一种优化大规模HDFS存储系统无缝升级的方法及系统与流程
本发明涉及大规模hdfs存储系统升级领域,尤其是一种优化大规模hdfs存储系统无缝升级的方法及系统。
背景技术:
1、在大数据规模的hdfs存储系统升级过程中会面临一些挑战:
2、1、datanode服务停止带来的数据丢失风险。
3、在升级过程中,需要对各个节点的操作系统或软件版本进行更新,必然会导致datanode服务的停止。尽管hdfs通过机架感知和三副本机制来保证数据的可用性,但由于以下原因,仍然存在数据丢失的风险。
4、(1)逐台升级时间过长:逐台升级虽然不会有数据丢失风险,但逐台对存储服务器进行升级和重启的方式非常耗时,特别是在大规模集群中(例如拥有数千台节点)。这种方式不具备可行性,因为会显著拖慢升级进程。
5、(2)以机架为单位升级的风险:如果以机架为单位进行升级,当一个机架中的两个副本同时不可用时,剩余的第三个副本一旦发生故障,就会导致数据的永久丢失。
6、2、大量数据块复制操作导致的性能和资源负担。
7、在升级过程中,当hdfs检测到大量datanode服务停止时,会触发数据块的复制操作。这带来了以下问题:
8、(1)网络和存储资源消耗:大量数据块的复制会显著增加网络带宽和存储资源的消耗,尤其是在升级期间。这可能导致网络拥塞和存储设备过载,进一步影响到其他正常运行的服务。
9、(2)集群性能下降:数据块复制操作还会对集群的整体性能和响应时间产生负面影响,使得升级过程变得更加缓慢,影响到集群的可用性和用户体验。
技术实现思路
1、为解决大数据规模的hdfs存储系统升级过程中存在的上述问题,本发明提供一种优化大规模hdfs存储系统无缝升级的方法及系统,通过自定义开发新的副本放置策略,确保数据块的三副本分布在三个不同机架上,减少数据丢失风险;标记datanode的短暂停止状态以避免不必要的副本复制,并通过分级复制和渐进式数据迁移策略,保障系统在升级过程中的高可用性和性能稳定性,以实现大规模hdfs存储系统的无缝升级。
2、为设计上述目的,本发明采用下述技术方案:
3、在本发明一实施例中,提出了一种优化大规模hdfs存储系统无缝升级的方法,该方法包括:
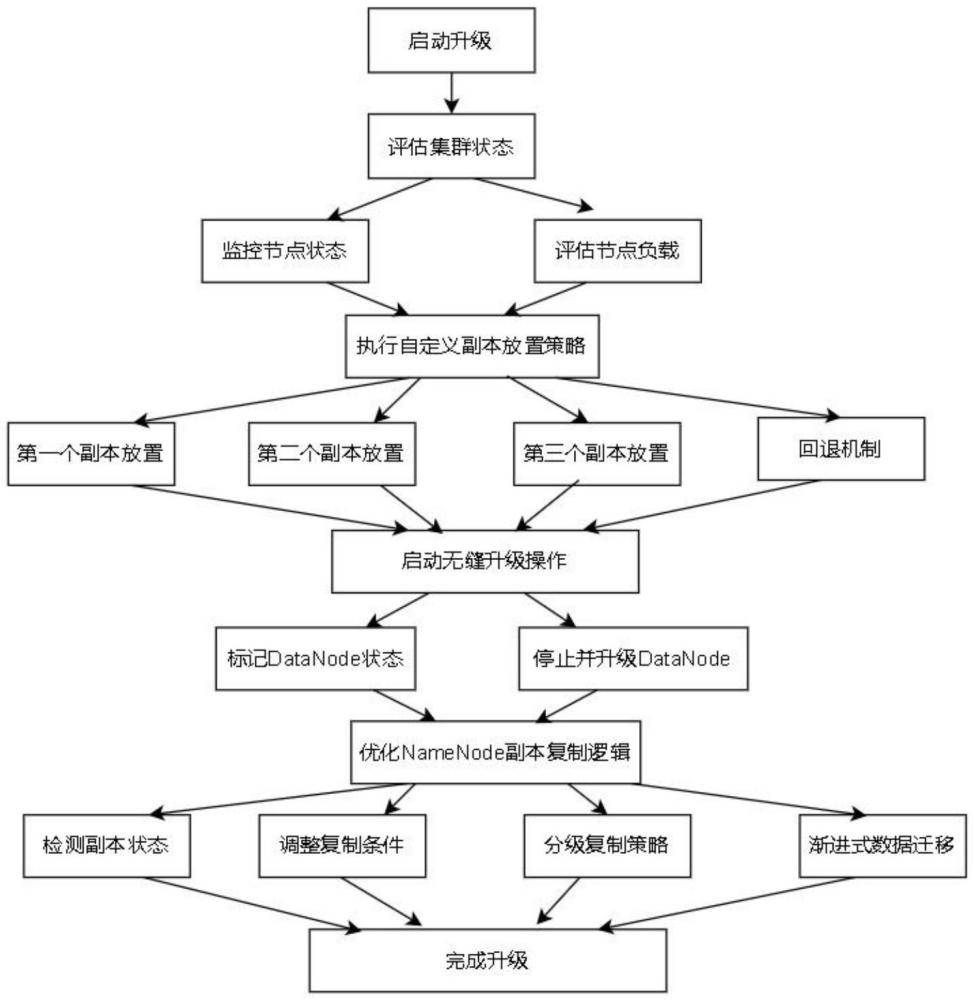
4、自定义新的副本放置策略,使每个数据块的三副本自动分布在集群中三个不同的机架上;在集群状态发生变化时,自动调整副本放置策略;
5、优化namenode的副本复制逻辑,使其识别datanode在升级期间的预期短暂停止状态;在预期短暂停止期间,根据不同场景的严重性,实施分级复制策略,并结合渐进式数据迁移策略。
6、进一步地,自定义新的副本放置策略,包括:
7、第一个副本选择:放置在与数据写入节点相同的机架上;
8、第二个副本选择:从与第一个副本不同的机架中选择一个负载较低的节点;
9、第三个副本选择:从与前两个副本所在机架不同的第三个机架中选择一个负载较低的节点;
10、回退机制:当集群中只有两个机架时,将两个副本放在一个机架,另一个副本放在另一个机架。
11、进一步地,根据实时收集的节点状态信息,评估节点负载和可用资源,动态选择最适合存放副本的节点;结合网络拓扑信息优化节点选择;
12、定期检查和评估集群中各个节点的负载分布情况,判断是否需要触发副本再分布操作;在再分布操作中,仍然遵循三副本分布在三个不同机架上的原则。
13、进一步地,当集群在升级期间停用某个datanode时,可预先将该节点标记为预期短暂停止状态;
14、namenode在触发副本复制之前,检查节点是否处于预期短暂停止状态;
15、在namenode实施副本复制时,优先选择分布在低负载机架或节点上的副本进行迁移。
16、在本发明一实施例中,还提出了一种优化大规模hdfs存储系统无缝升级的系统,该系统包括:
17、副本放置策略自定义模块,用于自定义新的副本放置策略,使每个数据块的三副本自动分布在集群中三个不同的机架上;在集群状态发生变化时,自动调整副本放置策略;
18、副本复制逻辑优化模块,用于优化namenode的副本复制逻辑,使其识别datanode在升级期间的预期短暂停止状态;在预期短暂停止期间,根据不同场景的严重性,实施分级复制策略,并结合渐进式数据迁移策略。
19、进一步地,自定义新的副本放置策略,包括:
20、第一个副本选择:放置在与数据写入节点相同的机架上;
21、第二个副本选择:从与第一个副本不同的机架中选择一个负载较低的节点;
22、第三个副本选择:从与前两个副本所在机架不同的第三个机架中选择一个负载较低的节点;
23、回退机制:当集群中只有两个机架时,将两个副本放在一个机架,另一个副本放在另一个机架。
24、进一步地,根据实时收集的节点状态信息,评估节点负载和可用资源,动态选择最适合存放副本的节点;结合网络拓扑信息优化节点选择;
25、定期检查和评估集群中各个节点的负载分布情况,判断是否需要触发副本再分布操作;在再分布操作中,仍然遵循三副本分布在三个不同机架上的原则。
26、进一步地,当集群在升级期间停用某个datanode时,可预先将该节点标记为预期短暂停止状态;
27、namenode在触发副本复制之前,检查节点是否处于预期短暂停止状态;
28、在namenode实施副本复制时,优先选择分布在低负载机架或节点上的副本进行迁移。
29、在本发明一实施例中,还提出了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时设计前述优化大规模hdfs存储系统无缝升级的方法。
30、在本发明一实施例中,还提出了一种计算机可读存储介质,计算机可读存储介质存储有执行优化大规模hdfs存储系统无缝升级的方法的计算机程序。
31、有益效果:
32、1、本发明通过自定义开发新的副本放置策略,这种策略极大降低了由于机架级故障可能导致的数据丢失风险,提升了数据的可靠性和安全性。
33、2、本发明支持在集群状态发生变化时(如节点故障或机架负载波动),自动调整副本放置策略。这种灵活的应对机制确保了系统能够在不同的运行条件下始终保持高效和稳定。
34、3、本发明优化namenode的副本复制逻辑,使其能够识别datanode在升级期间的状态,避免了不必要的副本复制操作,从而减轻了系统负载。
35、4、本发明根据场景严重性实施分级复制策略,结合渐进式数据迁移方式,有效减少了网络和存储资源的消耗,确保了数据的高可用性和系统的整体性能。
技术特征:
1.一种优化大规模hdfs存储系统无缝升级的方法,其特征在于,该方法包括:
2.根据权利要求1所述的优化大规模hdfs存储系统无缝升级的方法,其特征在于,自定义新的副本放置策略,包括:
3.根据权利要求1所述的优化大规模hdfs存储系统无缝升级的方法,其特征在于,根据实时收集的节点状态信息,评估节点负载和可用资源,动态选择最适合存放副本的节点;结合网络拓扑信息优化节点选择;
4.根据权利要求1所述的优化大规模hdfs存储系统无缝升级的方法,其特征在于,当集群在升级期间停用某个datanode时,可预先将该节点标记为预期短暂停止状态;
5.一种优化大规模hdfs存储系统无缝升级的系统,其特征在于,该系统包括:
6.根据权利要求5所述的优化大规模hdfs存储系统无缝升级的装置,其特征在于,自定义新的副本放置策略,包括:
7.根据权利要求5所述的优化大规模hdfs存储系统无缝升级的装置,其特征在于,根据实时收集的节点状态信息,评估节点负载和可用资源,动态选择最适合存放副本的节点;结合网络拓扑信息优化节点选择;
8.根据权利要求5所述的优化大规模hdfs存储系统无缝升级的装置,其特征在于,当集群在升级期间停用某个datanode时,可预先将该节点标记为预期短暂停止状态;
9.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时设计权利要求1-4任一项所述方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有执行权利要求1-4任一项所述方法的计算机程序。
技术总结
本发明公开一种优化大规模HDFS存储系统无缝升级的方法及系统,其中,该方法包括:自定义新的副本放置策略,使每个数据块的三副本自动分布在集群中三个不同的机架上;在集群状态发生变化时,自动调整副本放置策略;优化NameNode的副本复制逻辑,使其识别DataNode在升级期间的预期短暂停止状态;在预期短暂停止期间,根据不同场景的严重性,实施分级复制策略,并结合渐进式数据迁移策略。该方法及系统通过自定义新的副本放置策略,确保数据块的三副本分布在三个不同机架上,减少数据丢失风险;标记DataNode的短暂停止状态以避免不必要的副本复制,并通过分级复制和渐进式数据迁移策略,保障系统在升级过程中的高可用性和性能稳定性,以实现大规模HDFS存储系统的无缝升级。
技术研发人员:张强
受保护的技术使用者:中盈优创资讯科技有限公司
技术研发日:
技术公布日:2025/2/20
- 还没有人留言评论。精彩留言会获得点赞!