二分图结构的制作方法
本申请总体上涉及存储的数据的监管(curation)和结构及对其的高效使用。
背景技术:
通常,信息存储在关系数据库中,关系数据库详细描述了数据库中多个对象之间的关系。但是,该信息可以更高效地存储在二分图结构中。
技术实现要素:
本文公开了用于高效地存储数据的二分图结构的描述。二分图结构的示例用途是用作表示生化信息的二分生化数据库,生化信息被组织为包含以下两类节点的二分图:分子和过程。每个分子节点表示分子或由一个或多个生化过程所利用的化学元素。分子节点可以表示小分子,例如水、二氧化碳、质子等,也可以表示大分子,例如dna、rna和蛋白质。分子节点包含描述该分子的多个元数据字段,包括但不限于分子名称、分子式、核酸序列、氨基酸序列、大分子结构、化学修饰(例如甲基化、磷酸化等)、电子电荷,化学或物理属性(pka、熔点、溶解度等)以及组分分子。另外,一些非物理属性可以包括在分子节点的元数据中,包括途径信息、药物相互作用、3d结构等。分子节点不必包含每个前述元数据字段的信息。而是,使用在生化环境中与分子的相互作用有关的字段来描述每个分子。例如,小分子最好用其化学组成来描述,因此核酸序列和大分子结构的字段将不适用。另一方面,充当酶催化剂的蛋白质可能在大分子结构、氨基酸序列和结合位点字段中包含信息,但不包含组成信息,因为它在生化环境中对于分子的功能可能是可变的或不重要的。
过程节点描述了生化环境中的分子作用,包括但不限于化学反应、调节相互作用、结合、转运或其他作用。如同分子节点,过程节点包括许多描述性元数据字段,这些元数据字段提供有关过程的信息,包括但不限于分子列表及其在过程中的相关联角色、反应速率信息以及过程的能量需求、过程中可能涉及的子过程或其他更详细的信息。
除了分子和过程节点外,生化数据库还包含节点之间的边,这些边定义每个分子在每个过程中的角色以及分配给该角色的化学计量系数。每个边将分子节点与过程节点相关联,从而定义数据库的二分结构。每个边还包含表征在相关联的过程中相关联的分子的角色的附加元数据。任何相关的表征都是可能的,包括但不限于反应物/底物、催化剂、产物或辅因子。
生化数据库的结构有助于在定义的生化环境中确定分子相互作用或确定一组特定分子相互作用所需的生化环境的高效方法。例如,通过选择定义生化环境的一组分子节点并遍历二分图,可以确定在生化环境中可能发生的一组生化相互作用。替代地,可以选择一组期望的过程节点,并且通过遍历该图,可以确定在所选择的该组过程中扮演角色的对应的一组分子。更一般地,生化数据库提供有关生化环境中各种过程与分子之间关系的洞察。另外,由于二分图中的所有边都将分子节点连接到过程节点,因此可以通过搜索图中的边来更高效地完成出于生化模拟目的的信息检索,而不搜索通过较混乱的图结构中的节点。图的二分性质还可以用于快速识别生化系统中的“死端”分子。死端分子可以是过程的产物,而不在任何其他反应中用作底物或催化剂,或者其可以是反应的底物,而不在生化环境中通过任何其他过程产生。在识别死端分子之后,可以引导附加研究以确定它们在生化环境中如何产生或如何利用它们。二分图结构还可以用于通过从死端分子遍历图并消除从死端分子产生或促成死端分子的过程和分子来从生化环境中删减分子和过程。
附图说明
图1是示出根据一个实施例的二分生化数据库的框图。
图2是示出根据一个实施例的分子节点的示例的框图。
图3是示出根据一个实施例的过程节点的示例的框图。
图4是示出根据一个实施例的示例生化反应中包括的节点和边的框图。
图5是示出根据一个实施例的识别可能在生化环境中发生的过程的方法的流程图。
附图仅出于说明的目的描绘了本发明的各种实施例。本领域技术人员将从下面的讨论中容易地认识到,在不脱离本文描述的本发明原理的情况下,可以采用本文所示结构和方法的替代实施例。
具体实施方式
一、数据库结构
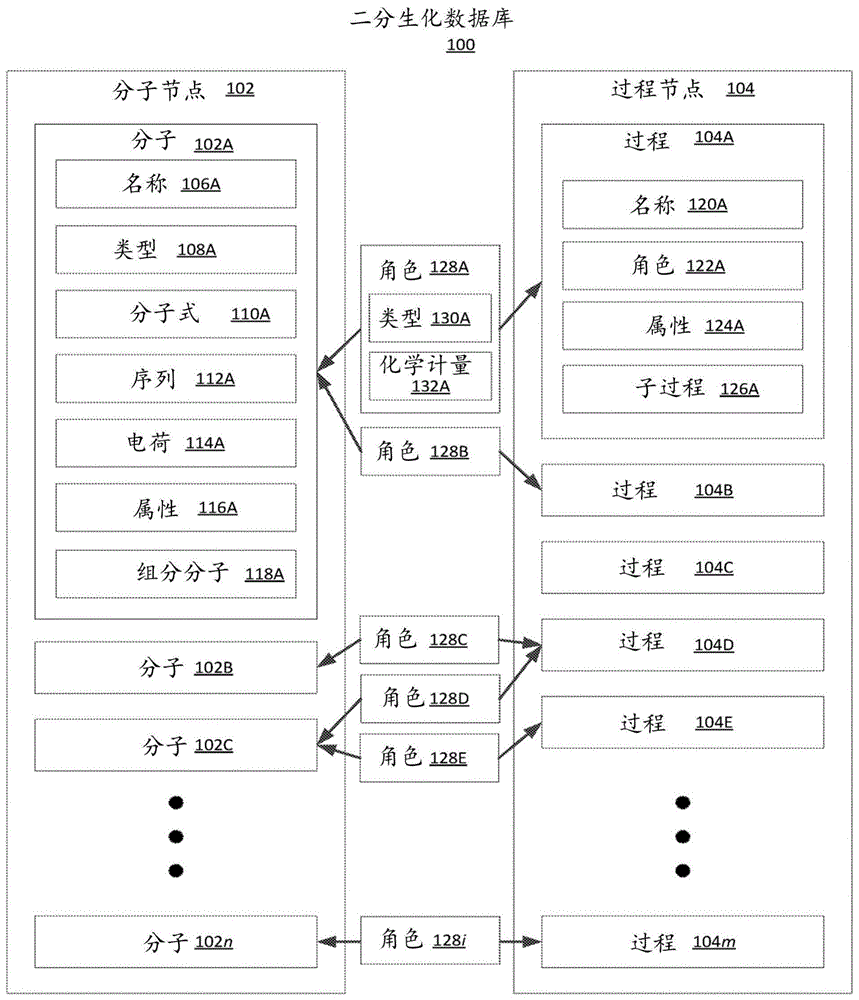
图1是示出根据一个实施例的二分生化数据库的框图。二分生化数据库100包含表示一个或多个生化环境的组成和行为的数据。生化环境的示例可以包括细胞内环境、细胞的特定细胞器中的环境、整个细胞、细胞间环境或生物学中发现的或在生物学模拟中可以想象到的任何类似环境。数据库的二分性质是指构成数据库的两种类型的数据库对象或节点,其可以被分类为“分子节点”102和“过程节点”104。分子节点102可以表示生化环境中存在的任何分子或其他物理粒子,包括原子元素、离子、化合物、核酸、蛋白质和其他大分子。过程节点104可以表示化学反应、蛋白质折叠、转运、调节相互作用、活性位点结合或在生化环境中可能发生的任何其他物理或化学过程。二分生化数据库100以图结构组织,其中,上述提到的两类节点通过边连接。每个边在本文中被称为“角色”128,并将单个分子节点102与过程节点104相关联,从而创建分子102和过程104节点的二分图。
可以使用各种的非关系数据库软件选项来实现二分生化数据库100。利用非关系数据库的实施例在允许提高创建表示生化分子和过程的节点的灵活性方面提供优点。生化环境通常包括几种不同类型的分子,例如,除了简单的化合物(例如水和葡萄糖)之外,还包括大分子,例如核酸链和蛋白质。由于分子类型的多样性,可以使用非关系数据库来允许各种文档(例如json、xml或其他格式)来表示二分生化数据库100的节点和边。替代地,例如orientdb、arangodb、allegrograph或任何其他合适的数据库框架之类的图特定数据库技术可用于实现二分生化数据库100。本领域技术人员将理解,本文所述的数据库结构可使用各种可用的数据库软件选项来实现。二分生化数据库的图结构的其他益处在下面进一步描述。
每个分子节点102包含分子元数据字段,该分子元数据字段提供关于节点表示的分子的信息,该信息与所表示的分子在生化环境中的行为有关。这些分子元数据字段可以包括分子名称106、分子类型108、分子式110、分子序列112、分子电荷114、分子属性116和组分分子118。图1示出了分子节点102a、102b、102c至102n,并示出了与分子节点102a对应的元数据字段106a、108a、110a、112a、114a、116a和118a。然而,每个其他所示的分子节点102也可以包含相同或相似的分子元数据字段。
分子节点102不需要包含上述每个元数据字段的数据,并且取决于实施例,根据数据库的特定应用的需要,分子节点102中可以包括更少或附加的字段。在一些实施例中,可以将唯一id分配给每个分子节点102,以在数据库中更容易地查询和参考。由于在生化环境中发现的各种类型的分子在其复杂性和与其他分子相互作用机制上各不相同,因此不同的字段可能适用于每种类型的分子。这样,尽管存在于分子节点102的数据结构中,但上述提到的某些字段对于某种类型的分子节点102可能被留空。
在一些实施例中,分子节点102的分子名称字段106包含指示由分子节点102表示的分子的人类可识别的字符串。为分子节点102选择的名称106可以由用户将数据输入二分生化数据库100中来确定或可以基于为该分子提供的其他元数据自动生成。可以使用本领域技术人员已知的用于生化分子的各种命名方案来确保每个分子节点102的名称106的一致性。
在一些实施例中,分子类型字段108指示所表示的分子所属的分子类别。通常基于二分生化数据库100的应用来设置类别,并且可以在输入二分生化数据库100时为每个分子分配类型。类型字段108本身可以包含指示由分子节点102表示的分子所属的类别的字符串或类型id号。分子的可能类别的示例可以包括离子、原子元素、化合物、有机化合物、核酸(dna,rna等)、氨基酸链、蛋白质等。在一些实施例中,利用二分生化数据库100的应用可以参考分子节点102的类型108以确定可以从分子节点102检索的属性116或其他元数据。例如,如果由分子节点102表示的分子具有指示其为“蛋白质”的类型108,则访问分子节点108的任何应用都可以被配置为从分子节点102的属性字段116检索蛋白质结构、结合位点信息和氨基酸序列。在替代示例中,如果分子节点102具有指示其为化合物的类型108,则访问分子节点的应用可以被配置为从分子节点102检索分子式、分子量、溶解度和/或其他信息。
在一些实施例中,分子节点102的类型108可以指示节点本身的结构。例如,存在于分子节点102中的元数据字段可以与分子节点的被分配的类型108对应。例如,指示分子序列的元数据字段只有在其已被分类有与核酸、氨基酸链或蛋白质对应的类型108的情况下,才可能出现在节点的结构中。这可以通过在将分子节点102添加到二分生化数据库100中时需要在类型字段108中输入,并且在初始化二分生化数据库100中的分子节点102时,基于接收的类型108来结构化分子节点102来实现。
在一些实施例中,分子式字段110指示由分子节点102表示的分子的分子或化学式。分子式110可以是指示构成所表示的分子的原子元素的字符串,或者在某些类型的分子的情况下,可以是指示该分子式是可变的或不适用于该分子在感兴趣生化环境中的行为的字符串。在一些实施例中,分子式110以符合本领域已知的特定分子式惯例的标准化格式表示。在一些实施例中,分子式还可以指示分子的电荷或具有与指示关于所表示分子的分子结构的附加细节的字符串相关联的修饰符。例如,可以提供附加字符串,其指示具有多个异构体的化合物的特定异构体(在其他实施例中,该信息在属性字段116中提供)。
在一些实施例中,序列字段112指示由分子节点102表示的分子的序列。并非所有类型的分子都包含序列信息,但是核酸的核苷酸序列或蛋白质的氨基酸序列可能是描述分子的生化上最相关的方式。因此,仅当由分子节点表示的分子是某种生物聚合物时,序列信息才可能存在于序列字段112中。序列信息112通常是指示构成所表示分子的单体的顺序的字符串。序列信息可以使用与由分子节点102表示的分子的类型108对应的标准符号。例如,如果分子节点102表示dna链并且被标记为具有“dna”的类型108,则序列信息112是字符串,该字符串包括分别表示腺嘌呤、胸腺嘧啶、胞嘧啶和鸟嘌呤的a、t、c和g序列。在替代示例中,表示蛋白质的分子节点102可以包括指示该蛋白质的氨基酸序列的序列信息112。
在一些实施例中,电荷字段114指示由分子节点102表示的分子的电子电荷。电荷字段114可以由指示该分子的电子电荷的整数值构成。例如,如果分子节点表示氢离子,则电荷字段114将指示“1”,其指示正电荷。在一些情况下,分子的电荷会是可变的,尤其是如果该分子是大分子并且可以以许多不同的状态出现时,在这种情况下,电荷字段114将具有指示电荷是可变的值。在一些情况下,由分子节点102表示的分子的电荷可能不适用于其在生化环境中的行为,因此,在一些实施例中,电荷字段114可以包含指示如此的字符串。
在一些实施例中,属性字段116提供关于由分子节点102表示的分子的相关化学和物理属性的信息。在一些实施例中,属性字段116的内容可以是键值对阵列,其指示相关属性及其对应值。在属性字段116中列出的属性可以根据由类型字段108指示的分子的类型而变化。例如,小分子和化合物可以具有指示与所表示的分子相关联的标准物理属性的属性116,包括例如熔点、摩尔质量、密度、溶解度、酸度、形成焓或任何其他相关的化学和物理属性。在一些实施例中,属性字段116可以包含对于未知或与特定分子不相关的每个属性的空值。在较大的大分子中,可以在属性字段116中指示其他属性,例如蛋白质的结合状态、蛋白质的折叠状态、dna链的甲基化状态以及其他相关的大分子属性。另外,一些属性可以被用于描述所表示的分子与其他分子之间的相互作用。例如,可以在属性字段116内描述蛋白质的活性位点或dna链的结合域。在一些实施例中,属性元数据字段116还可以包括蛋白质的三维模型、蛋白质的小分子相互作用或分子的途径信息。在其他实施例中,这些属性可以在分子节点102中的附加元数据字段中表示。
在一些实施例中,组分分子字段118指示构成由分子节点102表示的分子的分子。组分分子可以是可能有助于形成所表示的分子的任何分子,并且它们可以由字符串表示,该字符串指示每个组分分子的名称106。一些示例包括可以占据蛋白质结合位点的分子、构成核酸的核苷酸、分子化合物的组分、特定酸的共轭碱等。组分分子字段118可以包括指示组分分子的字符串列表,或在某些实施例中,包括指示组分分子的唯一id号列表。
图1示出了多个分子节点102a、102b、102c至102n,并且取决于所使用的数据库技术,根据二分生化数据库100的应用的需要,可以将其扩展为包括任何数量的分子节点102。
除了分子节点102之外,二分生化数据库100还包括过程节点104。如前所述,过程节点104可以描述在生化环境中可能发生的任何类型的物理或化学过程。每个过程节点104包含描述由过程节点104表示的过程的过程元数据字段,包括但不限于过程名称120、过程122中的角色、过程124的属性以及过程126的子过程。如同二分生化数据库100中的分子节点102中,取决于被表示的特定过程,过程节点104的过程元数据字段可能为空,在这种情况下该字段的元数据将不适用。
在一些实施例中,名称元数据字段120包含人类可识别的字符串,该字符串标识由过程节点表示的过程。如同分子节点102的名称字段106,在一些实施例中,除了过程节点120的名称120之外,还可以包括该过程的id号。在一些实施例中,可以使用名称120或对应的唯一id作为对二分生化数据库100中相关联的过程节点120的参考。
在一些实施例中,过程节点104包括角色元数据字段122,其列出在由过程节点104所表示的过程中分子的角色。在生化环境中发生的过程至少对一个分子或该环境中的其他元素起作用。但是,并非过程中涉及的所有分子在该过程中都一定具有相同的“角色”。例如,大多数化学反应具有引发反应所需的一组底物分子和作为反应结果产生的一组产物。因此,基于在过程中相关联的分子的作用来表征与该过程相关联的分子。在一些实施例中,二分生化数据库中可包括以下角色分类:底物/反应物、催化剂、产物或辅因子。在包括表示物理过程的过程节点104的实施例中,同一分子可以被包括在多个角色中。例如,如果过程节点104表示蛋白质从细胞的内质网向高尔基体的转运,则角色字段122可能具有两个角色,包括“离开分子”和“目的地分子”。尽管同一分子可以由两个单独的分子节点102表示(每个节点分别表示处于细胞中不同位置的分子),但这两个角色中的每一个都可以由该同一分子满足。包括被表示为过程节点104的物理过程的实施例可以使能利用二分生化数据库100的应用以创建生化环境的更详细的模拟,其考虑了在生化环境中发现的分子的化学和物理转变。另外,分子也可能在同一过程中扮演多个角色。例如,在某些过程中,蛋白质可能既是底物又是催化剂。在这些情况下,可以在过程节点104中为同一分子创建两个角色。
角色字段122中的数据的结构可以是包括标识角色的类型和满足所表示的过程中的该角色的分子的字符串对的阵列。在其他实施例中,本领域已知的其他数据结构可以用于存储相同的信息。角色元数据字段可以参考表示在角色字段104中列出的分子的分子节点102。替代地,角色字段122可以包括对角色边128的参考,角色边128表示在二分生化数据库100的过程中分子扮演的角色。
在一些实施例中,过程属性字段124列出了由过程节点104表示的过程的属性。在生化环境中发生的过程具有可能对于模拟或数据收集目的感兴趣的各种属性。因此,二分生化数据库100可以将属性存储在过程节点104的属性字段124中的阵列或其他数据结构中。在化学反应的情况下,活化能、吉布斯自由能变化、运动学属性和本领中已知的其他热力学属性可以包括在属性字段124中。对于物理过程,除了在生化环境中可能发生的任何其他物理过程之外,其还可以包括蛋白质折叠操作和在细胞内环境中的分子移动,可以在属性字段124中列出。
在一些实施例中,子过程字段126存储由过程节点104表示的过程的子过程。在生化环境中发生的许多过程可以在多个步骤中发生。特别是出于确定反应速率的目的(通过识别速率限制步骤),维护构成由过程节点104表示的过程的子过程的信息是有用的。子过程126可以由名称120或唯一id号参考,并且通常在二分生化数据库中具有单独的节点。
在一些实施例中,二分生化数据库100中的两种类型的节点使用边(在本文中称为“角色”128)彼此相关联,这些边表示相关联的分子在相关联的过程中扮演的角色。角色128本身可以被结构化为使得它们包含指向相关联的分子节点102和相关联的过程节点104的直接指针。除了包含指向相关联的分子节点102和相关联的过程节点104的指针之外,角色对象128还可以包含元数据,该元数据指示由相关联的分子节点102表示的分子在由相关联的过程节点104表示的过程中扮演的角色类型130。另外,角色128包含在所表示的过程中所表示的分子的化学计量值。这些边128确保在涉及生化环境模拟的应用中,在每个反应中保持准确的化学计量关系。在一些实施例中,角色128可以在图中具有定义的方向性。该方向性可以指示由相关联的分子节点102表示的分子在由相关联的过程节点104所表示的过程中是被消耗还是产生。二分生化数据库中角色128的方向性可以与以下描述的角色类型相关。在具有角色方向性的实施例中,利用有向图的数学技术可以被利用二分生化数据库的应用所利用。
如先前关于过程节点104中的角色字段122所述,角色类型130可以是化学过程的底物/反应物、催化剂、产物或辅因子之一,并且可以是物理过程中的可以准确地描述相关联的分子在相关联的物理过程中的行为的任何适用角色。角色类型130可以存储为描述角色类型的字符串或通过本领域中已知的任何其他有效手段来存储。在利用有向图的实施例中,角色128的方向性可以与角色类型130对应。例如,底物/反应物的角色类型130将导致从相关联的分子节点102到相关联的过程节点104的方向性,而产物的角色类型130将导致从相关联的过程节点104流动到相关联的分子节点102的方向性。其他角色类型130(例如催化剂或辅因子)可以与双向角色边128对应,因为由分子节点102表示的分子在相关联的过程发生之前和之后仍然存在。
在一些实施例中,化学计量系数元数据字段132存储在相关联的过程中相关联的分子的化学计量系数。化学计量系数指示每个分子在特定过程中具有角色的比率,并提供用于确定分子在生化环境中的通量的框架。角色128的化学计量系数132可由与表示与角色128相关联的过程的化学方程式中的化学计量系数的值相等的正整数表示。对于物理过程,相反,化学计量系数可以基于分子之间正由相关联的过程表示的任何物理相互作用。
图1示出了包括分子节点102a、102b、102c的n个分子节点102,包括过程节点104a、104b、104c、104d和104e的m个过程节点104,以及包括128a、128b、128c、128d和128e的i个角色边128。这示出了可以存在不同数量的分子节点102、过程节点104和角色边128,并且分子节点102与过程节点104不必一对一匹配。另外,如示出分子节点102、角色128和过程节点104之间的示例连接的箭头所展示,分子节点102可以与多个过程节点104相关联,反之亦然。例如,分子节点102a被示为分别通过角色边128a和128b连接到过程节点104a和过程节点104b。因此,基于图示的映射,由分子节点102a表示的分子参与由过程节点104a和104b表示的过程。
二、示例
图2-4示出了上述二分生化数据库100的可能实施方式。每个示出的示例仅示出了二分生化数据库的一种可能的实施方式,并且出于本文讨论的目的而被简化。例如,在一些实施例中,附加的生化数据将是可用的并且将被存储为元数据。在其他实施例中,在以下示例中未示出的例如表示蛋白质结构或其他大分子行为的3d模型之类的更复杂的数据可以存储在二分生化数据库100中。如图所示的文本可以表示以各种可能的数据库格式存储的数据,并且可以表示比图2-4中所示更为复杂的数据结构。
图2是示出根据一个实施例的分子节点的示例的框图。图2示出了上述二分生化数据库100中的分子节点102的三个示例,包括表示草酰乙酸200、水214和柠檬酸合酶228的节点。
草酰乙酸节点200具有类型108“化合物”202,由此指示草酰乙酸是化合物(当不在水溶液中时,其可解离成共轭碱、草酰乙酸盐或酯和质子)。节点的分子式字段110包含指示草酰乙酸的组成的字符串“ho2cc(o)ch2co2h”。草酰乙酸节点200的序列元数据字段112将由空值206或指示草酰乙酸没有序列数据的表示性字符串表示。在替代实施例中,序列字段112可以不存在于具有“化合物”类型的分子节点102中。草酰乙酸节点200的电荷字段114存储值“0”210,指示草酰乙酸具有中性电荷。草酰乙酸节点200的属性字段116包括草酰乙酸的各种化学和物理属性的多个值210,包括摩尔质量为132.07g/mol、密度为0.18g/mol、熔点为434k、标准形成焓为-943.21kj/mol及pka为3.89。在一些实施例中,属性字段116可以包括草酰乙酸的附加属性。草酰乙酸节点200的组分分子字段118包含字符串“草酰乙酸根离子”和“质子”,其指示这些草酰乙酸中的分子组分。
在附加示例中,分子节点102表示水(h2o)。在该示例中,该节点的名称106可以简单地是“水”。在该示例中,水的类型108是“无机化合物”216,指示水是无机化合物。水的分子式110为“h2o”218。如同草酰乙酸的情况,在水节点214的序列字段中未存储序列信息112。电荷字段114指示零的值222,并且属性字段116存储水224的物理属性,包括摩尔质量为18.02g/mol、密度为1g/mol及熔点为273.15k。在一些实施例中,附加数据可以存储在属性字段中,指示分子的物理属性如何会在不同的温度和压力条件下发生变化。组分分子字段118包含表示氢和氧的字符串或其他数据226。
在另外的示例中,图2示出了表示柠檬酸合酶228的分子节点102。在这种情况下,分子节点102的名称106将为“柠檬酸合酶”或标识该分子的其他字符串。柠檬酸合酶节点的类型108将是“蛋白质”230,并且在一些实施例中还可以指示蛋白质的折叠状态。柠檬酸合酶的分子式字段110包含空值232或表示该蛋白质的分子式不适用或不用于其在生化环境中的行为的事实的字符串。然而,序列字段112包含表示该蛋白质的氨基酸序列的字符串234。柠檬酸合酶节点228的电荷字段114指示蛋白质236的电荷取决于等电点和环境的ph而变化。在一些实施例中,如果关于蛋白质的等电点的信息可用,则可以将该信息存储在电荷字段114中。柠檬酸合酶节点238的属性字段116以数字、类别方式或通过使用3d模型和本领域已知的描述蛋白质结构和动力学的其他方法来描述该蛋白质的结构和该蛋白质的动力学属性。柠檬酸合酶节点的组分分子字段118指示构成柠檬酸合酶蛋白240的氨基酸。
图3是示出根据一个实施例的过程节点的示例的框图。图3示出了两个示例过程节点104、柠檬酸合酶反应节点300和囊泡转运节点308。柠檬酸合酶反应节点300表示合成柠檬酸的化学过程,而囊泡转运节点308表示在细胞环境中将未特指蛋白质从一个位置移动到另一个位置的物理过程。
柠檬酸合酶反应节点300的角色元数据字段122存储描述柠檬酸合酶反应的底物、催化剂和产物的数据302,从而列出h2o、乙酰辅酶a和草酰乙酸作为底物,柠檬酸合酶作为催化剂,和产物为h+、辅酶a和柠檬酸。该数据指示通过角色边128与柠檬酸合酶反应节点300相关联的分子节点102。柠檬酶合酶反应节点300的属性字段124包括反应的吉布斯自由能变化,并且可以包括关于反应动力学或实验速率数据的其他细节。柠檬酸合酶反应节点300的子过程元数据字段126指示可以构成柠檬酸合酶反应的任何子过程。子过程字段126指示“乙酰辅酶a烯醇生成”和“柠檬酸生成”是柠檬酸合酶反应的子过程。在一些实施例中,子过程字段126可以包含到存储在其中的子过程的直接链接。
囊泡转运节点308的角色字段122指示由于该节点所表示的过程是物理过程,因此由于没有化学变化发生,相同的分子扮演了两个角色。然而,在二分生化数据库100中包括物理过程的实施方式中,可以将单独的分子节点102分配给相同分子以表示该分子的不同物理状态。例如,尽管相同的蛋白质满足柠檬酸合酶反应节点308“蛋白质x”的两个角色,但是可能存在两个表示蛋白质x的分子节点102。一个表示内质网中的蛋白质x“蛋白质xer”,而另一个表示线粒体中的蛋白质x“蛋白质x线粒体”。表示囊泡转运过程的过程节点的属性字段124包含速率信息312,该速率信息312与蛋白质从内质网到线粒体的转运有关。在其他实施例中,可以包括关于物理过程的附加信息。囊泡转运节点308的子过程字段126包括表示内质网处的囊泡分泌和线粒体处的囊泡融合的子过程。
图4是示出根据一个实施例的示例生化反应中包括的节点和边的框图。图4示出可以构成二分生化数据库100的图的一小部分。特别地,图4示出了与柠檬酸合酶反应相关联的分子节点102和过程节点104。图4示出了七个分子节点h2o214、乙酰辅酶a400、草酰乙酸200、h+402、辅酶a404、柠檬酸406和柠檬酸合酶228。这些分子节点102分别通过角色边408、410、412、416、418、420和414与柠檬酸合酶反应过程节点300相关联。每个边定义了由分子节点102表示的每个分子在柠檬酸合酶反应中的角色。
三、二分数据库结构的优点
二分生化数据库结构100在模拟和理解生化环境方面提供了许多优点。包括使用直接指针的边的基于图的结构允许快速遍历图。因此,当就其分子组分来描述生化环境时,二分生化数据库可用于通过从生化环境中的已识别分子开始快速遍历图来确定在该环境中可能发生的化学和物理过程。替代地,如果要模拟一组过程,则可以通过从要模拟的过程开始的图遍历来识别这些过程中涉及的分子组。
图5是示出根据一个实施例的识别可能在生化环境中发生的过程的方法的流程图。图5所示的方法可以由一个或多个处理器完成,该一个或多个处理器配置有指令以通过利用二分生化数据库100来执行所示步骤。
示出的利用二分生化数据库100识别生化环境中发生的过程的方法以接收500生化环境的分子组成开始。分子组成可以通过实验过程确定,或者可以创建为用于模拟的假设环境。接收的组成数据可以包括分子名称106的列表或唯一的。然后使用二分生化数据库100来识别502表示接收的分子组成中的分子的分子节点102。如果以名称106的列表的形式接收分子组成数据,则可以通过在二分生化数据库100中查询列表名称106来完成识别。在一些实施例中,可能需要进一步的处理来识别表示接收的分子组成数据的分子节点102。在一些实施例中,利用二分生化数据库100的应用将通知用户二分生化数据库100中未表示但已在分子组成数据中接收的分子。在通知缺失的分子节点后,可以将表示分子的节点添加到二分生化数据库100中。
一旦已经识别出一组分子节点102,就通过遍历生化数据库102,二分生化数据库被识别504附加的分子或过程l。二分生化数据库100是有向图,该图的遍历将遵循角色128的方向性。替代地,过程节点104不被识别为与所识别的一组分子节点102相关联,除非该过程的所有产物/反应物角色由所识别的分子节点102之一提出。在图遍历中被识别的附加分子节点(与在分子组成数据中接收的不同)可能是未包括在所接收的分子组成数据中的子过程之间的过渡分子。这些附加分子可以通知研究人员生化环境中可能存在先前未检测到的附加分子。本领域的技术人员将会认识到,根据实施例,许多图遍历算法都可用于实现步骤504,包括广度优先搜索或深度优先搜索。
根据实施例,在遍历504二分生化数据库100以识别过程节点104和附加分子节点102之后,可以从所识别的节点组中删减506“死端(dead-end)”分子节点。“死端”节点是对于其作为反应物/底物来说或对于其作为产物来说没有识别的过程的分子节点102。物理上,如果没有数据库中不存在或不可能的附加过程,这些死端分子就不可能积累或消耗。由于这些原因,将这些分子从所识别的分子节点102删减,并且取决于实施例,可以对其进行识别以用于进一步研究。在一些实施例中,删减过程506可以是递归的,因为在已经从所识别的组中去除了第一组死端分子节点之后,递归过程确定是否留下了任何过程节点而没有所有相关联的角色被占用。如果识别出任何过程,则也将它们从所识别的组中删减掉,这将导致递归过程继续进行到删减死端分子节点的下一步。
在删减过程完成之后,结果是来自数据库中所有节点的较大组中的识别出的分子节点102和过程节点104的子组,该子组表示会存在于具有由接收的分子组成数据指示的分子组成的生化环境中的过程和分子。然后,可以将这些识别的过程和分子用于模拟或用于对生化环境进行进一步研究。
本领域技术人员将会理解,可以实现类似的方法来识别假设为实现接收的一组生化过程必需的一组分子。在这种情况下,图遍历将改为从一组接收的过程节点104开始,而不是从一组接收的分子节点102开始。
四、其他注意事项
本说明书的某些部分就算法和对信息操作的符号表示来描述本发明的实施例。这些算法描述和表示通常由数据处理领域的技术人员用来将其工作的实质有效地传达给本领域的其他技术人员。这些操作虽然在功能上、在计算上或在逻辑上进行了描述,但应理解为由计算机程序或等效电路、微代码等来实现。此外,不失一般性,有时将这些操作布置称为模块有时也很方便。所描述的操作及其关联模块可以以软件、固件、硬件或其任何组合来实现。在一个实施例中,用计算机程序产品来实现软件模块,该计算机程序产品包括包含计算机程序代码的持久性计算机可读介质,该计算机程序代码可以由计算机处理器执行以执行所描述的任何或所有步骤、操作或过程。
最后,主要为了可读性和指导性目的选择了本说明书中使用的语言,并且可能没有将其选择为描绘或限制本发明的主题。因此,意图是本发明的范围不受该详细描述的限制,而是由基于其的申请所发布的任何权利要求所限制。因此,本发明的实施例的公开旨在是说明性的,而不限制本发明的范围,其示例在所附权利要求中阐述。
- 还没有人留言评论。精彩留言会获得点赞!