一种智能导盲眼镜系统及其导盲方法与流程
本发明涉及一智能导盲系统及方法方法,属于导盲领域。
背景技术:
中国是世界盲人最多的国家,约有1200万,占全世界盲人口的18%,作为社会群体中的特殊人群,他们终生生活在无边的黑暗中,因此常常会遇到各种难题,目前市场上的一些导盲用眼镜大多结构简单而功能单一(只能简单提示前方有障碍物),虽然有些产品使用方便,但辅助效果并不明显,而且,盲人朋友在使用时会碰到诸多问题,比如路况不好,坑洼不平,前方有悬挂的障碍物等等,普通的眼镜无法准确的探明,亲属不容易寻找等问题,这些问题是无法解决的。目前现有导盲产品的障碍物探测功能,仅仅局限于利用超声波探测技术对障碍物的距离进行探测,不能对障碍物所在方位进行精确定位,并且只能对单一障碍物进行探测,如在多运动障碍物的探测中,仅仅能够探测到离使用者距离最近的障碍物,因此使得产品的导盲功能实用性大幅度降低。
实际上关于智能导盲眼镜,在国际和国内都有团队和个人进行过研究,但都始终停留在性能检测与可行性论证阶段,至今并未对其进行产品的批量化生产,尤其是在国内,对智能导盲设备的研发更是刚刚处于起步阶段,距大规模产品化,商业化还有很长的一段距离。
如今市场现有的普通拐眼镜的专利虽然有一些,但并没有统一的专业标准,尤其是专门为盲人朋友研究设计的多功能导盲眼镜的专利更是少之又少,而且大多数产品,在实际使用时有很多的缺陷和问题。
目前,在市场上还没有一款实际应用的智能导盲眼镜,大多数还只是停留在研制或者试戴完善上,且功能单一、智能水平较低。谷歌公司于2012年发布了一款“拓展现实”眼镜,它具备和智能手机一样的功能,可以通过声音控制拍照,视频通话,以及网上冲浪、处理文字信息和电子邮件等,但这些功能也只是面向视觉健全人士开发设计的,这也是市场上唯一试发布的初级版本技术,其他的一些导盲眼镜产品都还停留在概念和研发中。所以,迫切需要一种专门为视觉障碍者研制开发的便捷、高效的智能导盲眼镜,及递进识别式方案的方位、测距和物体辨别功能,并且具有定位等一键式完成功能,能与后台云服务器进行时时交互的通信系统,也能为后期不断完善、功能扩展提供广阔的预留空间。
技术实现要素:
本发明的目的在于:提供一种智能导盲眼镜系统及其导盲方法,以解决现有智能导盲眼镜功能单一、智能水平较低的问题。
为解决上述问题,提供一种智能导盲眼镜系统,包括:
图像采集模块,采集使用者周围的环境图像,并将获取的图像上传至中央控制模块;
语音处理模块,与中央控制模块相连,用于使用者与各种功能模块间的人机交互;
4G通信模块,为眼镜端和负责识别测距的云服务器建立实时相互通信,并实现语音通话功能;
中央控制模块,对各功能单元所采集到的数据和信息进行汇总分析,并根据数据所反映的场景,对各个功能模块发出相应的控制指令;对常见物体通过图像模板匹配和视差图进行识别与测距;如无法辨别,再利用4G通信模块发送至云服务器;
云服务器,通过在云服务器上搭建软件平台建立图像分析系统,利用深度学习神经网络,建立图像学习数据库,利用深度学习与双目测距算法,从上传的图像中获取障碍物距离与类别信息,并将信息反馈回中央控制模块;
USB分流模块,用于将图像采集模块和卫星定位模块与中央控制模块相连,实现信息交互传输;
卫星定位模块,与中央控制模块相连,用于卫星定位,4G通信模块还能将GPS获取的经纬度信息通过Internet发送至PC服务器端并接收服务器反馈信息;
本发明还提供一种智能导盲眼镜导盲方法,包括:
通过图像采集模块采集使用者周围的环境图像,获取的图像采用本地-服务器递进识别方案:先由中央控制模块对常见物体通过图像模板匹配和视差图进行识别与测距;如无法辨别,再利用4G通信模块的网络通信功能发送至云服务器,云服务器利用深度学习与双目测距等算法,从上传的图像中获取障碍物距离与类别信息,并将信息以文本格式发送回中央控制模块,再由语音处理模块将其转化成语音信息,通过耳机告知盲人。此外,当使用者急需告知亲友自己当前位置时,卫星定位模块会将使用者目前所在经纬度信息有服务器转换成位置信息,经4G通信模块以短信的方式发送至亲友手机,以便亲友寻人。
所述本地-服务器递进识别方案,即首先在眼镜端中央控制模块上对一些常见障碍物的图片进行特征提取进行机器学习建立匹配模板分类数据库,识别测距功能开启后,中央控制模块先对预处理的图片解压缩,在图片中利用阈值选取方法对物体与背景进行分割,再用Boost方法对背景分割后的目标图像进行特征提取,获取到的目标特征通过SVM法与建立常见物体模板数据库进行匹配,从而获得常见物体的识别结果;若匹配结果相似度低于识别比例,中央控制模块会把预处理后的图像通过4G通信模块传送给云服务器进行识别,云服务器通过建立的深度学习训练过的数据库进行学习识别,根据最高的相似度得出辨别结果。本地识别、测距方式可以节省系统反应时间,服务器方式可以确保不常见物体的准确识别,两种方式的协调运行保证了图像物体识别的实时性、准确性与广泛性等。
图像采集模块为模拟人眼的双目摄像头,经USB分流模块与中央控制模块相连,以模拟人类左右眼视觉成像的原理获取同一景物的两幅图像,获取到的两幅图片是由双目摄像头硬件压缩的jpeg格式,而后传输到中央控制模块,通过两个摄像头所获取的二维图像结合神经网络算法计算出景物的三维信息并提取图片中的主要信息,通过BM算法得出图像视差,它与人类的双眼视觉在原理上比较相像。由于双目摄像可以提供被观察物体的空间立体信息,因而在机器视觉领域有着广泛的应用。同时,双目摄像需进行的各种信号处理涉及了图像处理技术的各个方面,综合性很强。目前,常用的双目机器视觉系统基本上是采用两个视轴平行或固定角度的摄像机来完成图像的采集。这种方式具有结构简单、测量速度快、测量和匹配的精度高等优点。但系统在进行测量之前,需要对摄像机进行严格的参数标定。
双目测距的基本原理如下:
设定人体与物体之间的距离为Z,摄像头的焦距f,两个摄像头的镜头之间的距离为T,物体在两个传感器上所成像xl和xr的距离d,为变量,有:
d=xl-xr
因此,已知d的值,即可根据相似三角形原理求出Z;
在Opencv上实现双目测距,主要步骤为:
①双目校正和标定,获得摄像头的参数矩阵,标定采用的是MATLAB标定工具;
②立体匹配,获得视差图;
③采用BM算法生成视差图,如果左右匹配点比较稠密,匹配点多,得到的图像与原图相似度高,如果匹配点比较稀疏,得到的点与原图相似度低;
④得出测距;
⑤把生成的视差图输入到reprojectImageTo3D()函数,生成3D点云,3D点云中保存有2D图像的三维坐标,再读出每帧图像的三维坐标中的z轴的值,就得出了距离数据;
⑥结果分析。
目标障碍物方位辨别:在Opencv环境下,通过阈值选取法得到去背景的目标图片,并对该图片整个区域建立坐标进行区域划分,划分为三个区域,分别为左前、前方、右前方;同时,在去除背景的目标图片基础上根据目标具体形状生成目标对应的轮廓框图,再根据该框图,利用几何原理计算出目标轮廓框图的几何中心点;中心点和区域划分完成后,根据目标轮廓中心点位于区域划分图中的具体区域来得出该目标当前相对于摄像头的具体方位。
双目摄像头和卫星定位模块分别经USB分流模块与中央控制模块连接,USB分流模块为FE1.1s,FE1.1s是高度集成,高质量,高性能,低能耗,同时还是USB2.0高速4端口集线的低成本解决方案。它采用单个交换转换器(Single Transaction Translator)(STT)构建以便获得更多的效益。六个而不是两个非周期转换缓存以减少潜在的通信干扰。整个设计基于状态机控制,以减小响应的延迟时间;在此芯片中未使用微型控制器。为保障高质量,整个芯片通过测试扫描链(Test Scan Chain)–即使在高速(480MHz)模式下,使所有的逻辑元件在装运前被充分测试。特别是内建自检(Build-In-Self-Test)模式目的在于使用所有的高速,全速,以及低速模式模拟前端端口(AFE)在封装和测试阶段也是如此。低能耗的实现是通过使用0.18m技术以及集成的电源/时钟控制机制。大部分引脚不需要计时,除非被用到;
语音处理模块,该模块包括语音处理芯片SYN6288,主要功能就是实现使用者与各种功能模块间的人机交互,当使用者距离障碍物的距离低于预警阈值时,中央控制模块会向该模块发出播报指令,该模块则将得到的数据进行处理,并通过外放喇叭或耳机设备进行播报,告知使用者前方障碍物的类别、方位和距离,例如“右前方2.3米处有车辆”,使得使用者可以进行避障调整。当使用者想知道当前位置时,可以触发定位按钮,通过语音播报当前的地理位置信息。
卫星定位系统即全球定位系统Global Positioning System,就是使用卫星对某物进行准确定位的技术。可以保证在任意时刻,地球上任意一点都可以同时观测到4颗卫星,以便实现导航、定位、授时等功能。具有的全天候、高精度和自动测量的特点,作为先进的测量手段和新的生产力,已经融入了国民经济建设、国防建设和社会发展的各个应用领域。卫星定位系统的工作原理是测量出已知位置的卫星到用户接收机之间的距离,然后综合多颗卫星的数据即知道接收机的具体位置。
GPS在本技术中的应用,主要是使眼镜具有精确的卫星定位功能,其实现方式是将眼镜作为Socket通信的客户端,把GPS获取的经纬度信息利用4G通信模块通过TCP/IP协议在Internet上传递给PC机服务器端,而后PC服务器再将得到的经纬度信息通过百度地图API进行经纬度与位置信息的匹配,从而得知使用者所在位置,最后PC服务器端再将位置信息通过互联网发送回中央控制模块。
当使用者需要了解当前所在位置时或者想让家人及朋友能够了解自己当前所在具体地理位置时,触发开关,4G通信模块即将位置信息以短信的方式发送至亲人手机。
网络通信功能的实现,利用了4G通信模块的无线宽带网络接入功能,该模块的功能是负责眼镜端与各功能云服务器平台间通信链路的建立,其中之一,是将眼镜端与负责识别测距的云服务器建立实时相互通信,并实现语音通话功能,以方便其家人及时了解使用者当前身体状况;其二,无线通信模块不仅实现了与家人联系的功能,还实现了将GPS获取的经纬度信息通过Internet发送至PC服务器端并接收服务器反馈信息的网络通信功能,而这一功能也是卫星定位环节中至关重要的环节。
4G通信模块由USB接口与中央控制模块相连,USB主线总线信号为4个模块与系统之间的通讯接口。根据Linux3.2.0内核的自带的ECM口驱动对ME3760_V2模块进行加载,使用的是ME3760_V2模块的USB口进行连接,在Linux下,ME3760_V2模块的ECM口被映射成5个接口:ECM、\、AT、Modem、Log(下文有详细介绍),其中“\”也属于ECM口的一部分,为防止ECM功能被覆盖,在进行USB串口初始化时应将其过滤,并加载Linux内核的PPP驱动,使其余的接口初始化为USB串口设备,最后用PPP工具拨号连接4G网络。
技术实现步骤:
1.在Linux下ME3760_V2模块的USB口被映射成5个接口:ECM、/、AT、Modem和Log;
2.内核修改,在原有的Linux版本的基础上添加ME3760_V2模块的驱动,如:添加设备信息、USB串口驱动过滤ECM接口;
3.内核编译;
4.设备加载,ME3760_V2模块的ECM口在系统中被映射成网口eth0,其中AT/Modem/Log口在系统中被映射为ttyUSB0-ttyUSB2;
5.建立4G连接,利用AT指令,使用PPP拨号,并静态设置eth0的IP和网关DNS或者使用PPP拨号,就能使用4G网络了。
中央控制模块,该模块主要实现对整个眼镜各个部分功能单元所采集到的数据和信息进行汇总分析,并根据数据所反映的场景,对各个功能模块发出相应的控制指令。
为了使各个模块运行效率更高、性能更稳定、实时性能更强,团队专门为核心板搭载了LINUX PDA操作系统,而其在本设计中的主要功能体现在以下的几个方面:
在双目摄像头的图像采集的控制中,预先在TQ210_COREB核心板中用程序设定一个图像采集频率,并实时将采集完的图像压缩并发送给后台服务器,核心板时时接收后台服务器传递过来的图像分析结果信息。
在本地-服务器递进识别方案的眼镜端,首先在搭载了精简Linux操作系统的A8上,利用Opencv平台对常见物体用Boost方法进行特征提取,并对提取的特征运用机器学习建立匹配模板数据库。识别测距功能开启后,眼镜端先对预处理的图片解压缩,在图片中对物体与背景进行分割,再对背景分割后的目标图像进行特征提取,获取到的目标特征再利用SVM方法与建立常见物体模板数据库进行匹配,从而获得常见物体的识别结果;若匹配结果相似度低于识别比例,眼镜端会把预处理后的图像通过4G网络传送给云服务器进行识别。
在对语音处理模块的控制中,预先在后台服务器分析程序中设置有预警阈值,当探测到的物体距离小于预警阈值时,核心板将接收到的文本信息经过语音模块处理后得到的各种功能的语音片段,以外放喇叭或者耳机的形式传递给使用者,当探测物体距离大于预警阈值时,停止播报。
当使用者处于迷路或是急需得到亲人朋友的帮助时,通过触按位置信息发送按键,主控系统得到触发信号后,会采用中断方式,控制卫星定位模块确定当前位置的经纬度信息,然后再由中央控制模块将经纬度信息转换为具体的地理位置信息,最后通过4G通信模块将其发送至预存的家人手机号码,以方便家人了解其当前所在位置,进行寻人。
深度学习原理:深度学习在训练数据库时,需要提供强大的计算能力,并且需要存储大量的训练数据,鉴于云服务器有以上优势和特性,遂决定采用云服务器作为图像识别处理系统的软件平台。深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
与现有技术相比,本发明是专门为视觉障碍者研制开发的便捷、高效的智能导盲眼镜,具有递进识别式方案的方位、测距和物体辨别功能,并且具有定位等一键式完成功能,能与后台云服务器进行时时交互的通信系统,也能为后期不断完善、功能扩展提供广阔的预留空间;利用机器视觉、数字图像处理与识别、深度学习、计算机网络等前沿技术,实现了对佩戴者前方障碍物的类别、方位、距离的综合探测及提示,卫星定位、语音播报、4G网络通信和一键式短信联系家人等功能,本地识别、测距方式可以节省系统反应时间,服务器方式可以确保不常见物体的准确识别,两种方式的协调运行保证了图像物体识别的实时性、准确性与广泛性等,具有十分广阔的应用前景。
附图说明
图1是智能导盲眼镜硬件系统框图;
图2是智能导盲眼镜系统运行流程图;
图3是双目测距原理图;
图4是语音处理模块控制框图;
图5是卫星定位模块的定位流程图;
图6是眼镜端障碍物识别、方位和距离实现过程图;
图7是含多个隐层的深度学习模型图;
图8是layer-wise的训练机制图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将对本发明作进一步地详细描述,
实施例:
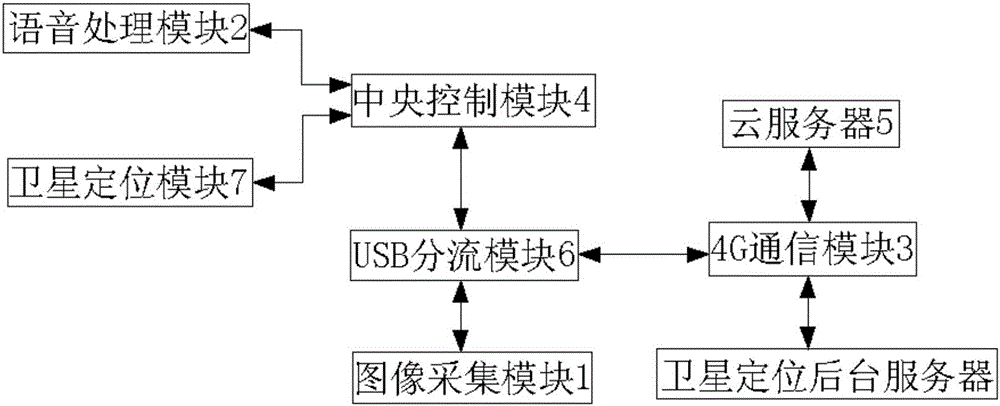
参照图1和图2,本实施例提供一种智能导盲眼镜系统,包括:
图像采集模块1,采集使用者周围的环境图像,并将获取的图像上传至中央控制模块4;
语音处理模块2,与中央控制模块4相连,用于使用者与各种功能模块间的人机交互;
4G通信模块3,为眼镜端和负责识别测距的云服务器5建立实时相互通信,并实现语音通话功能;
中央控制模块4,对各功能单元所采集到的数据和信息进行汇总分析,并根据数据所反映的场景,对各个功能模块发出相应的控制指令;对常见物体通过图像模板匹配和视差图进行识别与测距;如无法辨别,再利用4G通信模块3发送至云服务器5;
云服务器5,通过在云服务器上搭建软件平台建立图像分析系统,利用深度学习神经网络,建立图像学习数据库,利用深度学习与双目测距算法,从上传的图像中获取障碍物距离与类别信息,并将信息反馈回中央控制模块4;
USB分流模块6,用于将图像采集模块1和卫星定位模块4与中央控制模块4相连,实现信息交互传输;
卫星定位模块7,与中央控制模块4相连,用于卫星定位,4G通信模块3还能将GPS获取的经纬度信息通过Internet发送至PC服务器端并接收服务器反馈信息;
上述智能导盲眼镜的导盲方法如下:
通过图像采集模块1采集使用者周围的环境图像,获取的图像采用本地-服务器递进识别方案:先由中央控制模块4对常见物体通过图像模板匹配和视差图进行识别与测距;如无法辨别,再利用4G通信模块3的网络通信功能发送至云服务器5,云服务器5利用深度学习与双目测距等算法,从上传的图像中获取障碍物距离与类别信息,并将信息以文本格式发送回中央控制模块4,再由语音处理模块2将其转化成语音信息,通过耳机告知盲人。此外,当使用者急需告知亲友自己当前位置时,卫星定位模块7会将使用者目前所在经纬度信息有服务器转换成位置信息,经4G通信模块3以短信的方式发送至亲友手机,以便亲友寻人。
本地-服务器递进识别方案,即首先在眼镜端中央控制模块4上对一些常见障碍物的图片进行特征提取进行机器学习建立匹配模板分类数据库,识别测距功能开启后,中央控制模块4先对预处理的图片解压缩,在图片中利用阈值选取方法对物体与背景进行分割,再用Boost方法对背景分割后的目标图像进行特征提取,获取到的目标特征通过SVM法与建立常见物体模板数据库进行匹配,从而获得常见物体的识别结果;若匹配结果相似度低于识别比例,中央控制模块4会把预处理后的图像通过4G通信模块3传送给云服务器5进行识别,云服务器5通过建立的深度学习训练过的数据库进行学习识别,根据最高的相似度得出辨别结果。本地识别、测距方式可以节省系统反应时间,服务器方式可以确保不常见物体的准确识别,两种方式的协调运行保证了图像物体识别的实时性、准确性与广泛性等。
图像采集模块1为模拟人眼的双目摄像头,经USB分流模块6与中央控制模块4相连,以模拟人类左右眼视觉成像的原理获取同一景物的两幅图像,获取到的两幅图片是由双目摄像头硬件压缩的jpeg格式,而后传输到中央控制模块4,通过两个摄像头所获取的二维图像结合神经网络算法计算出景物的三维信息并提取图片中的主要信息,通过BM算法得出图像视差,它与人类的双眼视觉在原理上比较相像。由于双目摄像可以提供被观察物体的空间立体信息,因而在机器视觉领域有着广泛的应用。同时,双目摄像需进行的各种信号处理涉及了图像处理技术的各个方面,综合性很强。目前,常用的双目机器视觉系统基本上是采用两个视轴平行或固定角度的摄像机来完成图像的采集。这种方式具有结构简单、测量速度快、测量和匹配的精度高等优点。但系统在进行测量之前,需要对摄像机进行严格的参数标定。
双目测距的基本原理如下:
参照图3,设定人体与物体之间的距离为Z,摄像头的焦距f,两个摄像头的镜头之间的距离为T,物体在两个传感器上所成像xl和xr的距离d,为变量,有:
d=xl-xr
因此,已知d的值,即可根据相似三角形原理求出Z。
在Opencv上实现双目测距,主要步骤为:
①双目校正和标定,获得摄像头的参数矩阵,标定采用的是MATLAB标定工具;
②立体匹配,获得视差图;
③采用BM算法生成视差图,如果左右匹配点比较稠密,匹配点多,得到的图像与原图相似度高,如果匹配点比较稀疏,得到的点与原图相似度低;
④得出测距;
⑤把生成的视差图输入到reprojectImageTo3D()函数,生成3D点云,3D点云中保存有2D图像的三维坐标,再读出每帧图像的三维坐标中的z轴的值,就得出了距离数据;
⑥结果分析。
目标障碍物方位辨别:在Opencv环境下,通过阈值选取法得到去背景的目标图片,并对该图片整个区域建立坐标进行区域划分,划分为三个区域,分别为左前、前方、右前方;同时,在去除背景的目标图片基础上根据目标具体形状生成目标对应的轮廓框图,再根据该框图,利用几何原理计算出目标轮廓框图的几何中心点;中心点和区域划分完成后,根据目标轮廓中心点位于区域划分图中的具体区域来得出该目标当前相对于摄像头的具体方位。
双目摄像头和卫星定位模块7分别经USB分流模块6与中央控制模块4连接,USB分流模块6为FE1.1s,FE1.1s是高度集成,高质量,高性能,低能耗,同时还是USB 2.0高速4端口集线的低成本解决方案。它采用单个交换转换器(Single Transaction Translator)(STT)构建以便获得更多的效益。六个而不是两个非周期转换缓存以减少潜在的通信干扰。整个设计基于状态机控制,以减小响应的延迟时间;在此芯片中未使用微型控制器。为保障高质量,整个芯片通过测试扫描链(Test Scan Chain)–即使在高速(480MHz)模式下,使所有的逻辑元件在装运前被充分测试。特别是内建自检(Build-In-Self-Test)模式目的在于使用所有的高速,全速,以及低速模式模拟前端端口(AFE)在封装和测试阶段也是如此。低能耗的实现是通过使用0.18m技术以及集成的电源/时钟控制机制。大部分引脚不需要计时,除非被用到;
语音处理模块2的控制框图如图4所示,该模块包括语音处理芯片(SYN6288)。
主要功能就是实现使用者与各种功能模块间的人机交互,当使用者距离障碍物的距离低于预警阈值时,中央控制模块4会向该模块发出播报指令,该模块则将得到的数据进行处理,并通过外放喇叭或耳机设备进行播报,告知使用者前方障碍物的类别、方位和距离,例如“右前方2.3米处有车辆”,使得使用者可以进行避障调整。当使用者想知道当前位置时,可以触发定位按钮,通过语音播报当前的地理位置信息。
卫星定位系统即全球定位系统(Global Positioning System),就是使用卫星对某物进行准确定位的技术。可以保证在任意时刻,地球上任意一点都可以同时观测到4颗卫星,以便实现导航、定位、授时等功能。具有的全天候、高精度和自动测量的特点,作为先进的测量手段和新的生产力,已经融入了国民经济建设、国防建设和社会发展的各个应用领域。卫星定位系统的工作原理是测量出已知位置的卫星到用户接收机之间的距离,然后综合多颗卫星的数据即知道接收机的具体位置。
GPS在本技术中的应用,主要是使眼镜具有精确的卫星定位功能,其实现方式是将眼镜作为Socket通信的客户端,把GPS获取的经纬度信息利用4G通信模块3通过TCP/IP协议在Internet上传递给PC机服务器端,而后PC服务器再将得到的经纬度信息通过百度地图API(Application Programming Interface)进行经纬度与位置信息的匹配,从而得知使用者所在位置,最后PC服务器端再将位置信息通过互联网发送回客户端(中央控制模块4)。
当使用者需要了解当前所在位置时或者想让家人及朋友能够了解自己当前所在具体地理位置时,触发开关,4G通信模块3即将位置信息以短信的方式发送至亲人手机。图5为卫星定位模块流程图。
网络通信功能的实现,利用了4G通信模块3的无线宽带网络接入功能,该模块的功能是负责眼镜端与各功能云服务器平台间通信链路的建立,其中之一,是将眼镜端与负责识别测距的云服务器建立实时相互通信,并实现语音通话功能,以方便其家人及时了解使用者当前身体状况;其二,无线通信模块不仅实现了与家人联系的功能,还实现了将GPS获取的经纬度信息通过Internet发送至PC服务器端并接收服务器反馈信息的网络通信功能,而这一功能也是卫星定位环节中至关重要的环节。
4G通信模块3由USB接口与中央控制模块4相连,USB主线总线信号为4个模块与系统之间的通讯接口。根据Linux3.2.0内核的自带的ECM口驱动对ME3760_V2模块进行加载,使用的是ME3760_V2模块的USB口进行连接,在Linux下,ME3760_V2模块的ECM口被映射成5个接口:ECM、\、AT、Modem、Log(下文有详细介绍),其中“\”也属于ECM口的一部分,为防止ECM功能被覆盖,在进行USB串口初始化时应将其过滤,并加载Linux内核的PPP驱动,使其余的接口初始化为USB串口设备,最后用PPP工具拨号连接4G网络。
技术实现步骤:
①在Linux下ME3760_V2模块的USB口被映射成5个接口:ECM、/、AT、Modem和Log;
②内核修改,在原有的Linux版本的基础上添加ME3760_V2模块的驱动,如:添加设备信息、USB串口驱动过滤ECM接口;
③内核编译;
④设备加载,ME3760_V2模块的ECM口在系统中被映射成网口eth0,其中AT/Modem/Log口在系统中被映射为ttyUSB0-ttyUSB2;
⑤建立4G连接,利用AT指令,使用PPP拨号,并静态设置eth0的IP和网关DNS或者使用PPP拨号,就能使用4G网络了。
⑥中央控制模块4,该模块主要实现对整个眼镜各个部分功能单元所采集到的数据和信息进行汇总分析,并根据数据所反映的场景,对各个功能模块发出相应的控制指令。
为了使各个模块运行效率更高、性能更稳定、实时性能更强,团队专门为核心板搭载了LINUX PDA操作系统,而其在本设计中的主要功能体现在以下的几个方面:
在双目摄像头的图像采集的控制中,预先在TQ210_COREB核心板中用程序设定一个图像采集频率,并实时将采集完的图像压缩并发送给后台服务器,核心板时时接收后台服务器传递过来的图像分析结果信息。
在本地-服务器递进识别方案的眼镜端,首先在搭载了精简Linux操作系统的A8上,利用Opencv平台对常见物体用Boost方法进行特征提取,并对提取的特征运用机器学习(SVM方法)建立匹配模板数据库。识别测距功能开启后,眼镜端先对预处理的图片解压缩,在图片中对物体与背景进行分割(阈值选取方法),再对背景分割后的目标图像进行特征提取(Boost方法),获取到的目标特征再利用SVM方法与建立常见物体模板数据库进行匹配,从而获得常见物体的识别结果;若匹配结果相似度低于识别比例,眼镜端会把预处理后的图像通过4G网络传送给云服务器进行识别。眼镜端障碍物识别、方位和距离实现过程如图6。目标的距离、方位获得过程同上。
在对语音处理模块2的控制中,预先在后台服务器分析程序中设置有预警阈值,当探测到的物体距离小于预警阈值时,核心板将接收到的文本信息经过语音模块处理后得到的各种功能的语音片段,以外放喇叭或者耳机的形式传递给使用者,当探测物体距离大于预警阈值时,停止播报。
当使用者处于迷路或是急需得到亲人朋友的帮助时,通过触按位置信息发送按键,主控系统得到触发信号后,会采用中断方式,控制卫星定位模块7确定当前位置的经纬度信息,然后再由中央控制模块4将经纬度信息转换为具体的地理位置信息,最后通过4G通信模块3将其发送至预存的家人手机号码,以方便家人了解其当前所在位置,进行寻人。
云服务器是由多台并行计算的服务器所构成服务器集群,具有较强的运算能力。作品的图像分析系统通过在云服务器上搭建软件平台,利用深度学习神经网络,建立图像学习数据库,完成对传输进来的图片进行识别处理。云服务器,是一种简单高效、安全可靠、处理能力可弹性伸缩的计算服务。其管理方式比物理服务器更简单高效。用户无需提前购买硬件,即可迅速创建或释放任意多台云服务器。
深度学习原理:深度学习在训练数据库时,需要提供强大的计算能力,并且需要存储大量的训练数据,鉴于云服务器有以上优势和特性,遂决定采用云服务器作为图像识别处理系统的软件平台。深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。图6是含有多个隐层的深度学习模型。
而为了克服神经网络训练中的问题,深度学习采用了与神经网络很不同的训练机制。传统神经网络中,采用的是back propagation的方式进行,简单来讲就是采用迭代的算法来训练整个网络,随机设定初值,计算当前网络的输出,然后根据当前的输出和层之间的差去改变前面各层的参数,直到收敛(整体是一个梯度下降法)。而深度学习整体上是一个layer-wise的训练机制。这样做的原因是因为,如果采用back propagation的机制,对于一个深度神经网络(7层以上),残差传播到最前面的层已经变得太小,出现所谓的梯度扩散。图7是layer-wise的训练机制。
深度学习训练过程具体如下:
(1)使用自下上升非监督学习(从底层开始,一层一层的往顶层训练):
采用无标定数据(有标定数据也可)分层训练各层参数,这一步可以看作是一个无监督训练过程,是和传统神经网络区别最大的部分(这个过程可以看作是特征学习的过程)。具体的,先用无标定数据训练第一层,训练时先学习第一层的参数(这一层可以看作是得到一个使得输出和输入差别最小的三层神经网络的隐层),由于模型容量的限制以及稀疏性约束,使得得到的模型能够学习到数据本身的结构,从而得到比输入更具有表示能力的特征;在学习得到第n-1层后,将n-1层的输出作为第n层的输入,训练第n层,由此分别得到各层的参数;
(2)自顶向下的监督学习(通过带标签的数据去训练,误差自顶向下传输,对网络进行微调):
基于第一步得到的各层参数进一步微调整个多层模型的参数,这一步是一个有监督训练过程;第一步类似神经网络的随机初始化初值过程,由于DL的第一步不是随机初始化,而是通过学习输入数据的结构得到的,因而这个初值更接近全局最优,从而能够取得更好的效果;所以深度学习效果好很大程度上归功于第一步的特征学习过程。训练过程采用CIFAR-10自然场景库。CIFAR-10数据集包含60000个32*32的彩色图像,共有10类。有50000个训练图像和10000个测试图像。数据集分为5个训练块和1个测试块,每个块有10000个图像。测试块包含从每类随机选择的1000个图像。训练块以随机的顺序包含这些图像,但一些训练块可能比其它类包含更多的图像。训练块每类包含5000个图像。
在CIFAR-10自然场景库之外,团队加入了一些生活中常见的场景:椅子,垃圾箱,人。这样更能检测识别系统的实用性。
非常见物体的类别、方位和距离:
云服务器平台主要负责前端无法识别的非常见物体类别、方位和距离的处理工作。
在后台云服务器利用Opencv平台对非常见物体用Boost方法进行特征提取,并对提取的特征运用深度学习建立匹配模板数据库。识别测距功能开启后,非常见物体图片通过4G通信上传到云服务器端,对预处理的图片解压缩,在图片中对物体与背景进行分割(阈值选取方法),再对背景分割后的目标图像进行特征提取(Boost方法),获取到的目标特征再与建立非常见物体模板数据库进行深度学习,得到相似度最高的匹配结果,从而获得非常见物体的识别结果;目标的距离、方位获得过程同上。
- 还没有人留言评论。精彩留言会获得点赞!