象的互动介绍内容,从而使得数字人能够在直播过程中及时且精准的互动。
15、应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。
技术特征:
1.一种基于大模型的数字人直播方法,包括:
2.根据权利要求1所述的方法,其中,将针对所述直播对象的互动信息输入大模型,以生成针对所述直播对象的互动介绍内容,包括:
3.根据权利要求2所述的方法,其中,所述生成所述提示词所用的工具集包括以下一项或多项:向量物料;应用程序编程接口api物料;定制技能。
4.根据权利要求2或3所述的方法,其中,所述大语言模型是基于情绪特征训练数据对初始大模型微调得到的;所述直播对象介绍内容中的介绍语音内容带有与所述意图识别结果关联的情绪特征。
5.根据权利要求2至4中任一项所述的方法,还包括:
6.根据权利要求5所述的方法,其中,所述直播脚本还包括:开场内容和结束内容;其中,所述开场内容包括一条或多条开场语,所述结束内容包括一条或多条结束语。
7.根据权利要求1至6中任一项所述的方法,还包括:
8.一种基于大模型的数字人直播装置,包括:
9.根据权利要求8所述的装置,其中,所述第一生成模块,包括:
10.根据权利要求9所述的装置,其中,所述生成所述提示词所用的工具集包括以下一项或多项:向量物料;应用程序编程接口api物料;定制技能。
11.根据权利要求9或10所述的装置,其中,所述大语言模型是基于情绪特征训练数据对初始大模型微调得到的;所述直播对象介绍内容中的介绍语音内容带有与所述意图识别结果关联的情绪特征。
12.根据权利要求9至11中任一项所述的装置,还包括:
13.根据权利要求12所述的装置,其中,所述直播脚本还包括:开场内容和结束内容;其中,所述开场内容包括一条或多条开场语,所述结束内容包括一条或多条结束语。
14.根据权利要求8至13中任一项所述的装置,还包括:
15.一种电子设备,包括:
16.一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行根据权利要求1-7中任一项所述的方法。
17.一种计算机程序产品,包括计算机程序,所述计算机程序在被处理器执行时实现根据权利要求1-7中任一项所述的方法。
18.一种大模型,包括计算机程序,所述大模型在被处理器执行时实现根据权利要求1-7中任一项所述的方法。
技术总结
本公开提供了一种基于大模型的数字人直播方法、装置、设备以及存储介质,涉及人工智能技术领域,尤其涉及生成式大模型、自然语言处理、机器学习与信息检索等技术领域。具体实现方案为:在直播数据中,检测针对直播对象的互动信息;将针对该直播对象的互动信息输入大模型,以生成针对该直播对象的互动介绍内容;其中,该直播对象的互动介绍内容用于控制该数字人在直播过程中的互动状态。根据本公开,大模型可以基于直播数据中针对直播对象的互动信息生成针对直播对象的互动介绍内容,从而使得数字人能够在直播过程中及时且精准的互动。
技术研发人员:常学奕
受保护的技术使用者:百度时代网络技术(北京)有限公司
技术研发日:
技术公布日:2024/12/30
- 还没有人留言评论。精彩留言会获得点赞!