婴儿启动的音频播放器的使用的制作方法
相关申请的交叉引用
以下申请要求35u.s.c.§371下2018年10月8日提交的标题为“utilizationofinfantactivatedaudioplayer”的国际pct申请号pct/us08/xxx,xxx的优先权,该pct申请于2019年xx月xxx日以国际公开号wo/2019/xxx,xxx公开,并且要求35u.s.c.§119(e)下2017年10月9日提交的标题为“utilizationofinfantactivatedaudioplayer”的美国临时专利申请号62/569,088的优先权。要求所有上述申请和公开的优先权,为了所有目的,以引证的方式将所有上述申请和公开整体并入本文。
本公开总体涉及一种音频装置和传感器组合,更具体地涉及一种用于新生儿护理中的音频装置和传感器组合,该组合具有和不具有用于使用口运动反应来刺激并改善婴儿、未足月婴儿和/或/早产婴儿的语音辨别的系统。
背景技术:
研究已经表明,未足月和早产婴儿和/或天生具有神经系统损害的婴儿具有因住院治疗(例如,存活所必需的住院治疗)而产生的迟缓和/或损害。音频互动(特别是父母的音频互动)的缺乏是导致发育迟缓和/或损伤的主要原因。缺乏这种音频互动的婴儿往往具有较差的语音辨别。婴儿和未足月婴儿都有发生语音辨别的时间窗。在该时间窗期间,与足月婴儿相比,未足月婴儿的声音辨别减弱。未足月婴儿减弱的声音辨别在预测两岁时有较差语言结果。
通常,未足月和早产婴儿被收容在不足月婴儿人工抚育器或婴儿床中。未足月和早产婴儿保持每天两到三次肌肤接触,持续约四十五(45)分钟。这些未足月和早产婴儿通常缺乏父母的互动,由此,缺乏正常的父母刺激以及这种互动产生的益处。
技术实现要素:
本公开的一个方面包括一种利用口运动装置来启动音频装置的方法,该方法包括以下步骤:提供口运动装置,该口运动装置包括传感器和可压下部,当可压下部被压缩,产生超过施加于可压下部的适合年龄的预定阈值的第一测量压力时,产生输出信号;响应于输出信号,在音频装置上播放适合年龄的音频记录预定持续时间;以及将适合年龄的预定阈值与到可压下部的第一测量压力和适合年龄的预定阈值之间的差成比例地增加到升高的阈值。
本公开的另一个方面包括一种存储机器可执行指令的非暂态计算机可读介质,这些指令用于利用口运动装置来启动音频装置,该存储机器可执行指令的非暂态计算机可读介质包括与音频装置进行电子通信的语言系统、包括传感器的感测装置以及接口,该接口被配置为接收用户数据,并且感测装置被配置为向语言系统发送信号,该语言系统提供以下中的至少一个:用于感测装置传感器使用的第一推荐或第二推荐、感测装置的传感器阈值和传感器读数、音频输出的持续时间以及音频输出的特定参数。语言系统基于来自感测装置的、指示传感器阈值已被超过的信号,将指令发送到音频装置,以在音频输出的指定的持续时间内发出适合的音频记录,该音频记录符合音频输出的特定参数。
本公开的又一个方面包括一种语言系统,该语言系统包括与口运动装置耦接的音频装置。该系统包括口运动装置,该口运动装置包括收容传感器的奶嘴,其中,当所述奶嘴部被压缩到超过第一测量压力的压力时,传感器产生输出信号,该第一测量压力超过适合年龄的预定阈值。音频装置包括与口运动装置电通信的微型计算机、麦克风、扬声器以及接口,微型计算机包括语言算法,语言系统响应于经由接口接收的用户输入,分配口运动装置的传感器阈值和传感器读数,分配音频输出的持续时间,并且识别用于音频输出的特定参数,语言系统基于来自口运动装置的指示适合年龄的预定阈值已经被超过的输出信号,将指令发送到音频装置,以在音频输出的指定的持续时间内发出适合的音频记录,该音频记录符合音频输出的特定参数。
附图说明
本公开的前述和其他特征和优点将在参照附图考虑本公开的以下描述时对本公开与其有关的领域中的一个技术人员变得清楚,在附图中,除非另外描述,否则同样的附图标记贯穿附图指同样的零件,并且附图中:
图1例示了根据本公开的一个示例实施方式的口运动装置和音频装置的立体图;
图2例示了根据本公开的一个示例实施方式的、沿着图1的剖面线2-2截取的图1的口运动装置;
图3例示了根据本公开的第二示例实施方式的、沿着图1的剖面线2-2截取的图1的口运动装置;
图4a例示了根据本公开的第三示例实施方式的、沿着图1的剖面线2-2截取的图1的口运动装置;
图4b例示了根据本公开的第四示例实施方式的、沿着图1的剖面线2-2截取的图1的口运动装置;
图5例示了根据本公开的一个示例实施方式的、在音频装置中收容的电气元件的电气示意图;
图6例示了根据本公开的第一示例实施方式的、使用音频装置的方法的流程图;
图7例示了根据本公开的第二示例实施方式的、使用音频装置的方法的流程图;
图8例示了根据本公开的第三示例实施方式的、使用音频装置的方法的流程图;以及
图9例示了根据本公开的另一个示例实施方式的、用于利用在音频装置中使用的系统的流程图。
技术人员将理解,附图中的元件为了简化和清晰而例示,并且不是必须被绘制为等比例。例如,附图中的一些元件的尺寸可以相对于其他元件放大,以帮助改善本公开的实施方式的理解。
设备和方法组成部分在适当情况下已经由附图中的常规附图标记来表示,附图仅示出了与理解本公开的实施方式有关的那些具体细节,以便不会由于将对具有这里描述的益处的本领域中的普通技术人员容易明显的细节而使本公开模糊。
具体实施方式
现在总体参照附图,除非另外注释,否则内部示出的同样附图标记贯穿附图指同样的元件。本公开总体涉及一种音频装置和传感器组合,更具体地涉及一种用于新生儿护理中的音频装置和传感器组合,该组合具有和不具有用于使用口运动反应来刺激并改善婴儿、未足月婴儿和/或/早产婴儿的语音辨别的系统。
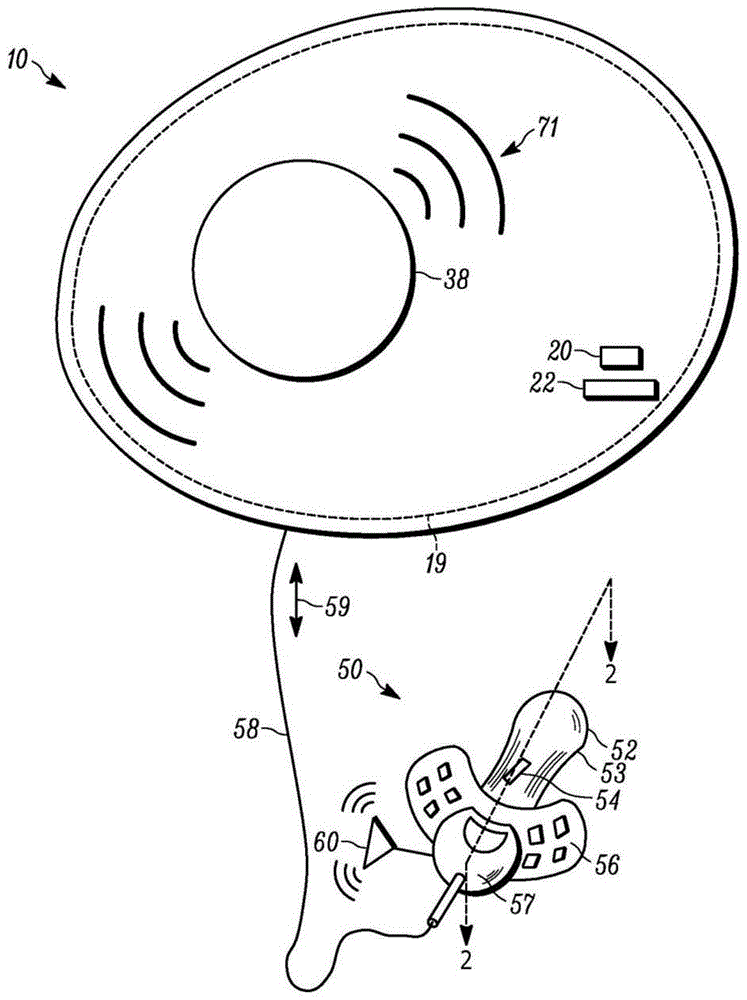
在图1中,包括矩形并收容电子部件19(包括扬声器38)的婴儿、儿童或成人启动的音频播放器或音频装置10连接到口运动装置或奶嘴50。口运动装置50和音频装置10用于通过以下方式来促进未足月婴儿的主动学习:使用来自音频装置的音频输出(例如,父母的语音、母亲的话音、女性的话音等)来教导未足月婴儿如何与口运动装置互动,同时使用口运动装置来教导婴儿如何识别语音(例如,创建学习反馈循环)。另外,音频装置10包括系统(参见图9),该系统将婴儿、儿童以及成人暴露于非母语,从而提高婴儿、儿童以及成人习惯于的非母语的语音辨别。
在一个示例实施方式中,音频装置10包括例如橡胶状或柔韧的聚合材料的外部材料,诸如聚丙烯等。设想用于音频装置的其他形状,诸如正方形、球形、椭圆形、超卵形以及超椭圆形。在一个示例实施方式中,音频装置10具有大约十英寸(10”)的整体最大直径、高度和/或宽度。如图5例示,音频装置10包括用于接近电子部件19的多个隔开孔口20、22。
在图5所例示的示例实施方式中,第一孔口20包括usb输入20a,并且第二孔口22包括用于电部件19的充电输入22a。在另一个示例实施方式中,音频装置10包括单个孔口,并且单个孔口包括充电端口和usb端口这两者。在又一个示例实施方式中,音频装置10没有孔口。音频装置10包括至少一个短距离无线互连信号收发器62,其中,音频输入经由短距离无线收发器来输入。
口运动装置50与音频装置10有线58通信和/或经由收发器60与音频装置无线通信。口运动装置50包括奶嘴部52、传感器壳体53、传感器54、防护部56以及抓握部57。在示例实施方式中,诸如当口运动装置50是无线的时候,口运动装置包括电源64(例如,诸如锂离子电池)。传感器54连接到电源64(例如,参见图5)和/或音频装置10内的电源(例如,电池30,如图5例示)。进一步地,传感器54经由电线58或收发器60与音频装置10通信和/或供电。在一个示例实施方式中,抓握部57和/或防护部56包括收发器60。在另一个示例实施方式中,抓握部57和/或防护部56连接到电线58。
奶嘴部52是可变形且中空的。奶嘴部52包括乳胶(例如,天然乳胶橡胶、非硫化橡胶等)、聚合物(例如,诸如合成聚合物,例如硅橡胶)、硬塑料等中的一种或多种。防护部56包括刚性塑料、金属等。在一个示例实施方式中,奶嘴部52和防护部56包括相同的材料和/或一体式设计,这形成传感器壳体53。防护部56包括开口,使得在口运动装置50被吞咽的情况下,婴儿的呼吸不受阻。在一个实施方式中,抓握部57包括环(未示出)。
设想多种类型的传感器54来检测婴儿或未足月婴儿何时在口运动装置50上相互作用(例如,吮吸)。如图2的所例示示例实施方式所示,空气流量传感器54a被包括在口运动装置50内。当婴儿通过沿着箭头53a、53b施加压力以压缩奶嘴部52而相互作用时,奶嘴部变形,使得空气从奶嘴部内的内部空间排出。空气流量传感器54a测量从奶嘴部52排出的空气量和/或空气速率。空气流量传感器54a将空气量和/或空气速度转换成输出信号59,该输出信号59指示婴儿正在施加到奶嘴部52的压力53a、53b。输出信号59被通信到音频装置10(例如,通过无线或有线信号58)。在一个实施方式中,口运动装置50的收发器60将输出信号59传输到音频装置10的收发器62(参见图5)。
在图3所例示的示例实施方式中,压力传感器54b位于奶嘴部52内。当婴儿与压力传感器54b相互作用时,该压力传感器测量施加到奶嘴部52的压力53a、53b的量。压力传感器54b将测得的压力转换为指示施加到奶嘴部52的压力53a、53b的输出信号59。输出信号59以与上面关于空气流量传感器54a描述的相同方式通信到音频装置10。
在图4a至图4b所例示的示例实施方式中,空气排出传感器54c位于奶嘴部52内。图4a例示了在婴儿与奶嘴部相互作用之前具有第一内部体积的奶嘴部52。图4b例示了在婴儿与奶嘴部相互作用之后具有第二内部体积的奶嘴部54a。空气排出传感器54c监测排出的空气量,使得奶嘴部52的总内部体积是已知的。例如,具有第二内部体积的奶嘴部54a将需要比从奶嘴部54a排出第一空气体积所需的更大的力来排出第一空气体积。
当婴儿与空气排出传感器54c相互作用时,空气排出传感器通过测量排出的空气量来测量施加到奶嘴部52的压力53a、53b的量。排出传感器54c将测得的压力转换为指示施加到奶嘴部52的压力53a、53b的输出信号59。排出传感器54c或音频装置10和/或安抚奶嘴50的智能元件确定由婴儿相互作用引起的内部体积变化,并且使排出的空气量与当前的内部体积相关,以确定婴儿施加到奶嘴部52的压力。输出信号59以与上面关于空气流量传感器54a描述的相同方式通信到音频装置10。
转到图5,例示了一个示例实施方式的音频装置10的电气部件19。在所例示的示例实施方式中,电子部件19包括:扬声器38,该扬声器被配置为发出音频;电气电路34,该电气电路将借助第一孔口20接收的音频信号和/或短距离无线互连信号转换成用于扬声器38的音频输入;微型计算机32,该微型计算机接收、比较、计算、分析和/或解释来自安抚奶嘴60的传感器信号并且与电路34通信;和/或电源,诸如电池30,该电池为电子部件中的至少一个供电。在另一个示例实施方式中,电子部件19包括光源(未示出),诸如指示音频装置10的一个或多个特征起作用的发光二极管。
在一个示例实施方式中,扬声器38可以包括小箱扬声器,合适小箱扬声器的一个示例包括由daytonaudiotm制造的daytonaudioce38m-8111/2”迷你扬声器8欧姆。微型计算机32包括微处理器,一个这种示例微处理器将是由sainsmarttm制造的sainsmartnanov.3.0。电气电路36包括由专用集成电路构成的印刷电路板(pcb),一个这种pcb将是具有产品编号gl9388的原型板。在示例实施方式中,微型计算机32包括mp3播放器36。mp3播放器36与电气部件19的其他元件(诸如电路34、扬声器38、和/或电池30)电气通信。
在一个示例实施方式中,mp3播放器36存储并播放音频,一个这种mp3播放器将是由diymalltm制造的diymall迷你mp3播放器。在该示例实施方式中,电池30向电气部件19供电超过十(10)小时的持续时间,一个这种电池30是锂离子电池。本领域普通技术人员将理解,在本申请中可以使用许多不同扬声器、微型计算机、电路、和/或电池类型。
在所例示的示例中,用于扬声器38的音频输入包括可借助第一孔口20接近的usb端口20a。usb端口20a与微型计算机32的输入/输出(i/o)端口有线通信44。用于电池30的充电输入22a分别与微型计算机32和电池30有线通信40、42。扬声器38与微型计算机32的i/o端口有线通信46。在示例实施方式中,扬声器38与mp3播放器36直接有线通信。
在示例实施方式中,一个或多个开关与微计算机32的一个或多个i/o端口有线通信。第一开关的致动打开或关闭音频,第二开关的致动使音频快进,并且第三开关的致动使音频倒带。本领域普通技术人员将理解,一个或多个开关可以响应于致动执行多个功能,诸如改变音频的间隔设置、音频的音量等。在另一个示例实施方式中,音频装置10的间隔设置可编程为控制发射音频每天的次数。另外,电池30使得音频装置10能够为不用电线的,这防止与电线关联的危险,诸如婴儿变得被不足月婴儿人工抚育器或婴儿床内部的电线致命地缠结或束紧。
在图5例示的示例实施方式中,电子部件19包括接口37,该接口与微型计算机32的i/o端口有线通信。接口37可以用于改变音频的持续时间、分贝等级、每天播放间隔、和/或一个或多个开关的其他指定功能。另外,接口37可以用于选择存储在mp3播放器和/或连接到usb端口20a的usb驱动器上的一个或多个音频选择。在另一个示例实施方式中,接口37被呈现在经由短距离互连信号与音频装置10通信的辅助装置39上。
音频装置10当与婴儿一起使用时,提供了开发大脑的益处。音频装置10经由语言系统21或某一其他程序编程为响应于从口运动装置50接收输出信号59而执行预定功能67,该输出信号指示已经向奶嘴部52施加了超过压力阈值69的压力。其中,压力阈值69基于年龄、成熟度和/或未足月或早产婴儿和/或足月婴儿或儿童成功施加的先前压力来确定。其中,年龄意指实足年龄和/或发育年龄。在一个示例实施方式中,预定功能67正在播放看护人的话音(例如,母亲的话音、亲属的话音、女性的话音等)的预先记录的适合年龄的音频记录71。音频记录71播放预定的时间量(例如,10秒)并停止,除非从口运动装置50接收到第二信号,该第二信号指示超过压力阈值69的感测压力已再次施加到奶嘴部52。
在另一个示例实施方式中,音频装置10的微型计算机32运行语言系统21,该语言系统21接受参数,这些参数包括输入,诸如婴儿的年龄、偏好的语言、歌曲持续时间对比阅读持续时间等。语言系统21经由微型计算机32与诸如辅助装置39的屏幕、附加屏幕、接口37等的输出屏幕电气通信。语言系统21经由微型计算机32的存储器存储各种语言的用于各种年龄的音频记录、用于使用语言算法的指令、与各种年龄关联的压力阈值69等。
在一个示例实施方式中,辅助装置39是远程计算机系统。该计算机系统包括台式电脑、膝上型电脑、平板电脑手持个人计算装置、ian、wan、www等,它们在任意数量的已知操作系统上运行,并且可经由万维网或因特网与诸如云、主操作计算机的远程数据储存器进行通信而可访问。在另一个示例实施方式中,微型计算机32包括功能特定的电路板,该电路板具有例如操作语言系统21的专用模拟电路(asic)。
在另一个示例实施方式中,微型计算机32包括处理器、数据储存器、计算机系统存储器,该计算机系统存储器包括可读访问存储器(“ram”)、只读存储器(“rom”)和/或输入/输出接口。微型计算机32通过处理器内部或外部的非暂态计算机可读介质执行指令,该计算机可读介质经由输入接口和/或电气通信(诸如来自辅助装置39或口运动装置50)与处理器通信。在又一个示例实施方式中,微型计算机32与因特网、诸如lan、wan和/或云的网络,诸如闪存驱动器的输入/输出装置,诸如智能电话或平板电脑的远程装置以及诸如接口37的显示器进行通信。
在一个示例实施方式中,语言系统21经由微型计算机32的存储器存储用于各种年龄的各种语言的音频记录71、用于使用语言算法的指令、与各种年龄关联的压力阈值69等。在另一个示例实施方式中,语言系统21检索远程(诸如在云上)或经由互联网存储的用于各种年龄的各种语言的音频记录、用于使用语言算法的指令、与各种年龄关联的压力阈值69。在该示例实施方式中,音频记录71包括朗诵婴儿定向语音(例如,“谁是饥饿的婴儿、你是饥饿的婴儿吗”)的看护人的记录,其中,婴儿定向语音包括针对婴儿、儿童和/或成人的语音。音频记录71包括主动阅读和/或歌唱,包括记录声音,该记录声音引起正在收听的人的参与。
在本公开的另一个示例实施方式中,音频记录包括使用外语(例如,西班牙语、法语、普通话、粤语、波斯语等)的预先记录的适合年龄的音频记录。外语音频记录71包括使用所选语言的婴儿定向语音的记录。外语音频记录71包括主动阅读和/或歌唱。发现暴露于使用给定外语的预先记录的适合年龄的音频记录的婴儿和/或儿童,在与音频装置10和语言系统21平均会话二十次之后,具有该语言方面的更大的语音辨别能力。在一个示例实施方式中,会话包括将婴儿、儿童和/或成人暴露于预先记录的适合年龄的外语音频记录。例如,暴露于预先记录的适合年龄的法语音频记录的婴儿、儿童和/或成人显示出辨别法语比未暴露于法语音频记录的婴儿在区分法语能力上有明显的统计学显著提高。进一步地,没有有害的结果,诸如婴儿或儿童以婴儿或儿童的母语更差的结果为代价提高外语的声音辨别。
所记录的语音是“婴儿定向的”,其专心地、语气上和/或情感上地针对婴儿(例如,如下面公开的公开文献中)。所建议和/或记录的语音也是针对婴儿的,并且考虑到预期读者的参与是“主动的”。另外,内容将满足表1(以下)中针对听觉内容的适合年龄的规范。
下面在表1中公开了基于婴儿年龄的英语和外语这两者预先记录适合年龄音频记录的音频输出参数:
表1
下面在表2中公开了基于婴儿年龄的压力阈值69参数:
表2
在图6中,例示了口运动婴儿启动的音频发射的示例方法600。在602处,存在于清醒婴儿的口腔中的口运动装置50发送指示婴儿与口运动装置的奶嘴部52相互作用的压力的信号。在604处,音频装置10接收来自口运动装置50的信号。在606处,响应于信号超过阈值69(例如,指示婴儿施加的压力超过压力阈值69),音频装置10将适合年龄的音频记录71播放预定的持续时间75。在一个示例实施方式中,基于未足月或早产婴儿的注意力跨度,确定预定持续时间75(例如,预定持续时间75不超过婴儿注意力跨度的持续时间)。在608处,响应于信号低于阈值69(例如,指示婴儿施加的压力低于压力阈值69),音频装置10不将适合年龄的音频记录71播放预定的持续时间75。在610处,重复步骤602-608,直到音频装置10已经将适合年龄的音频记录播放适合年龄的总持续时间77(例如,如基于婴儿的年龄和成熟度以及该年龄和/或成熟度的婴儿的已知注意力跨度确定的总持续时间77)为止。
在图7中,例示了口运动婴儿启动的音频发射的第二示例方法700。在702处,存在于清醒婴儿的口腔中的口运动装置50发送指示婴儿与奶嘴部52相互作用的感测压力超过成熟度和/或适合年龄的预定阈值69的信号。在704处,音频装置10接收来自口运动装置50的信号。在706处,音频装置10将适合年龄的音频记录播放预定持续时间75。在708处,音频装置10基于未足月/早产婴儿先前测量的对奶嘴部52的压力施加来提高阈值69。例如,如果婴儿吮吸超过阈值695mmhg,那么阈值69将升高至该压力或略低于该压力。在该示例实施方式中,以5mmhg的增量包括一个或多个阈值69。由此,口运动装置50促进婴儿的更佳吮吸行为,并且更好地吸引婴儿的注意力,因为婴儿不得不逐渐增加他们的努力来接收看护人的话音。在710处,重复步骤702-708,直到音频装置10已经将适合年龄的音频记录播放适合年龄的总持续时间(例如,如基于婴儿的年龄和成熟度以及该年龄和/或成熟度的婴儿的已知注意力跨度确定的总持续时间)为止。在一个示例实施方式中,看护人的话音用于使婴儿或儿童舒适或安心(诸如当婴儿或儿童在托儿所处、在病房中或以其他方式与他们的看护人分开时)和/或帮助安抚婴儿或儿童睡觉。在另一个示例实施方式中,看护人的话音用于帮助使婴儿或儿童脱离麻木(例如,在没有口运动装置50的情况下)。在又一个示例实施方式中,看护人的话音用于通过具有包括适合年龄的信息的看护人记录音频来教育婴儿或儿童。
在图8中,例示了口运动婴儿启动的音频发射的第三示例方法800。在802处,存在于清醒婴儿的口腔中的口运动装置50发送指示婴儿与奶嘴部52相互作用的感测压力低于成熟度和/或适合年龄的预定阈值69的信号。在604处,音频装置10接收来自口运动装置50的信号59。在706处,音频装置10基于未足月/早产婴儿先前测量的对奶嘴部52的压力施加来降低阈值69。例如,如果婴儿吮吸低于阈值695mmhg,那么阈值69将降低至该压力或略低于该压力。通过在需要时降低阈值69,可以逐渐地教导婴儿增加他们与奶嘴部52相互作用的压力,以学习如何更佳地吮吸奶嘴部52。通常重复步骤706,直到音频装置10已经被信号通知基于婴儿与奶嘴部52的相互作用来播放适合年龄的音频记录。一旦音频装置10已经被成功信号通知放置适合年龄的音频记录71,则音频装置通常将遵循方法700的步骤702-710。方法700和800生成反馈循环,该反馈循环将创建定制的婴儿规程来教导婴儿更佳的吮吸习惯。将存储各个婴儿的吮吸习惯并在随后的与口运动装置50的会话中应用。
在图9中,例示了示例系统方法900。在902处,用户(例如,父母、看护人等)为特定儿童创建账户99。在904处,用户录入关于特定儿童的数据,包括但不限于儿童的姓名、月龄、语言偏好、母语和/或歌曲与阅读比。在906处,响应于特定儿童的年龄为小于等于6个月,语言系统21输出第一推荐。在该示例性实施方式中,第一推荐包括结合音频装置10使用口运动装置50。在908处,语言系统21基于特定儿童的年龄来为传感器54分配吮吸阈值69和暂停持续时间(参见表2)。在912处,语言系统21指示接口37为用户呈现选项,以选择默认设置、非母语和/或非1:1的歌曲与阅读比。在一些示例实施方式中,当在904处录入关于儿童的数据时,用户选择默认设置、非母语和/或非1:1的歌曲阅读比中的至少一项。在914处,用户选择默认设置(例如,母语和/或1:1歌曲阅读比)。在916处,语言系统21将默认语言分配为母语,并且将默认比分配为1:1。在918处,响应于用户和/或其他人具有用于儿童的预先记录的音频记录,在920处,语言系统21生成年龄的专用指令,并且经由接口37向用户显示所述指令(例如,将口运动装置50放置在儿童口腔中)。在922处,响应于语言系统21确定已经遵循年龄专用指令,在924处,音频装置10播放程序71,该程序与用户的选择和儿童的年龄(例如,默认设置)相关。
在一些实施方式中,新用户、想要改变其合适年龄的音频记录71的用户和/或其儿童已经成熟新参数的用户记录新的音频记录。在934处,语言系统21提示用户记录音频记录。在一个示例实施方式中,用户熟悉如何记录音频记录71以及什么是适当的主题(参见表1)。在936处,响应于用户选择提供示例选项,语言系统21生成适合年龄且婴儿专用的针对婴儿的语音示例(例如,包括儿童的姓名)。在该示例实施方式中,用户遵循指令,包括参与主动阅读的指令。在一个示例实施方式中,指令包括用于可记录主题的1-20条指令。在938处,用户朗诵示例,并且语言系统21存储用户的音频记录(例如,存储在微型计算机32的存储部件中、在微型计算机32可访问的远程位置中等)。在940处,语言系统21生成用户音频记录的混合,以生成符合表1的适合年龄的音频记录。在920处,语言系统21生成年龄专用指令,并且经由接口37向用户显示所述指令(例如,将口运动装置50放置在儿童口腔中)。在922处,响应于语言系统21确定已经遵循了年龄专用指令,在924处,音频装置10播放包括用户的音频记录和/或混合的用户的音频记录的程序,该程序与用户的选择以及儿童的年龄相关(例如,播放的持续时间、歌曲与阅读比等)。
在910处,响应于儿童的年龄超过6个月,语言系统21输出第二推荐。在一个示例实施方式中,第二推荐包括利用手持传感器而不是口运动装置50。手持传感器的一个合适的示例是按比例放大的口运动装置50,其中,奶嘴52大至足以被婴儿挤压来提供变化的输出信号。在一个示例实施方式中,手持传感器包括具有交互传感器的球或玩具。交互传感器包括压力传感器、倾斜传感器或加速器中的至少一个。在另一个示例实施方式中,手持传感器包括垫或包括交互传感器的其他装置。在示例实施方式中,手持传感器是更大的儿童和/或成人使用的变体。在另一个示例实施方式中,手持传感器和口运动装置50被统称为感测装置。在930处,用户选择非1:1的歌曲阅读比。
在926处,用户输入非母语选项。在928处,响应于用户输入非母语选项,语言系统21指示音频装置10(例如,经由微型计算机)播放如表1所确定的适合年龄的非母语歌曲和/或阅读。在一个示例实施方式中,语言系统21向用户提供适合年龄的非母语歌曲和/或阅读,该歌曲或阅读包括针对婴儿的语音、主动阅读和/或来自本国非母语发言者的歌唱。在920处,语言系统21生成年龄专用指令,并且经由接口37向用户显示所述指令(例如,将口运动装置50放置在儿童口腔中,将手持传感器放置到儿童或成人的手中或所能及的范围)。在922处,响应于语言系统21确定已经遵循年龄专用指令,在924处,音频装置10播放针对婴儿的语音的程序71,该程序与用户的选择和儿童的年龄(例如,播放的持续时间、歌曲与阅读比等)相关。
在932处,响应于用户选择非1:1的歌曲阅读比并且用户还选择非母语,语言系统21基于用户输入的歌曲阅读比和语音选择,来经由微型控制器32指示音频装置10播放声音。响应于用户还选择非母语,语言系统21将进行到方法步骤920。响应于用户仅选择非1:1的歌曲阅读比,语言系统21进行到方法步骤934并如以上关于方法步骤934-940、920-924描述的进行。
音频装置10通过在父母无法与婴儿在一起时向婴儿呈现父母的话音来允许话音识别,同时通过响应于成功的吮吸来呈现父母的话音来促进婴儿的主动学习。已知针对婴儿的语音,以改善婴儿的语言发育,并且使用吮吸启动的定向语音和父母语音识别的组合的主动学习促进两岁未足月和/或早产婴儿的更佳言语效果。在许多医院处,父母探视不频繁且在小时间段内发生。音频装置10允许婴儿以安全且发育适当的方式接收他们父母的语音,同时教导婴儿如何吸吮和专注于语音。进一步地,因为音频装置10可以被编程为以预设分贝等级、在预设持续时间内且以预设间隔发射音频,所以可以避免不适当的(例如,太大、太长、太频繁的)声音暴露。不适当的声音暴露可能损伤婴儿的大脑发育。另外,在看护人或父母选择使用特定外语的预先记录的适合年龄的音频记录的情况下,婴儿或儿童在二十(20)次会话后,显示出辨别该特定语言的明显声音辨别能力,并且将准备好随着年龄增长而获取该特定语言的说话和理解这两者的语言技能,并且发展语言技能。
当语言的大脑可塑性最高时,在婴儿期期间发育出双语大脑益处。婴儿甚至从出生前就专攻他们大脑辨别不同语言的音素(语音)的能力。然而,随着婴儿年龄的增长,他们的大脑专攻婴儿期期间所暴露于的母语。通常,有跨多种语言利用的800种不同的语音,平均一种语言利用大约40-70种不同的语音。在英语的情况下,利用大约44种语音。通常,在单语家庭中养育的婴儿将丧失辨别未用于其母语中的语音的能力,因此,丧失在他们开始说话时产生这些相同语音的能力。当儿童在婴儿期期间例如通过音频装置10暴露于多种语言时,大脑发育出一种能力,该能力招募大脑的其他部分来处理语言,并且根据婴儿暴露于哪一种语言来抑制一组语音支持另一组(例如,利用执行功能,这与决策、注意力跨度和/或延缓晚年生活的痴呆症和阿尔茨海默氏病的发作关联)。暴露于多种语言的婴儿的大脑将更容易学习该婴儿所暴露于的特定非母语,而且具有学习非母语(例如,婴儿未暴露于的非母语)的整体优势。这在kovacs,a.m.和j.mehler.“cognitivegainsin7-month-oldbilingualinfants”proceedingsofthenationalacademyofsciences,第106卷,第16期,2009年,第6556-6560页,doi:10.1073/pnas.0811323106;kovacs,a.m.和j.mehler“cognitivegainsin7-month-oldbilingualinfants”proceedingsofthenationalacademyofsciences,第106卷,第16期,2009年,第6556-6560页,doi:10.1073/pnas.0811323106;kalashnikova,marina等人“infant-directedspeechfacilitatesseven-month-oldinfants'corticaltrackingofspeech”scientificreports,第8卷,第1期,2018年,doi:10.1038/s41598-018-32150-6;以及kalashnikova,marina等人“infant-directedspeechfacilitatesseven-month-oldinfants'corticaltrackingofspeech”scientificreports,第8卷,第1期,2018年,doi:10.1038/s41598-018-32150-6。
在前述规范中,已经描述了具体实施方式。然而,本领域普通技术人员理解,可以在不偏离如在以下权利要求中阐述的本公开的范围的情况下进行各种修改和变更。因此,规范和附图在例示性而不是以在限制性的意义上看待,并且所有这种修改旨在被包括在本示教的范围内。
益处、优点、问题的解决方案以及可以使得任意益处、优点或解决方案发生或变得更显著的任意元素不被解释为任何或所有权利要求的关键、所需或必要特征或元素。本公开仅由所附权利要求来定义,所附权利要求包括在本申请未决期间进行的任意修改以及如所发布的那些权利要求的所有等同物。
而且,在该文献中,诸如第一和第二、顶部和底部等的相关术语仅可以用于区分一个实体或动作与另一个实体或动作,而不是必须需要或暗示这种实体或动作之间的任何实际的这种关系或顺序。术语“包括”、“正包括”、“具有”、“正具有”、“由…组成”、“正由…组成”或其任意其他变体旨在覆盖非排他性的包括,使得包括、具有、包含元素列表的过程、方法、物品或设备不仅仅包括这些元素,而是可以包括未明确列出的或这种过程、方法、物品或设备所固有的其它元素。由“包括...一个”、“具有...一个”、“包含...一个”、“由一个…组成”进行的元素在没有更多约束的情况下不排除包括、具有、包含元素的过程、方法、物品或设备中的另外相同元素的存在。术语“一”和“一个”被定义为一个或多个,除非这里另外明确陈述。术语“大致”、“基本上”、“近似”、“大约”或其任意其他版本被定义为接近如本领域普通技术人员理解的。在一个非限制性实施方式中,这些术语被定义为在例如10%内,在另一个可能实施方式中为在5%内,在另一个可能实施方式中为在1%内,并且在另一个可能实施方式中为在0.5%内。如这里所用的术语“耦接”被定义为临时或非暂态二者之一地连接或接触,但不是必须为直接地,并且不是必须为机械地。以特定方式“配置”
的装置或结构至少以该方式来构造,但还可以以未被列出的方式构造。
到未指定用于前述实施方式中的任意一个或其组成部分的材料的程度,应理解,为了预期目的,本领域普通技术人员将知道合适的材料。
本公开的摘要被提供为允许读者快速确定技术公开的性质。本公开的摘要以以下理解来提交:它将不用于解释或限制权利要求的范围或意义。另外,在前述具体实施方式中,可以看到,为了使本公开流线型化,在各种实施方式中将各种特征分组在一起。本公开的该方法不被解释为反映要求保护的实施方式需要比如在各权利要求中明确叙述的更多特征的意图。相反,如以下权利要求反映的,本发明的主题在于少于单个所公开实施方式的所有特征。由此,在此将以下权利要求并入到具体实施方式中,各权利要求可以独立作为单独要求保护的主题。
- 还没有人留言评论。精彩留言会获得点赞!