血压预测的方法及装置与流程
本发明涉及医疗信息化技术领域,具体而言,涉及一种血压预测的方法及装置。
背景技术:
血压是血液在血管内流动时作用于血管壁的压力,它是推动血液在血管内流动的动力。正常的血压是血液循环流动的前提,血压在多种因素调节下保持正常,从而提供各组织器官以足够的血量,以维持正常的新陈代谢。血压过低(低血压)或过高(高血压)都会造成严重后果,血压消失是死亡的前兆,这都说明血压有极其重要的生物学意义。
目前,人体动脉血压测定要用间接测定法,通常使用俄国医师N.科罗特科夫发明的测定法,该测定法使用的装置包括能充气的袖袋和与之相连的测压计,将袖袋绑在受试者的上臂,然后打气到阻断肱动脉血流为止,缓缓放出袖袋内的空气,利用放在肱动脉上的听诊器可以听到当袖袋压刚小于肱动脉血压血流冲过被压扁动脉时产生的湍流引起的振动声(科罗特科夫氏声,简称科氏声)来测定心脏收缩期的最高压力,叫做收缩压;继续放气,科氏声加大,当此声变得低沉而长时所测得的血压读数,相当于心脏舒张时的最低血压,叫做舒张压;当放气到袖袋内压低于舒张压时,血流平稳地流过无阻碍的血管,科氏声消失。
由于汞的比重太大,水银测压计难以精确迅速地反映心搏各期血压的瞬间变化,所以后来改用各种灵敏的薄膜测压计可以较准确地测得收缩和舒张压。近年来常使用各种换能器与示波器结合可以更灵敏地测定记录血压。
整体看来,目前的方法都是对人体当前的血压进行测量,不能够预测人体未来的血压。若能够提前预测人体血压,那么对于病患人群,尤其是对于高血压患者来说都极为重要。虽然相关技术中也有通过固定结构神经网络来对血压数据进行分析,但是由于神经网络结构固定,网络 自适应较差,难以满足复杂的应用场景。
因此,需要一种新的血压预测方法来实现对血压的有效预测。
需要说明的是,在上述背景技术部分公开的信息仅用于加强对本发明的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现要素:
本发明的目的在于提供一种血压预测的方法及装置,进而至少在一定程度上克服由于相关技术的限制和缺陷而导致的一个或者多个问题。
本发明的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本发明的实践而习得。
根据本发明的一个方面,提供一种血压预测的方法,包括:
配置用于进行血压预测的神经网络;
基于预设的多组训练样本对所述神经网络进行训练,得到训练后的神经网络;
根据训练后的神经网络,对人体的血压数据进行预测。
在本发明的一些实施例中,基于前述方案,所述的血压预测的方法还包括:
采集用户的多个血压数据;
基于所述多个血压数据,形成所述多组训练样本,其中,每组训练样本包含M+1个血压数据,所述M+1个血压数据中按照采集顺序的前M个血压数据作为所述每组训练样本的输入参数,第M+1个血压数据作为所述每组训练样本的输出参数。
在本发明的一些实施例中,基于前述方案,其中,基于预定时间间隔采集所述用户的多个血压数据。
在本发明的一些实施例中,基于前述方案,所述神经网络包括:M个输入层神经元、K个隐含层神经元和1个输出层神经元。
在本发明的一些实施例中,基于前述方案,通过以下公式计算所述神经网络的输出:
其中,y(t)表示所述神经网络的实际输出;wk(t)表示所述隐含层神经元中第k个神经元和所述输出层神经元的连接权值,k=1,2,…,K;φk(x(t))表示所述隐含层神经元中的第k个神经元的输出。
在本发明的一些实施例中,基于前述方案,基于以下公式计算所述φk(x(t))的值:
其中,μk表示所述隐含层神经元中的第k个神经元的中心值,σk表示所述隐含层神经元中的第k个神经元的中心宽度。
在本发明的一些实施例中,基于前述方案,基于预设的多组训练样本对所述神经网络进行训练,包括:
将所述神经网络中的参数表示为粒子群中的粒子,并初始化粒子群;
通过所述预设的多组训练样本对所述粒子群进行迭代优化,直至满足迭代终止条件。
在本发明的一些实施例中,基于前述方案,对所述粒子群进行迭代优化时的任一次优化过程,包括:
计算所述粒子群中每个粒子的适应度值;
根据所述每个粒子的适应度值,确定所述每个粒子的历史最优位置和全局最优位置;
基于所述每个粒子的历史最优位置和全局最优位置,更新所述每个粒子的位置和速度;
基于所述每个粒子的全局最优位置,确定所述神经网络的最优网络结构,以更新所述每个粒子对应的隐含层神经元的个数。
在本发明的一些实施例中,基于前述方案,通过以下公式将所述神经网络中的参数表示为粒子群中的粒子:
其中,ai表示第i个粒子的位置,i=1,2,…,s;s表示粒子群中的粒子总个数,s为正整数;μi,k、σi,k和wi,k分别表示第i个粒子的第k个隐含层神经元的中心值、中心宽度和连接权值;Ki表示第i个粒子表示的神经网络的隐含层神经元数;μi,k、σi,k和wi,k的初始值取(0,1)中的任意数,Ki的初始值为任意正整数。
在本发明的一些实施例中,基于前述方案,初始化粒子群,包括:
初始化粒子群加速常数c1和c2,c1∈(0,1),c2∈(0,1);
设定粒子群平衡权值α∈[0,1];
初始化粒子的速度:其中,vi表示第i个粒子的速度,Di表示第i个粒子的维数,Di=3Ki。
在本发明的一些实施例中,基于前述方案,通过以下公式计算所述粒子群中每个粒子的适应度值:
其中,f(ai(t))表示所述每个粒子的适应度值;i=1,2,…,s;s表示粒子群中的粒子总个数,s为正整数;T表示所述预设的训练样本的个数;y(t)表示所述神经网络的实际输出;yd(t)表示所述神经网络的期望输出。
在本发明的一些实施例中,基于前述方案,根据所述每个粒子的适应度值,确定所述每个粒子的历史最优位置和全局最优位置,包括:
计算所述每个粒子的惯性权重:ωi(t)=S(t)tAi(t);
其中,t表示对所述粒子群进行迭代优化的次数;S(t)=fmin(a(t))/fmax(a(t));Ai(t)=f(g(t))/f(ai(t));fmin(a(t))、fmax(a(t))分别表示当前时刻的最小适应度值和最大适应度值,g(t)表示粒子全局最优位置,且fmin(a(t))、fmax(a(t))和g(t)分别表示为:
其中,每个粒子的历史最优位置pi(t)通过以下公式表示:
在本发明的一些实施例中,基于前述方案,通过以下公式更新所述每个粒子的位置和速度:
vi(t+1)=ωi(t)vi(t)+c1r1(pi(t)-ai(t))+c2r2(g(t)-ai(t));
ai(t)=ai(t-1)+αvi(t);
其中,r1和r2分别表示每个粒子的历史最优位置系数和全局最优位置系数,r1和r2取[0,1]中的任意数。
在本发明的一些实施例中,基于前述方案,通过以下公式更新所述每个粒子对应的隐含层神经元的个数:
其中,Ki(t)表示更新后的所述每个粒子对应的隐含层神经元的个数;Ki(t-1)表示更新前的所述每个粒子对应的隐含层神经元的个数;Kbest表示所述神经网络的最优网络结构的隐含层神经元个数。
在本发明的一些实施例中,基于前述方案,所述神经网络包括自组织径向基神经网络。
根据本发明的另一方面,还提出了一种血压预测的装置,包括:
配置单元,用于配置用于进行血压预测的神经网络;
训练处理单元,用于基于预设的多组训练样本对所述神经网络进行训练,得到训练后的神经网络;
预测处理单元,用于根据训练后的神经网络,对人体的血压数据进行预测。
在本发明的一些实施例所提供的技术方案中,通过配置进行血压预测的神经网络,并基于预设的多组训练样本来对神经网络进行训练,进而通过训练后的神经网络来进行血压预测,使得能够提前预知人体的血压值,以将其作为血压参考,确保医生及患者可以提前了解血压的变化情况,从而提前采取相应的预防措施,对于健康管理和疾病治疗具有极大的意义。
在本发明的一些实施例所提供的技术方案中,通过采集用户的多个血压数据以形成多组训练样本,进而基于这些训练样本来对神经网络进行训练,使得能够利用人体的历史血压数据作为训练样本来实现对神经网络的校正,进而能够确保快速、准确地对人体血压进行预测,有利于疾病的预防和健康管理。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。在附图中:
图1示意性示出了根据本发明的一个实施例的血压预测的方法的流程图;
图2示意性示出了根据本发明的一个实施例的神经网络的结构图;
图3示意性示出了根据本发明的一个实施例的基于自组织径向基神经网络的血压预测方法的流程图;
图4示意性示出了根据本发明的一个实施例的自组织径向基神经网络的结构图;
图5示意性示出了根据本发明的一个实施例的血压预测的装置的框图。
具体实施方式
现在将参考附图更全面地描述示例实施方式。然而,示例实施方式能够以多种形式实施,且不应被理解为限于在此阐述的范例;相反,提供这些实施方式使得本发明将更加全面和完整,并将示例实施方式的构思全面地传达给本领域的技术人员。
此外,所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施例中。在下面的描述中,提供许多具体细节从而给出对本发明的实施例的充分理解。然而,本领域技术人员将意识到,可以实践本发明的技术方案而没有特定细节中的一个或更多,或者可以采用其它的方法、组元、装置、步骤等。在其它情况下,不详细示出或描述公知方法、装置、实现或者操作以避免模糊本发明的各方面。
附图中所示的方框图仅仅是功能实体,不一定必须与物理上独立的实体相对应。即,可以采用软件形式来实现这些功能实体,或在一个或多个硬件模块或集成电路中实现这些功能实体,或在不同网络和/或处理器装置和/或微控制器装置中实现这些功能实体。
附图中所示的流程图仅是示例性说明,不是必须包括所有的内容和 操作/步骤,也不是必须按所描述的顺序执行。例如,有的操作/步骤还可以分解,而有的操作/步骤可以合并或部分合并,因此实际执行的顺序有可能根据实际情况改变。
图1示意性示出了根据本发明的一个实施例的血压预测的方法的流程图。
如图1所示,根据本发明的一个实施例的血压预测的方法,包括:
步骤S102,配置用于进行血压预测的神经网络。
需要说明的是:在本发明的实施例中,神经网络是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型,这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。其中,神经网络可以是自组织径向基神经网络,也可以是前馈神经网络,还可以是其它神经网络。
步骤S104,基于预设的多组训练样本对所述神经网络进行训练,得到训练后的神经网络。
需要说明的是:训练样本的作用是为了确定神经网络的相关参数,当通过训练样本对神经网络进行训练之后,可以认为神经网络的结构已经确定。
根据本发明的示例性实施例,所述的血压预测的方法还包括:采集用户的多个血压数据;基于所述多个血压数据,形成所述多组训练样本,其中,每组训练样本包含M+1个血压数据,所述M+1个血压数据中按照采集顺序的前M个血压数据作为所述每组训练样本的输入参数,第M+1个血压数据作为所述每组训练样本的输出参数。
在该示例性实施例中,通过采集用户的多个血压数据,以形成多组训练样本,使得能够利用人体的历史血压数据来对神经网络进行训练,以校正神经网络的参数,进而可以确保校正后的神经网络能够准确地实现对人体血压的预测。
根据本发明的示例性实施例,可以基于预定时间间隔采集所述用户的多个血压数据。譬如每隔1小时采集用户的一个血压数据。
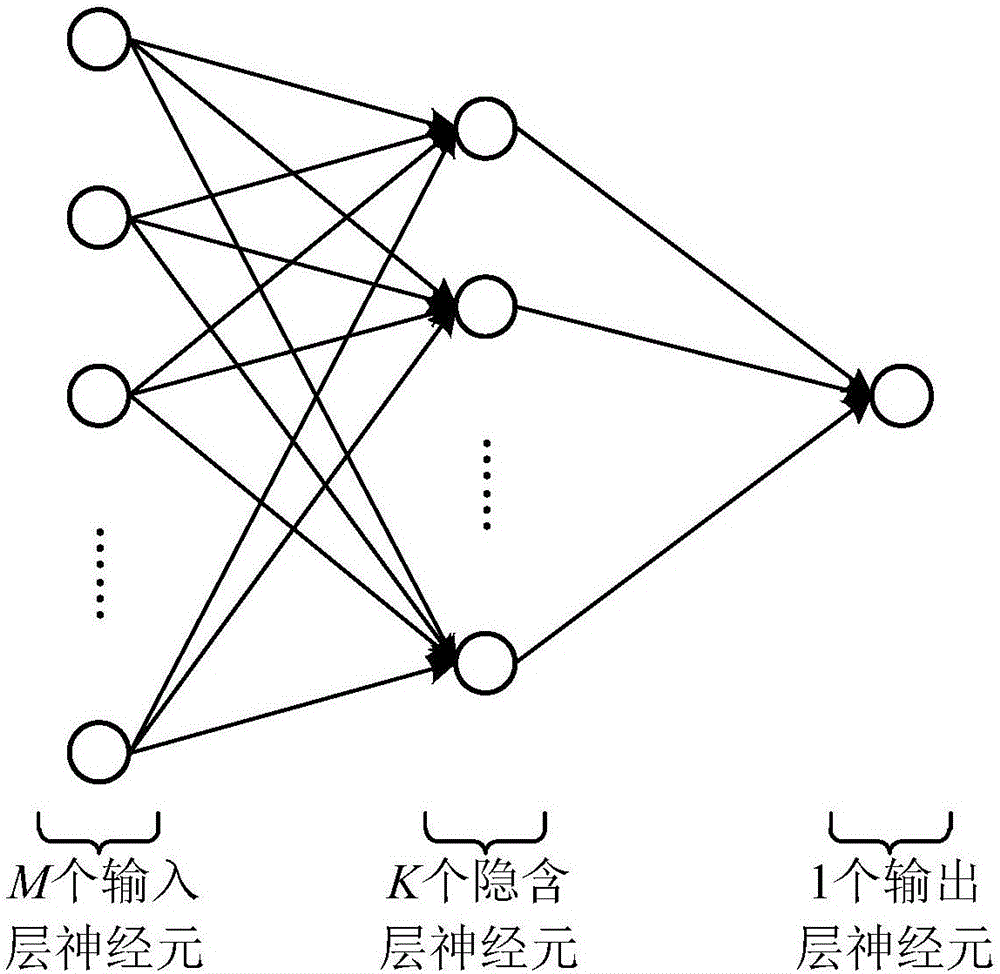
根据本发明的示例性实施例,如图2所示,神经网络包括:M个输入层神经元、K个隐含层神经元和1个输出层神经元。换句话说,神经网络的结构是M-K-1的连接方式。
根据本发明的示例性实施例,通过以下公式计算所述神经网络的输出:
其中,y(t)表示所述神经网络的实际输出;wk(t)表示所述隐含层神经元中第k个神经元和所述输出层神经元的连接权值,k=1,2,…,K;φk(x(t))表示所述隐含层神经元中的第k个神经元的输出,具体可基于以下公式计算所述φk(x(t))的值:
其中,μk表示所述隐含层神经元中的第k个神经元的中心值,σk表示所述隐含层神经元中的第k个神经元的中心宽度。
根据本发明的示例性实施例,步骤S104中基于预设的多组训练样本对所述神经网络进行训练,具体包括:
将所述神经网络中的参数表示为粒子群中的粒子,并初始化粒子群;
通过所述预设的多组训练样本对所述粒子群进行迭代优化,直至满足迭代终止条件。
需要说明的是,对粒子群进行迭代优化是指通过预设的多组训练样本多次对粒子群进行迭代优化,以对神经网络的结构进行优化。其中,迭代终止条件可以是迭代的次数达到设定的次数和/或优化后的精度达到了设定精度。
根据本发明的示例性实施例,对所述粒子群进行迭代优化时的任一次优化过程,包括:
计算所述粒子群中每个粒子的适应度值;
根据所述每个粒子的适应度值,确定所述每个粒子的历史最优位置和全局最优位置;
基于所述每个粒子的历史最优位置和全局最优位置,更新所述每个粒子的位置和速度;
基于所述每个粒子的全局最优位置,确定所述神经网络的最优网络结构,以更新所述每个粒子对应的隐含层神经元的个数。
根据本发明的示例性实施例,通过以下公式将所述神经网络中的参 数表示为粒子群中的粒子:
其中,ai表示第i个粒子的位置,i=1,2,…,s;s表示粒子群中的粒子总个数,s为正整数;μi,k、σi,k和wi,k分别表示第i个粒子的第k个隐含层神经元的中心值、中心宽度和连接权值;Ki表示第i个粒子表示的神经网络的隐含层神经元数;μi,k、σi,k和wi,k的初始值取(0,1)中的任意数,Ki的初始值为任意正整数。
在本发明的一些实施例中,基于前述方案,初始化粒子群,包括:
初始化粒子群加速常数c1和c2,c1∈(0,1),c2∈(0,1);
设定粒子群平衡权值α∈[0,1];
初始化粒子的速度:其中,vi表示第i个粒子的速度,Di表示第i个粒子的维数,Di=3Ki。
根据本发明的示例性实施例,通过以下公式计算所述粒子群中每个粒子的适应度值:
其中,f(ai(t))表示所述每个粒子的适应度值;i=1,2,…,s;s表示粒子群中的粒子总个数,s为正整数;T表示所述预设的训练样本的个数;y(t)表示所述神经网络的实际输出;yd(t)表示所述神经网络的期望输出。
根据本发明的示例性实施例,根据所述每个粒子的适应度值,确定所述每个粒子的历史最优位置和全局最优位置,包括:
计算所述每个粒子的惯性权重:ωi(t)=S(t)tAi(t);
其中,t表示对所述粒子群进行迭代优化的次数;S(t)=fmin(a(t))/fmax(a(t));Ai(t)=f(g(t))/f(ai(t));fmin(a(t))、fmax(a(t))分别表示当前时刻的最小适应度值和最大适应度值,g(t)表示粒子全局最优位置,且fmin(a(t))、fmax(a(t))和g(t)分别表示为:
其中,每个粒子的历史最优位置pi(t)通过以下公式表示:
根据本发明的示例性实施例,通过以下公式更新所述每个粒子的位置和速度:
vi(t+1)=ωi(t)vi(t)+c1r1(pi(t)-ai(t))+c2r2(g(t)-ai(t));
ai(t)=ai(t-1)+αvi(t);
其中,r1和r2分别表示每个粒子的历史最优位置系数和全局最优位置系数,r1和r2取[0,1]中的任意数。
根据本发明的示例性实施例,通过以下公式更新所述每个粒子对应的隐含层神经元的个数:
其中,Ki(t)表示更新后的所述每个粒子对应的隐含层神经元的个数;Ki(t-1)表示更新前的所述每个粒子对应的隐含层神经元的个数;Kbest表示所述神经网络的最优网络结构的隐含层神经元个数。
图1所示的血压预测的方法还包括:
步骤S106,根据训练后的神经网络,对人体的血压数据进行预测。
根据本发明的示例性实施例,在步骤S106中,可以将检测到的用户的若干个血压数据作为训练后的神经网络的输入,那么训练后的神经网络的输出即为预测到的血压数据。
在本发明的一个示例性实施例中,神经网络可以是自组织径向基神经网络,以下结合图3以自组织径向基神经网络为例,对本发明的技术方案进行详细说明:
参照图3,根据本发明的一个实施例的基于自组织径向基神经网络的血压预测方法,包括如下步骤:
步骤S302,确定自组织径向基神经网络模型的输入输出变量。
具体地,将M组历史数据作为模型输入,第M+1作为输出变量,在实际应用中M为间隔固定时间取得的数据,如每隔1小时取一个血压数据,前M个作为输入,第M+1作为输出。在本发明的示例性实施例中,可以取6个历史血压数据作为输入,即自组织径向基神经网络的 模型为6输入,1输出。
步骤S304,设计用于人体血压预测的自组织径向基神经网络拓扑结构。
具体参照图4所示,自组织径向基神经网络包括:输入层、隐含层、输出层;初始化径向基神经网络:确定神经网络M-K-1的连接方式,即输入层神经元为M个,隐含层神经元为K个,K为正整数,输出层神经元为1个;对神经网络的参数进行赋值;设共有T组训练样本,若每组训练样本包含6个数据,则第t时刻神经网络输入为x(t)=[x1(t),x2(t),x3(t),x4(t),x5(t),x6(t)],神经网络的期望输出表示为yd(t),实际输出表示为y(t);径向基神经网络的计算功能是:
其中,wk(t)表示隐含层第k个神经元和输出层的连接权值,k=1,2,…,K;φk(x(t))表示隐含层第k个神经元的输出,其计算公式为:
其中,μk表示隐含层第k个神经元中心值,σk表示隐含层第k个神经元的中心宽度。
步骤S306,训练神经网络,具体包括:
①初始化粒子群加速常数c1和c2,c1∈(0,1),c2∈(0,1);设定粒子群平衡权值α∈[0,1],将径向基神经网络的参数表示为粒子群中的粒子:
其中,ai表示第i个粒子的位置,i=1,2,…,s;s表示粒子总个数,s为正整数,μi,k,σi,k和wi,k分别表示第i个粒子中第k个隐含层神经元的中心值,中心宽度和连接权值;Ki表示第i个粒子表示的径向基神经网络隐含层神经元数;μi,k,σi,k和wi,k的初始值取(0,1)的任意数,Ki的初始值为任意正整数;同时,初始化粒子的速度:
其中,vi表示第i个粒子的速度,Di表示第i个粒子的维数,Di=3Ki。
②对于神经网络的输入x(t),确定每个粒子的维数Di(t)=3Ki(t),计 算每个粒子的适应度值:
其中,i=1,2,…,s;T表示神经网络输入的训练样本数。
③计算每个粒子的惯性权重:
ωi(t)=S(t)tAi(t) (6)
其中:
S(t)=fmin(a(t))/fmax(a(t));Ai(t)=f(g(t))/f(ai(t)) (7)
fmin(a(t))、fmax(a(t))分别为当前时刻最小适应度值和最大适应度值,粒子全局最优位置g(t)分别表示为:
其中,粒子本身的历史最优位置pi(t)表示为:
④更新每个粒子的位置和速度:
vi(t+1)=ωi(t)vi(t)+c1r1(pi(t)-ai(t))+c2r2(g(t)-ai(t));
ai(t)=ai(t-1)+αvi(t) (10)
其中,r1和r2分别表示个体历史最优系数和全局最优位置系数,r1和r2取[0,1]的任意数。
⑤根据全局最优位置g(t)找出最优网络结构,此时的最优神经网络隐含层神经元数为Kbest,并根据每个粒子神经元数与最优粒子神经元数的差异,更新每个粒子对应的神经网络隐含层神经元数:
⑥输入训练样本数据x(t+1),重复步骤②-⑤,直到满足预定的精度要求或者满足迭代次数之后停止计算。
当停止计算之后,可以得到最优的自组织神经网络的结构,进而可以基于最优的自组织神经网络的结构来进行血压预测。
根据本发明的示例性实施例,可以基于智能手环来采集用户的血压数据。自组织径向基神经网络能够通过历史血压数据进行学习,调整神经网络的结构及参数,进而能够提前预知血压值,比如,可以根据智能 手环实时采集的最近6小时的6组血压数据(此处仅为示例,并不作具体限定),通过自组织径向基神经网络进行在线预测未来一小时的血压值,进而将预测的血压值作为血压参考,让医生及患者提前了解血压变化,从而提前采取相应预防措施,对于健康管理和疾病治疗具有极大意义。
图5示意性示出了根据本发明的一个实施例的血压预测的装置的框图。
参照图5,根据本发明的一个实施例的血压预测的装置500,包括:配置单元502、训练处理单元504和预测处理单元506。
具体地,配置单元502用于配置用于进行血压预测的神经网络;训练处理单元504用于基于预设的多组训练样本对所述神经网络进行训练,得到训练后的神经网络;预测处理单元506用于根据训练后的神经网络,对人体的血压数据进行预测。
其中,神经网络可以是自组织径向基神经网络,也可以是前馈神经网络,还可以是其它神经网络。
根据本发明的示例性实施例,可以通过下述方法确定多组训练样本:采集用户的多个血压数据;基于所述多个血压数据,形成所述多组训练样本,其中,每组训练样本包含M+1个血压数据,所述M+1个血压数据中按照采集顺序的前M个血压数据作为所述每组训练样本的输入参数,第M+1个血压数据作为所述每组训练样本的输出参数。
根据本发明的示例性实施例,可以基于预定时间间隔采集所述用户的多个血压数据。比如可以每隔1小时采集用户的一个血压数据。
根据本发明的示例性实施例,所述神经网络包括:M个输入层神经元、K个隐含层神经元和1个输出层神经元。
根据本发明的示例性实施例,通过以下公式计算所述神经网络的输出:
其中,y(t)表示所述神经网络的实际输出;wk(t)表示所述隐含层神经元中第k个神经元和所述输出层神经元的连接权值,k=1,2,…,K;φk(x(t))表示所述隐含层神经元中的第k个神经元的输出,具体可基 于以下公式计算所述φk(x(t))的值:
其中,μk表示所述隐含层神经元中的第k个神经元的中心值,σk表示所述隐含层神经元中的第k个神经元的中心宽度。
根据本发明的示例性实施例,训练处理单元504配置为:将所述神经网络中的参数表示为粒子群中的粒子,并初始化粒子群;通过所述预设的多组训练样本对所述粒子群进行迭代优化,直至满足迭代终止条件。
根据本发明的示例性实施例,对所述粒子群进行迭代优化时的任一次优化过程,包括:
计算所述粒子群中每个粒子的适应度值;
根据所述每个粒子的适应度值,确定所述每个粒子的历史最优位置和全局最优位置;
基于所述每个粒子的历史最优位置和全局最优位置,更新所述每个粒子的位置和速度;
基于所述每个粒子的全局最优位置,确定所述神经网络的最优网络结构,以更新所述每个粒子对应的隐含层神经元的个数。
根据本发明的示例性实施例,通过以下公式将所述神经网络中的参数表示为粒子群中的粒子:
其中,ai表示第i个粒子的位置,i=1,2,…,s;s表示粒子群中的粒子总个数,s为正整数;μi,k、σi,k和wi,k分别表示第i个粒子的第k个隐含层神经元的中心值、中心宽度和连接权值;Ki表示第i个粒子表示的神经网络的隐含层神经元数;μi,k、σi,k和wi,k的初始值取(0,1)中的任意数,Ki的初始值为任意正整数。
根据本发明的示例性实施例,初始化粒子群,包括:
初始化粒子群加速常数c1和c2,c1∈(0,1),c2∈(0,1);
设定粒子群平衡权值α∈[0,1];
初始化粒子的速度:其中,vi表示第i个粒子的速度,Di表示第i个粒子的维数,Di=3Ki。
根据本发明的示例性实施例,通过以下公式计算所述粒子群中每个 粒子的适应度值:
其中,f(ai(t))表示所述每个粒子的适应度值;i=1,2,…,s;s表示粒子群中的粒子总个数,s为正整数;T表示所述预设的训练样本的个数;y(t)表示所述神经网络的实际输出;yd(t)表示所述神经网络的期望输出。
根据本发明的示例性实施例,根据所述每个粒子的适应度值,确定所述每个粒子的历史最优位置和全局最优位置,包括:
计算所述每个粒子的惯性权重:ωi(t)=S(t)tAi(t);
其中,t表示对所述粒子群进行迭代优化的次数;S(t)=fmin(a(t))/fmax(a(t));Ai(t)=f(g(t))/f(ai(t));fmin(a(t))、fmax(a(t))分别表示当前时刻的最小适应度值和最大适应度值,g(t)表示粒子全局最优位置,且fmin(a(t))、fmax(a(t))和g(t)分别表示为:
其中,每个粒子的历史最优位置pi(t)通过以下公式表示:
根据本发明的示例性实施例,通过以下公式更新所述每个粒子的位置和速度:
vi(t+1)=ωi(t)vi(t)+c1r1(pi(t)-ai(t))+c2r2(g(t)-ai(t));
ai(t)=ai(t-1)+αvi(t);
其中,r1和r2分别表示每个粒子的历史最优位置系数和全局最优位置系数,r1和r2取[0,1]中的任意数。
根据本发明的示例性实施例,通过以下公式更新所述每个粒子对应的隐含层神经元的个数:
其中,Ki(t)表示更新后的所述每个粒子对应的隐含层神经元的个数;Ki(t-1)表示更新前的所述每个粒子对应的隐含层神经元的个数;Kbest表示所述神经网络的最优网络结构的隐含层神经元个数。
根据本发明的示例性实施例,预测处理单元506配置为:将检测到的用户的若干个血压数据作为训练后的神经网络的输入,并将训练后的神经网络的输出作为预测到的血压数据。
基于本发明上述实施例的技术方案,可以实现人体血压的在线预测,进而能够使用户提前了解未来的血压变化,从而采取相应的干预措施,具有较大的健康管理价值;同时,提前预测血压也可作为医务人员治疗的参考,为抢救赢取时间,具有较大的医疗价值。
应当注意,尽管在上文详细描述中提及了用于动作执行的设备的若干模块或者单元,但是这种划分并非强制性的。实际上,根据本发明的实施方式,上文描述的两个或更多模块或者单元的特征和功能可以在一个模块或者单元中具体化。反之,上文描述的一个模块或者单元的特征和功能可以进一步划分为由多个模块或者单元来具体化。
通过以上的实施方式的描述,本领域的技术人员易于理解,这里描述的示例实施方式可以通过软件实现,也可以通过软件结合必要的硬件的方式来实现。因此,根据本发明实施方式的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中或网络上,包括若干指令以使得一台计算设备(可以是个人计算机、服务器、触控终端、或者网络设备等)执行根据本发明实施方式的方法。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本申请旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本发明未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由下面的权利要求指出。
应当理解的是,本发明并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!