幽门螺杆菌自动筛选和标注的系统及方法与流程
本发明涉及深度学习在医学诊断中的应用,尤其涉及一种幽门螺杆菌自动筛选和标注的系统及方法。
背景技术:
深度学习是机器学习研究中的一个新的领域,其通过建立、模拟人脑进行分析学习的神经网络,即建立卷积神经网络对外部输入的数据进行自动化特征提取,从而能够使机器理解学习数据,获得信息并输出。深度学习算法目前已应用于图像、声音和文本等方面的智能识别。医学病理中主要依靠组织图像做出诊断,深度学习在病理中的应用将推进病理诊断的发展。
幽门螺杆菌(helicobacterpylori,h.pylori)是从胃黏膜活检组织中分离出的一种微需氧的革兰阴性杆菌。h.pylori在全球感染率达50%以上,被国际癌症研究机构定为i类致病原。我国h.pylori感染率在50%左右,地区不同会略有差异,目前认为h.pylori感染可引发溃疡,消化不良,胃癌,胃粘膜相关淋巴组织(malt)淋巴瘤等疾病。
h.pylori检测最准确的方法是细菌培养,但细菌培养存在技术要求高、操作费时、敏感性低等因素。
胃部疾病的确诊多是取活检后在组织病理学的诊断,组织切片的常规苏木精-伊红染色法(hematoxylin-eosinstaining,he染色)中即可观察h.pylori,光学显微镜下呈螺旋状或s状,长2.5~4.0μm,宽0.5~1.0μm,位于胃黏膜层表面。
但目前常规he染色切片诊断存在的问题有:
工作强度大:大体标本和胃镜活检组织切片都需要观察有无h.pylori,医院每天胃镜活检组织较多,且h.pylori较小,需要在高倍镜下仔细观察每一个视野,病理医师工作量大。
漏检风险:当感染h.pylori量极少时,因h.pylori较小,与组织染色相似,需在每个高倍视野下查看,导致部分容易漏检。
诊断一致性差:诊断结果受病理医生自身经验、工作状态等主观因素影响,因此结果一致性较差。
复诊困难:使用常规玻璃切片诊断时,不能标记保存;当h.pylori量少时,其他医师难以查找h.pylori以复诊。
病理医师资源分配不均:病理医生需要进行长期的专业培训和实践过程,培养周期长;专家多在知名三甲医院,县镇医院病理医师缺乏。
技术实现要素:
针对上述问题,本发明的目的在于提供一种用于h.pylori自动筛选和标注的系统和方法,该方法将基于机器学习的计算机自动诊断方法和病理图像识别、处理方法相结合,在利用计算机预测数字病理切片病变类型的同时,为医生提供已确诊的h.pylori阳性病例作为参考,达到提高h.pylori识别诊断质量与提升医生诊断能力的目的。
为达到上述目的,本发明所提出的技术方案为:一种基于h.pylori自动筛选和标注的系统和方法,包括以下步骤:
步骤1:选择有专家诊断信息的胃组织切片,包括h.pylori阳性和阴性的切片。
步骤2:使用切片扫描仪将常规切片扫描转换为数字病理切片,作为数字病理图像数据库。
步骤3:病理医生对数字切片中的h.pylori进行标注,作为h.pylori数据库。
步骤4:使用深度学习算法和图像处理方法对数字病理图像数据库和h.pylori数据库进行分析和学习,建立数字病理图像自动诊断模型。
步骤5:使用步骤4中建立的数字病理图像自动诊断模型对未知病变的数字病理切片进行诊断,将h.pylori自动标注识别;将标注诊断结果反馈给病理医生,辅助病理医生进行诊断。
进一步的,所述h.pylori数据库,建立方法为:对于扫描的数字切片库,选择诊断为h.pylori阳性的数字切片,对于其中的h.pylori进行识别标记,并将其采集保存。
综上所述,本发明的有效益果是:与现有的病理医生人工阅片相比较,通过扫描仪将组织切片转换为数字切片,使用深度学习算法分析学习标注数据库,从而训练出能模拟病理医生阅片的智能化神经网络模型,对未知组织图像诊断识别,辅助病理医生诊断参考。经过不断学习和验证,该神经网络模型可以实现对h.pylori的智能阅片、快速识别并得出科学结论。该方法从病理临床工作实际出发,耗时短,可重复性高,数据客观真实,极大减轻了病理医生的工作量。同时此发明在各级医院的推广将有助于解决病理医生资源分配不均匀等问题。
附图说明
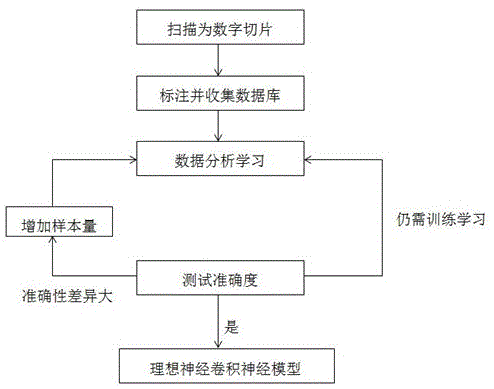
图1为本发明的流程示意图。
具体实施方式
下面结合符合和具体实施方式,对本发明做进一步说明。
如图1所示,一种基于幽门螺杆菌自动筛选和标注的系统及方法,包括以下具体的步骤:步骤1:选择有专家诊断信息的胃组织切片,包括h.pylori阳性和阴性的切片。
为了保证样本的准确性,选择2个专家诊断结果一致的胃h.pylori阳性和阴性的切片。
步骤2:使用切片扫描仪将常规he染色切片扫描转换为数字病理切片,作为数字病理图像数据库。
为满足训练样本的需要,病理切片都在40倍镜下进行扫描,保证整个数字切片的像素质量,以便于读取、传输与处理。
步骤3:病理医生对数字切片中的h.pylori进行标注,作为h.pylori数据库。
对于有专家诊断结果的组织切片,扫描转化为数字切片后,需要有经验的病理医生对其诊断标注识别。并将标注的h.pylori收集保存。
步骤4:使用深度学习算法和图像处理方法对数字病理图像数据库和h.pylori数据库进行分析和学习,建立数字病理图像自动诊断模型。
依据深度学习算法的数字病理图像自动诊断模型需要对数据库中已标记的图像数据进行反复学习,以此对诊断模型的参数进行优化调整,训练优化后的诊断模型可以对未知数据进行识别诊断。
本发明中所用的深度学习算法主要为卷积神经元网络算法,但后继优化训练中还可使用其他算法。
步骤5:使用步骤4中建立的数字病理图像自动诊断模型对未知病变的数字病理切片进行诊断,系统会将识别诊断的h.pylori自动标注显示。将标注诊断结果反馈给病理医生,分析计算识别结果的准确性。
扫描使用的数字病理切片是分辨率高,空间连续的数字图像,为了保证识别的准确性,按照128像素x128像素区域大小进行特征识别判断。
若对未知病变h.pylori的阴阳性诊断准确性高,即获得了理想的卷积神经元网络模型,可以使用此模型对胃组织切片中是否有h.pylori进行判断识别,辅助病理医生诊断参考。
若对未知病变h.pylori的阴阳性诊断准确性需进一步提高,则仍需对样本数据库进行优化识别训练,之后再次判断其识别准确性,直至诊断准确性达到要求。
若对未知病变h.pylori的阴阳性诊断准确性差异较大,此时需要收集更多胃h.pylori阳性切片,病理医生标注采集后收集至数据库,进一步进行特征识别训练,之后再次判断其识别准确性,直至获得了理想的卷积神经元网络模型。
最后应说明的是,上述所述实施方案仅是对本技术方案的说明,并非其限制,本发明的保护范围不限于此。本领域的技术人员应该明白,在不脱离本发明原理的前提下,在形式和细节上对本发明做出的各种细节改变,均为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!