一种基于集成学习融合模型的异常空腹血糖值预警方法与流程
本发明涉及智慧医疗、机器学习领域,具体涉及一种基于集成学习融合模型的异常空腹血糖值预警方法。
背景技术:
随着经济高速发展和工业化进程的加速,生活方式的改变和老龄化进程的加速,是我国糖尿病的患病率正呈快速上升的趋势,称为继心脑血管疾病、肿瘤之后另一个严重危害人民健康的重要慢性非传染性疾病。由中国2型糖尿病防止指南(2013年版)估计,在2005-2015年里,中国由于糖尿病及相关心血管疾病导致的经济损失达5577亿美元,糖尿病不仅给患病个体带来了肉体和精神上的损害并导致寿命的缩短,还给个人和国家带来了沉重的经济负担。
根据糖尿病的发病机理不同,糖尿病主要分为1型糖尿病、2型糖尿病、其他特殊类型糖尿病和妊娠糖尿病、继发性糖尿病。现阶段糖尿病的治愈相当困难,因此预防与及时干预是应对糖尿病最好的手段。血糖异常的检测是糖尿病预警的重要环节,血糖异常的判断方式一般为检测空腹血糖或餐后血糖,当空腹血糖≥7.0mmol/l或餐后血糖≥11.1mmol/l,即可怀疑个体患有糖尿病,应对其进行预警。考虑到人体的各项生理指标相互联系,基于其他生理数据对空腹血糖的预测成为一种可能。
现有的一种基于体检数据建模的空腹血糖预测方法,是使用随机森林利用体检者的体检信息对体检者未来一年的空腹血糖值进行预测,进而得出该体检者对比上一年的空腹血糖值的变化情况,从而判断体检者的糖尿病发病情况,在糖尿病发病前期进行有效的预防或阻断,其中体检者的体检信息包括基本体检信息、血常规检测、血生化检测、尿常规检测、内科、心电图科目下的一种或多种信息共50个体检指标。
该技术首先从海量体检数据中提取出需要的每个体检者的体检信息,并对数据进行清洗和格式化,得到包含所有特征集合的数据集。随后该技术结合序列后向选择算法选择出最优特征子集来作为预测空腹血糖值的特征集合,该步骤首先利用随机森林对特征集合中的每一个特征计算其特征重要性,然后根据序列后向选择算法,将数据集的全部特征集合进行建模,计算其在测试集上的空腹血糖值预测的得分效果,然后依次去掉得分最低的特征后计算其在测试集上的空腹血糖预测的得分效果,直至特征集合中只含有一个体检项,选取具有最大的得分效果的特征集为最优特征子集。最后该技术使用选择了最优特征子集的数据集训练随机森林模型,对血糖的预测值是随机森林中各决策树的血糖预测值的均值。此时,空腹血糖值预测的回归模型建立完毕。该技术能达到一定的预测效果。
但在人体的生理机制上,空腹血糖与其他生理指标具有复杂的关系,用于训练随机森林模型的体检指标(特征)不足,存在的空腹血糖值预测偏差较大的风险。其次使用的随机森林模型作为单一预测模型在连续值的预测上结果的偏差较大,预测精度需要进一步提高。另外,该技术根据下一年的空腹血糖值和当前空腹血糖值的差值作为判断糖尿病病发的风险,并未考虑到空腹血糖值具体值与糖尿病之间的量化关系。
技术实现要素:
本发明的目的是克服现有方法的不足,提出了一种基于集成学习融合模型的异常空腹血糖值预警方法。本发明通过结合个体的血常规、肝功能、血脂、肾功能等体检数据,使用集成学习的方法,融合梯度提升决策树、随机森林、模型线性回归来实现对体检者的空腹血糖值进行预测;通过大量训练数据训练预测模型,从而提高预测模型的精确度、普适性和鲁棒性。
为了解决上述问题,本发明提出了一种基于集成学习融合模型的异常空腹血糖值预警方法,所述方法包括:
从医院获取体检者群体的体检数据,作为原始训练集。
对原始训练集进行数据的缺失值处理、标准化处理。
对处理后的训练集进行特征选取,去除无关特征与冗余特征。
利用所选取的特征,分别作为梯度回归树模型、随机森林模型、线性回归模型的训练集,之后选择线性回归作为元模型来融合训练完成的梯度回归树、随机森林、线性回归预测模型,将三种预测模型的输出作为元模型的输入,再次训练作为元模型的线性回归模型,从而建立完整的预测模型。
使用已训练好的预测模型对用户输入的体检数据进行预测,获得体检数据的空腹血糖预测值,根据预设的阈值判断是否为异常空腹血糖值,并把结果反馈给用户。
优选地,所述获取体检者群体的体检数据,具体包括:
性别、年龄、舒张压、天门东氨酸转移酶、丙氨酸氨基转移酶、碱性磷酸酶、r-谷氨酰基转移酶、淋巴细胞总数、总蛋白、白蛋白、球蛋白、白球比例、甘油三酯、总胆固醇、低密度脂蛋白胆固醇、高密度脂蛋白胆固醇、尿素、肌酐、尿酸、乙肝表面抗体、乙肝表面抗原、乙肝e抗原、乙肝抗体、乙肝核心抗体、白细胞计数、红细胞计数、血红蛋白、红细胞压积、红细胞平均体积、红细胞平均血红蛋白量、红细胞平均血红蛋白浓度、红细胞体积分布宽度、血小板计数、血小板平均体积、血小板体积分布宽度、血小板比积、中性粒细胞%、淋巴细胞%、单核细胞%、嗜酸细胞%、嗜碱细胞%、氯、二氧化碳、钠、钾、钙、镁、磷、尿胆红素、直接胆红素、总胆红素、胆碱酯酶、乳酸脱氢酶、总胆汁酸、胱抑素c、血管紧张素转换酶、超氧化物歧化酶、肌酸激酶同工酶mb、a-羟丁酸脱氢酶、肌酸激酶、超敏c反应蛋白、淀粉酶、载脂蛋白e、免疫球蛋白m、免疫球蛋白a、免疫球蛋白c、免疫球蛋白g、肝胆酸、游离脂肪酸、同型半胱氨酸、转铁蛋白、腺苷脱氨酶、心电图、心率。
优选地,所述建立完整的预测模型,具体包括:
引入具有良好非线性拟合能力的梯度回归树模型作为融合模型的基础模型,根据训练集得到梯度回归树空腹血糖值预测模型;
由于梯度回归树应对过拟合能力较弱,因此引入随机森林模型作为融合模型的另一基础模型,根据训练集得到随机森林空腹血糖值预测模型;
考虑到集成学习中融合的模型差异越大则融合效果越好,因此也引入与上述模型差异较大的线性回归作为融合模型的基础模型,根据训练集得到线性回归空腹血糖值预测模型;
在引入基础模型后,选择线性回归作为元模型来融合训练完成的梯度回归树、随机森林、线性回归预测模型,将三种预测模型的输出作为元模型的输入,再次训练作为元模型的线性回归模型,从而建立完整的预测模型。
本发明提出的一种基于集成学习融合模型的异常空腹血糖值预警方法,结合个体的血常规、肝功能、血脂、肾功能等体检数据,使用集成学习的方法,融合梯度回归树、随机森林、线性回归等模型来对空腹血糖值进行预测,能及时对没有进行空腹血糖检查的个体进行空腹血糖预测,对糖尿病高风险患者进行有效预警。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
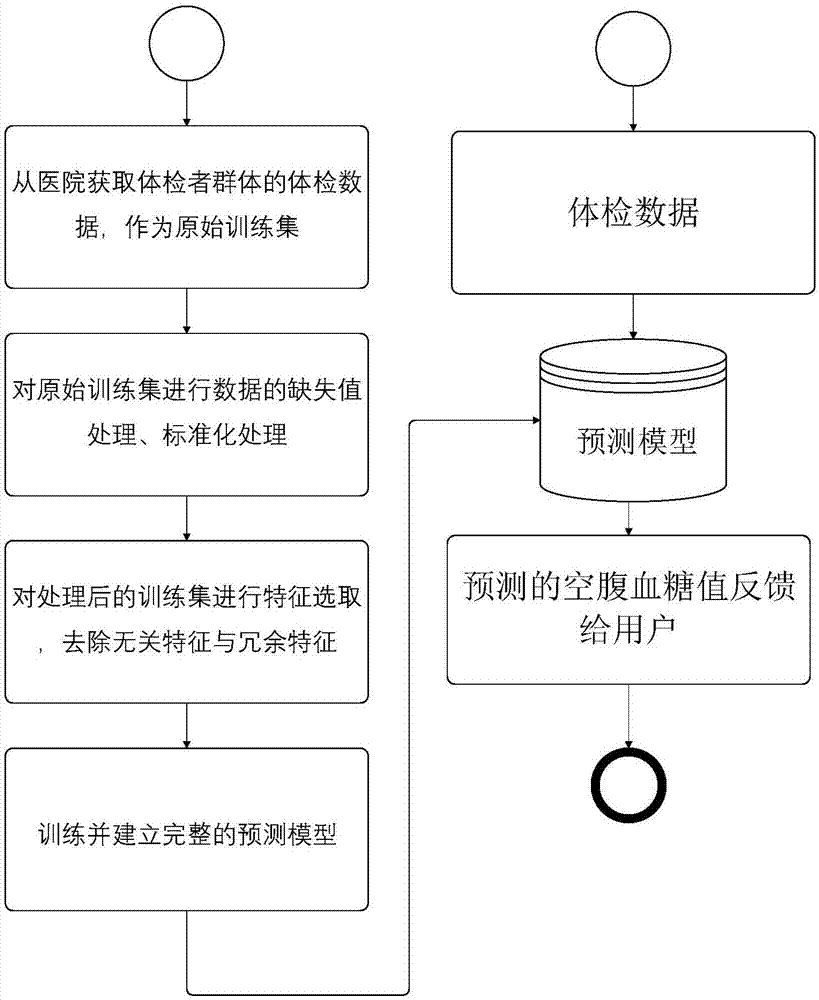
图1是本发明实施例的异常空腹血糖值预警方法流程图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1是本发明实施例的异常空腹血糖值预警方法流程图,如图1所示,该方法包括:
s1,从医院获取体检者群体的体检数据,作为原始训练集。
s2,对原始训练集进行数据的缺失值处理、标准化处理。
s3,对处理后的训练集进行特征选取,去除无关特征与冗余特征。
s4,利用所选取的特征,分别作为梯度回归树模型、随机森林模型、线性回归模型的训练集,之后选择线性回归作为元模型来融合训练完成的梯度回归树、随机森林、线性回归预测模型,将三种预测模型的输出作为元模型的输入,再次训练作为元模型的线性回归模型,从而建立完整的预测模型。
s5,使用已训练好的预测模型对用户输入的体检数据进行预测,获得体检数据的空腹血糖预测值,根据预设的阈值判断是否为异常空腹血糖值,并把结果反馈给用户。
步骤s1,具体如下:
从广东省某医院获取了19802个体检者的体检数据,作为本方法的原始训练集,其中每个体检者的体检信息包括性别、年龄、血常规、肝功能、肾功能、血脂、尿常规等个人以及体检相关数据总共74维特征。
使用的体检信息具体包括:性别、年龄、舒张压、天门东氨酸转移酶、丙氨酸氨基转移酶、碱性磷酸酶、r-谷氨酰基转移酶、淋巴细胞总数、总蛋白、白蛋白、球蛋白、白球比例、甘油三酯、总胆固醇、低密度脂蛋白胆固醇、高密度脂蛋白胆固醇、尿素、肌酐、尿酸、乙肝表面抗体、乙肝表面抗原、乙肝e抗原、乙肝抗体、乙肝核心抗体、白细胞计数、红细胞计数、血红蛋白、红细胞压积、红细胞平均体积、红细胞平均血红蛋白量、红细胞平均血红蛋白浓度、红细胞体积分布宽度、血小板计数、血小板平均体积、血小板体积分布宽度、血小板比积、中性粒细胞%、淋巴细胞%、单核细胞%、嗜酸细胞%、嗜碱细胞%、氯、二氧化碳、钠、钾、钙、镁、磷、尿胆红素、直接胆红素、总胆红素、胆碱酯酶、乳酸脱氢酶、总胆汁酸、胱抑素c、血管紧张素转换酶、超氧化物歧化酶、肌酸激酶同工酶mb、a-羟丁酸脱氢酶、肌酸激酶、超敏c反应蛋白、淀粉酶、载脂蛋白e、免疫球蛋白m、免疫球蛋白a、免疫球蛋白c、免疫球蛋白g、肝胆酸、游离脂肪酸、同型半胱氨酸、转铁蛋白、腺苷脱氨酶、心电图、心率。
步骤s2,具体如下:
s21,数据缺失值处理:
(1)对特征数据进行遍历,对数据中缺失程度大于或等于70%以上的特征的数据进行丢弃。
(2)对特征数据进行遍历,对数据中缺失程度低于70%的特征的数据视为可接受缺失范围,对可接受缺失范围的特征,计算未缺失的数据的平均值,并用该平均值来填补该特征里的缺失数据。
s22,数据标准化处理:
使用min-max标准化方法,对每个特征,根据该特征的最大值和最小值,将该特征里的每一个数据进行线性映射,映射到区间[0,1]中,转化函数为:
其中x为当前特征中当前需要转化的数据,xmax为该特征中数据的最大值,xmin为特征中数据的最小值,x*为根据当前正在转化的数据的转化值。
步骤s3,具体如下:
s31,计算每个特征数据的信息增益,其中每个特征的信息增益gain由以下公式计算:
h(y)=-∑y∈yp(y)log2p(y)
h(y|x)=-∑x∈xp(x)∑y∈yp(y|x)log2p(y|x)
gain=h(y)+h(x)-h(x|y)
其中y表示训练某个数据的空腹血糖值,h(y)表示训练数据的空腹血糖值的信息熵,x表示当前正在计算中的特征的某个数据,h(x)表示特征x的信息熵,h(x|y)表示在特征x下空腹血糖值的信息熵。
s32,对每个特征的信息增益进行标准化,其中标准化的公式如下:
s33,设定阈值,遍历特征,对已标准化的信息增益低于阈值的特征进行筛选去除,去除无关特征。
s34,计算每两个特征之间的皮尔森相关系数,得出特征之间的相关性,其中计算公式如下:
其中x为第一个特征,y为第二个特征,
s35,设定阈值,遍历每一对特征,对于皮尔森相关系数低于阈值的特征对,筛选去除特征对中已标准化的信息增益较低的特征,去除冗余特征。
步骤s4,具体如下:
s41,由于血糖预测涉及的特征维度较高,且特征直接存在多重共线性的问题,普通的线性回归不能很好的解决这一问题,因此引入具有良好非线性拟合能力的梯度回归树模型作为融合模型的基础模型。在此需要使用者根据实际数据集和训练效果对参数进行调优,根据训练集得到梯度回归树空腹血糖值预测模型。
s42,由于梯度回归树属于加性决策树模型,其应对过拟合的能力较弱,为了应对这一问题,引入随机森林模型作为融合模型的另一基础模型。在此需要使用者根据实际数据集和训练效果对参数进行调优,根据训练集得到随机森林空腹血糖值预测模型。
s43,最后考虑到集成学习中融合的模型差异越大,其融合效果越好,因此把与上述模型差异较大的线性回归也作为融合模型的基础模型。根据训练集得到线性回归空腹血糖值预测模型。
s44,在引入基础模型后,选择线性回归作为元模型来融合梯度回归树、随机森林和线性回归。将由步骤s41、s42、s43训练完成的梯度回归树模型、随机森林模型、线性回归模型的输出作为元模型的输入,再次训练作为元模型的线性回归模型。
步骤s5,具体如下:
s51,预测空腹血糖值:
使用已训练的元模型的线性回归空腹血糖值预测模型对输入的体检数据进行预测,获得体检数据的空腹血糖预测值。
s52,判断异常空腹血糖值并预警:
根据空腹血糖预测值是否大于6.1mmol/l判断是否为异常空腹血糖值,若预测的空腹血糖值大于等于6.1mmol/l,则判断该测试者存在异常空腹血糖值,若预测的空腹血糖值低于6.1mmol/l,则判断该测试者为正常空腹血糖值。最后把结果反馈给用户。
本发明实施例提出的一种基于集成学习融合模型的异常空腹血糖值预警方法,结合个体的血常规、肝功能、血脂、肾功能等体检数据,使用集成学习的方法,融合梯度回归树、随机森林、线性回归等模型来对空腹血糖值进行预测,能及时对没有进行空腹血糖检查的个体进行空腹血糖预测,对糖尿病高风险患者进行有效预警。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(rom,readonlymemory)、随机存取存储器(ram,randomaccessmemory)、磁盘或光盘等。
另外,以上对本发明实施例所提供的一种基于集成学习融合模型的异常空腹血糖值预警方法进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!