一种基于强化学习的聚变等离子体环电压控制方法与流程
本发明涉及聚变等离子体控制,尤其涉及一种基于强化学习的聚变等离子体环电压控制方法。
背景技术:
1、托卡马克装置是用于研究和实现核聚变反应的重要设备,其工作原理是通过强磁场约束高温等离子体,使其在高温高压状态下进行核聚变反应。托卡马克系统的控制对于实现稳定的等离子体状态和有效的核聚变反应至关重要。在托卡马克控制系统中,vloop是一个关键参数,它直接影响等离子体的稳定性和约束效果。
2、托卡马克系统的控制存在以下缺点:
3、(1)非线性响应不足:托卡马克系统具有高度非线性和复杂的动态特性,传统的vloop控制通常采用pid控制器,但这种方法难以在各种运行条件下保持良好的控制效果,导致控制精度和稳定性不足。
4、(2)参数调整依赖经验:pid控制器的参数需要通过人工经验进行手动调整,缺乏自动调节能力,难以适应托卡马克环境中的快速变化和复杂条件。
5、(3)短期优化局限:pid控制器主要关注当前时刻的误差调整,无法优化长周期的控制性能,导致系统的长期稳定性和优化效果受限。
6、(4)高维状态处理困难:托卡马克vloop控制涉及多个高维状态参数,传统pid控制器难以同时处理这些复杂的参数,导致整体控制效果不理想。
7、综上,本申请提出一种基于强化学习的聚变等离子体环电压控制方法。
技术实现思路
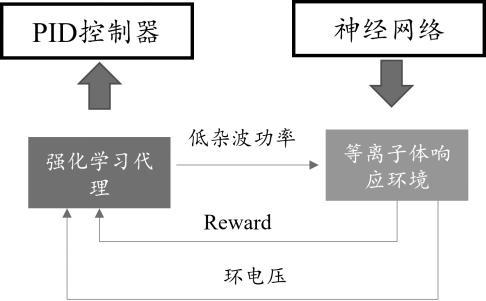
1、本发明的目的是针对背景技术中存在托卡马克vloop控制在非线性和复杂动态环境中的控制效果一般的问题,提出一种基于强化学习的聚变等离子体环电压控制方法。
2、本发明的技术方案:一种基于强化学习的聚变等离子体环电压控制方法,包括以下步骤:
3、选择训练模型的数据:在托卡马克聚变等离子体背景下,将当前时刻的等离子体参数作为输入,输出为下一时刻的vloop;
4、构建数据库:收集运行托卡马克装置放电数据以及未来装置前期的放电数据,作为构建模型的初始训练数据;
5、构建神经网络模型:采用长短期记忆神经网络作为训练模型,lstm神经网络的层数、神经元数量根据具体训练过程确定;
6、神经网络模型的训练:基于主流框架搭建模型并进行训练,根据预测结果调节网络结构;
7、神经网络模型测试:准备除训练数据外的新数据用于模型测试,通过对比预测结果和真实结果的差别判断模型是否有效,进行多步推理验证,并保证该过程预测结果与实验数据保持一致;
8、构建强化学习模型:采用近端策略优化算法;
9、强化学习训练:将训练好的响应模型作为强化学习的交互环境,根据lhw的能力设置探索范围,在规定范围内找到最优控制命令;
10、强化学习模型测试:对当前状态添加一定噪声,基于当前状态利用强化学习控制器给出控制命令,将控制命令输入到响应环境中,查看控制效果;
11、替换当前环电压控制器:在满足控制要求后,将训练好的模型替换传统的vloop控制算法,通过实时采集信号,根据vloop控制的需求,实时给出lhw功率信号,实现vloop的精准控制。
12、可选的,所述lstm神经网络是一种特殊类型的循环神经网络(rnn),用于处理序列数据和时间序列任务,通过多个lstm单元的堆叠构成深层网络,每个单元的隐藏状态作为下一个时刻的输入,以有效处理长期依赖关系,捕捉更远处的上下文信息。
13、可选的,所述近端策略优化算法(ppo)的目标是在每次更新策略时最大化性能,并通过限制策略更新的幅度来保证策略优化的稳定性。
14、可选的,所述等离子体参数包括等离子体总电流、纵场线圈电流、pf线圈电流、等离子体电子弦平均密度、极向比压、等离子体内感、储能、等离子体边界、辐射功率、vloop、等离子体边界、辅助加热ecrh功率、辅助加热icrf功率、辅助加热lhw功率。
15、可选的,主流框架为tensorflow框架或pytorch框架。
16、可选的,所述神经网络模型的训练中,预测结果的误差小于3%;
17、可选的,所述构建强化学习模型中,采用策略梯度优化算法。
18、可选的,所述神经网络模型测试中,推理步数为100步。
19、综上所述,本申请包括以下至少一种有益技术效果:
20、(1)提高托卡马克vloop控制算法精度和响应速度:
21、通过引入深度强化学习算法和代理模型,本发明显著提高了托卡马克vloop控制的精度和响应速度。强化学习算法能够在复杂和非线性动态条件下,自适应地调整控制策略,使得vloop能够更精确地跟踪目标值。
22、(2)增强系统的自适应能力:
23、强化学习模型具备自学习和自适应能力,能够根据实时环境变化自动优化控制策略,减少了对人工干预和参数手动调整的依赖。系统能够快速适应不同的操作条件和突发情况,提高了托卡马克控制系统的智能化水平。
24、(3)优化长周期控制效果:
25、通过设计合理的奖励函数,强化学习模型不仅能够优化短期内的控制效果,还能在长周期内保持良好的控制性能。此举显著提升了托卡马克系统中vloop控制方法的长期稳定性和优化效果,确保了持续稳定的核聚变实验条件。
26、(4)高效处理高维状态参数:
27、本发明利用深度神经网络的强大特征提取能力,能够有效处理托卡马克系统中的高维和复杂状态参数,提升了整体控制效果。代理模型能够提供准确的vloop预测,为强化学习控制器提供更精准的依据。
28、(5)减少人工干预和操作成本:
29、由于发明提及基于强化学习的vloop控制方法具备自适应和自动调节能力,减少了对人工干预和操作的需求,降低了操作成本和人力资源投入。控制系统能够自动优化和调整参数,提升了操作的便捷性和效率。
30、(6)推动核聚变研究的进展:
31、本发明的控制方法可推广至聚变领域的其他控制系统,显著提高了托卡马克控制系统的性能,为核聚变实验提供了更加稳定和精确的控制手段。这对实现可控核聚变具有重要意义,推动了核聚变研究的进展,为未来能源发展提供了技术支持。
32、本发明通过引入强化学习算法,替代传统pid控制器,在托卡马克系统中实现更精准、自适应的vloop控制,提高了控制系统的精度、响应速度和长期稳定性,克服了传统控制器在非线性和复杂动态环境中的不足。
技术特征:
1.一种基于强化学习的聚变等离子体环电压控制方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于强化学习的聚变等离子体环电压控制方法,其特征在于,所述lstm神经网络是一种特殊类型的循环神经网络(rnn),用于处理序列数据和时间序列任务,通过多个lstm单元的堆叠构成深层网络,每个单元的隐藏状态作为下一个时刻的输入,以有效处理长期依赖关系,捕捉更远处的上下文信息。
3.根据权利要求1所述的基于强化学习的聚变等离子体环电压控制方法,其特征在于,所述近端策略优化算法(ppo)的目标是在每次更新策略时最大化性能,并通过限制策略更新的幅度来保证策略优化的稳定性。
4.根据权利要求1所述的一种基于强化学习的聚变等离子体环电压控制方法,其特征在于,所述等离子体参数包括等离子体总电流、纵场线圈电流、pf线圈电流、等离子体电子弦平均密度、极向比压、等离子体内感、储能、等离子体边界、辐射功率、vloop、等离子体边界、辅助加热ecrh功率、辅助加热icrf功率、辅助加热lhw功率。
5.根据权利要求1所述的一种基于强化学习的聚变等离子体环电压控制方法,其特征在于,主流框架为tensorflow框架或pytorch框架。
6.根据权利要求1所述的一种基于强化学习的聚变等离子体环电压控制方法,其特征在于,所述神经网络模型的训练中,预测结果的误差小于3%。
7.根据权利要求1所述的一种基于强化学习的聚变等离子体环电压控制方法,其特征在于,所述构建强化学习模型中,采用策略梯度优化算法。
8.根据权利要求1所述的一种基于强化学习的聚变等离子体环电压控制方法,其特征在于,所述神经网络模型测试中,推理步数为100步。
技术总结
本发明涉及聚变等离子体控制技术领域,尤其涉及一种基于强化学习的聚变等离子体环电压控制方法。其技术方案包括以下步骤:选择训练模型的数据:在托卡马克聚变等离子体背景下,将当前时刻的等离子体参数作为输入,输出为下一时刻的vloop;构建数据库:收集运行托卡马克装置放电数据以及未来装置前期的放电数据,作为构建模型的初始训练数据。本发明提高托卡马克vloop控制算法精度和响应速度,强化学习模型具备自学习和自适应能力,提升了托卡马克系统中vloop控制方法的长期稳定性和优化效果,提升了整体控制效果,减少了对人工干预和操作的需求,降低了操作成本和人力资源投入,实现可控核聚变具有重要意义。
技术研发人员:刘自结,肖炳甲,黄俊杰,刘少清,郭和茹
受保护的技术使用者:合肥综合性国家科学中心能源研究院(安徽省能源实验室)
技术研发日:
技术公布日:2024/10/31
- 还没有人留言评论。精彩留言会获得点赞!