健康护理分析流的管理的制作方法
本申请是于2013年7月3日提交的名称为“健康护理分析流的管理”的中国专利申请201380038252.7的分案申请。
此申请获得了美国临时申请,申请号为61/668941,申请日为2012/07/06的申请优先权;美国临时申请,申请号为61/673943,申请日为2012/07/20的申请优先权;以及美国临时申请,申请号为61/842316,61/842323和61/842325,申请日为2013/07/02的申请优先权。这些和此中讨论的其它所有外部材料都互相合并成一整体被引用。
本发明涉及基因组分析技术。
背景技术:
随着基因组分析技术的提高,需要处理大量原始序列数据用于提供信息,以便快速的为一保健对象,病人,或健康护理提供者提供预检,诊断,并且其它的基于基因组的分析的能力并没有随之提高。研究者曾付出了一些努力以产生更有效的基因组分析,但所有这些努力都失败了,这些努力包括提供这种覆盖大量的与个体和种群相关的数据集的分析。
hytopoulos的国际申请,no.pct/us2002/014665讨论了一种装置和方法,用于在一数据网络中主从式环境下执行基因分析。然而,hytopoulos未能利用大规模或遍及大陆的光纤网络的优势,以并行地解析基因组信息片段,并用于分析。
sanborn的美国专利公开号为no.2012/0066001a1的专利讨论了一种方法,用于相对于一参考基因组序列,使用已知的子串位置,通过递增的序列串的同步,以获得基于子串的队列的不同基因序列对象。然而,sanborn看起来并没有讨论利用多个连接至一分析网络的分析节点,以并行地从多个病人中处理序列数据。
steward的国际申请,no.pct/us1999/020449讨论了一种方法,用于基因组的数据发现,这种发现过程如下:提供一基因数据库,从中至少选择10个基因,从所选的基因中加以了解,对多个基因重复这些步骤,重复这些步骤直到所有选择的基因基本上并行地被了解了。然而,steward看起来并没有讨论利用一分析网络和多个分析节点,以便对一保健对象,一病人,或健康护理提供者提供快速和有效的检测结果。
dyer的国际申请,no.pct/us2000/042469讨论了一计算机搜索工具及支持的数据库,以用于分析基因组。然而,dyer看起来并没有讨论从多个序列设备中获得序列数据,也没有利用连接至一分析网络的多个分析节点,以并行地从病人处处理序列数据。
这些和此中讨论的其它所有外部材料都互相引用合并成一整体。其中在一引用合并中,一定义或一术语的使用对此中提供的术语的定义是不一致或相反的,此中提供的术语的定义同引用术语的定义不同。
除非文中特意否认,此中提出的所有范围应当解释为包括它们的端点,并且两端未封闭的范围应当解释为包括商业上的实际价值。类似的,所有可能的值应当认为包括中间值,除非文中特意否认。
至今为止,从基因组分析中获取有用信息的能力已经被如下方式的受挫所阻碍:(1)快速的传送大基因数据至位于集中的数据中心的计算机,以用于处理和存储;(2)精确的评估所有在病人的癌症组织的dna中发现的不同;(3)在一异质的疾病,比如癌症中识别许多克隆体;(4)预测在细胞的信号通路上每个克隆体的不同的系统性影响。
因而,仍需要利用大规模的网络,以及遍及大陆的光纤网络,以提供基因组分析流的管理。
技术实现要素:
本发明的主旨是,提供一装置,系统和方法,可使人们使用一计算机/基于服务器的系统分析基因组数据,此类分析是通过贯穿一网络的分布式分析系统完成的。本发明包括一基因组分析系统,以通过使用一序列设备接口,一分析网络和多个通过分析网络连接的分析节点,并行地处理从许多病人处得来的基因组序列。这个序列设备接口可以设置成从许多序列设备,从图像识别程序或设备,和/或一或多个存储序列信息的数据库中,并行地获得序列数据,基因组分析系统的分析节点可包括引擎管理节点,网络交换机,高性能计算设备(hpcs),或基因组的流管理节点,以交换一些序列数据和基因组数据。基因组的流管理节点可以设置成基于流管理功能管理分析引擎。此分析网络和多个分析节点包括基因组分析引擎,和一或多个来源于之前的序列流量,参考序列中,需要的存储序列信息的数据库等。此分析引擎可以处理序列数据,以产生单个病人或病人的统计的基因组数据,并把数据同一来自病人种群的标准的基因组序列或统计样本进行比较。此分析引擎也可以处理序列数据图像识别程序或图像识别设备。此分析网络可以包含一光纤数据链路,一地理分布的光纤网络,或甚至一横跨大陆的网络。
基于基因组数据,处理或分析状态,警报或告警,序列设备指令,分析推荐规范,预检或诊断,或进一步分析的需求,基因组分析系统产生了通知。通知系统可以在分析网络中建立一路由,以允许将通知发送至一保健对象,一序列设备,一病人,一健康护理提供者,或者是其中的组合。分析引擎也可以在分析节点中建立处理路由,以便于每个节点可以进行不同的分析。处理路由(例如,一数据流路由,一分析路由,一通知路由等)可以设置成具有预期的诊断,优先级,紧急情况,序列注释,或其它种类的功能,以平衡网络负载。基因组分析系统可以包括一管理接口,以允许用户提供反馈和序列设备说明。
本发明也包括一添加在序列系统的扩展模块,以预分析原始数据,以产生一序列注释,并根据这些序列注释汇编和前移预分析的数据至一序列分析设备,比如一高性能计算设备。原始的序列数据可包括基因组序列数据,蛋白质组序列数据,rna和小型rna序列数据,以及后生的序列数据。序列注释可包括不同的处理参数,序列信息,或病人信息。扩展模块可设置成把预分析的序列数据打包成分析设备可接收的格式。扩展模块也可包括一许可证管理器,它管理者分析设备和控制模块间的通讯。扩展模块可进一步的包括一序列设备控制器,以便基于来自分析设备的指令,发送命令至序列设备。扩展模块也可包括一存储设备控制器,以便基于预分析的序列数据,发送命令中存储设备。扩展模块可以是一硬件模块,用于连接一遗留的序列设备。在其它的实施例中,序列设备或分析设备本身可以作为扩展模块。
本发明进一步包括一种方法,用于预处理原始数据,以提供至一先验知识库的接口,以及一预处理的引擎,以接收和预处理原始数据,并联合原始序列数据与序列注释,以产生预处理的序列数据,并转移预处理的序列数据至一序列基因组分析设备。预处理方法也可包括一步骤,以便基于一相对于或在染色体之内的位置,从一先验知识库中,粗略的使原始数据读数相对于一已知的基因组图排成一排;并与一已知的等位基因,标记,或突变;或其中的组合有关。此步骤产生一粗略的队列,可成为序列注释的一部分。序列注释也可包括已知的基因或疾病标记,管理代码,路由信息,病人信息,一人口统计,一地理坐标,一监管链,一疑似诊断,一分析优先次序,或一告警促发。预处理原始序列数据的方法可进一步包括分析设备的带内预处理,这基本上是同原始序列数据的接收同时发生的。
本发明也额外的包括一交互式序列分析系统,其中一或多个序列设备适配器连接了一或多个分析引擎,以至少同一分析引擎和目标序列设备双向交换数据。序列数据可被预处理。序列设备适配器可包含多个适配器,其中每个适配器瞄准了一不同类型的序列机,以便于一混合的程序装置可以和一单个,普通的核心分析引擎工作。分析引擎可包括一分布式的分析引擎,具有多个分析节点,其中节点自身可以在地理上广泛分布。分析引擎通过网络,或通过光纤网络,依靠排序设备适配器,提交排序指令至目标排序设备。基于病人或疾病信息,序列指令包括送至目标排序设备和分析引擎的指令或命令,以重复,开始或停止排序;删除,发送或转移数据;区分或安排排序指令,或给出许可证管理指令。
本发明包括一基因组存储设备,带有一分布式基因组数据库和一基因组搜索引擎。基因组数据库可存储基因组数据记录,数据记录同病人的种群相关,并可以被许多种独特的,人口统计的,或医学的标识所索引。基因组数据可包括基于时间,人口统计,标准化序列,基病,或外部因素,在病人序列和参考序列间的不同点。基因组数据库可存储与存储器中,存储器分布在网络或光纤网络中的基因组分析节点,例如高速计算机设备。基因组搜索引擎可从数据库中返回记录,以响应一自然语言或机器问询。
本发明不同的对象,功能,范围和优点将会由下列的优选的实施例的描述而变得显而易见,并连同带有数字以表明部件的附图一同显示。
附图说明
图1是nationallambdarailtm的示意图,可以作为基因组分析系统的主干网;
图2是基因组分析引擎的示意图,能够通过一或多个排序设备与之相连;
图3是一扩展模块的示意图,能够配置一排序设备,以与一基因组分析设备互相联系;
图4是一种用于预分析基因组序列数据方法的示意图;
图5是一交互式排序系统的示意图,其中一分析设备可向一排序设备提供排序指令;
图6是一基因组存储设备的示意图;
图7是一健康护理分析流管理生态系统的示意图。
具体实施方式
应当注意,当以下内容描述了一基于基因组分析系统的计算机/服务器时,不同的配置也被视为合适的,并可以使用不同的计算设备,包括服务器,接口,系统,数据库,代理点,对端,引擎,模块,控制器,或其它类型的独立运行或集中运行的计算设备。计算设备包括至少一处理器,可能为多核处理器,用于执行存储在一有形的,永久的计算机可读存储媒介(例如,硬盘,固态硬盘,ram,闪存,rom,存储器,分布式存储器等)上的软件指令。优选的,软件指令配置或程序化计算设备,以提供下述公开的装置相关的作用,职责或其它功能。在特别优选的实施例中,不同的服务器,系统,数据库,或接口,使用标准协议或算法,协议或算法可能基于http,https,aes,公有-私有密匙交换,网络服务api,已知的金融业务协议,或其它的电子信息交换方法,以交换数据。优选的,数据交换在一包交换网络,internet,lan,wan,vpn,或其它类型的包交换网络中进行。
公开的技术提供了许多有利的技术效果,包括产生一或多个信号,用于配置基因组分析设备,以参与一基因组分析。信号可以根据从一基因序列中获得的信息产生。进一步的,信号可以代表配置参数,可能包括参数影响分析,路由,存储,通知,许可证管理,管理,告警,目录,日志,报告,安全,元数据,仪表盘,分析数据流,或其它的基因组分析。
下述讨论提供了本发明的许多实施例。虽然每个实施例代表了发明元素的结合,本发明被认为包括了所有公开元素的可能结合。因而如果一实施例包含元素a,b和c,而另一实施例包含元素b和d,那么本发明也被认为包含了剩余其它的a,b,c和d的结合,即使没有明确的公开。
由于在描述中使用的和贯穿权利要求中使用的下列术语,“一”,“一”和“所述”的含义包括复数的引用,除非文中清楚的另有所指。并且,由于在描述中使用的下列术语,“之内”的含义包括“在内部”和“在上面”,除非文中清楚的另有所指。
本发明另一元素或实施例的分组并没有被理解为受限的。每个组成员可以被单个的,或与其它组成员一起,或由其它发现的元素来解释和声明。一或多个的组成员可以由于便利和/或专利性的原因从一组中加入或删除。当任何加入或删除发生时,说明书被认为是包含修改的组,因而充实到所有markush组的权利要求中去。
除非本文中另有所指,术语“连接”的意思是包括直接连接(其中两个元素互相连接,互相接触),以及间接连接(其中至少一附加元素位于两个元素之间)。因而,术语“连接”和“结合”意义相同。而且,术语“连接”和“结合”婉转的表达了“通信连接”的含义,其中网络设备可以通过网络互相通信,也许是通过一或多个中间设备。
概述
优选的,一基因组分析流管理系统包含一大规模的可扩展系统,用于预分析,注解,或分析原始序列数据以产生基因组数据的分析结果。预期的系统有助于基于基因组数据实时的把可用的即时信息提供给健康护理提供者,病人,科学家,或其它用户。当现有技术花费几天,几星期或几个月排序大约30亿碱基对的人类基因组,并安置20000至25000个基因时,此基因组分析系统可在几分钟或几小时内完成相应的目标。系统通过预注解原始基因数据,解析注解的基因数据包值多个分析节点,在大规模的,遍及大陆的分析网络上并行运行这些分析,来完成这个目标,并可能通过发送/接收通知至一保健对象,一病人,健康护理提供者,科学家或研究员,或其他用户。此系统的有效和快速是基于运行于多个分析节点的,通过一高流通量的网络,进行并行分析而得到的。基因组数据结果可以非常及时的提供关于序列数据的预测,诊断,或其它分析。
基因组分析流管理系统也管理整个网络的数据流。管理系统可以建立处理路由,基于流量或分析的负载调整路由,管理分析引擎,启动或改变分析,请求额外分析以获得一更高可信度的序列数据结果,或请求其它行动以有效的管理输入,处理,分析或输出。
基因组数据可以是大规模的基因数据(例如,静态基因组信息,包括关于倍性/染色体组形,杂合性,等位基因频率等,以及动态基因组信息,包括在静态信息,进化的分析数据中改变的时间进程等),更高解析度的数据(例如,用于叠连群的基因组dna和cdan数据,装配的叠连群,染色体,基因和/或疾病相关的序列信息,部分或全部的转录组数据,不同类型的rna数据,包括hnrna,mrna,snrna,sirna,剪接变体等),以及核酸组或核酸群的信息(例如,密码子选择,不寻常的核酸碱基,特别用于rna)。而且,应当了解基因组数据也可包含上下文信息,优选的特别上下文信息包括涉及序列从属或参与的调控通路的数据,其中调控通路可处于复制的,凋亡的,转录的,翻译的,或后翻译的水平。因而,应当注意信息也可以与核酸序列编码的蛋白质产品的活动或功能相关/相联,和/或可以与蛋白质组数据相关。在进一步的预期的发展中,基因组数据也可以包含或涉及疾病相关的信息(例如,序列和/或管理数据同病原体或病理生理学相关)。
分布式的分析系统网络可以是基于基因组分析系统或任何计算设备配置的计算机/服务器,包括服务器,接口,系统,数据库,代理点,对端,引擎,模块,控制器,或其它类型的独立运行或集中运行的计算设备。分析系统可以有多个分析节点,其中那些节点可以在地理上分布。一分布式网络系统的例子是它可以适用于公开的分布式基因组分析流管理系统,包括nationallambdarailtm(nlr)。
节点可以贯穿整个国家分布,包括大学或联邦实验室,以及可能的国际设施以进行分析。nlr具有相关十三个成员的区域网络:cenic,floridalambdarail,frontrangegigapop/universitycorporationforatmosphericresearch,lonestareducationandresearchnetwork,mid-atlanticterascalepartnership:matp/virginiatechfoundation,northcarolinalightrail,oakridgenationallaboratory,oklahomastateregentsforhighereducation,pacificnorthwestgigapop,pittsburghsupercomputingcenter/universityofpittsburgh,southeasternuniversitiesresearchassociation,southernlightrail,universityofnewmexico(代表stateofnewmexico)。
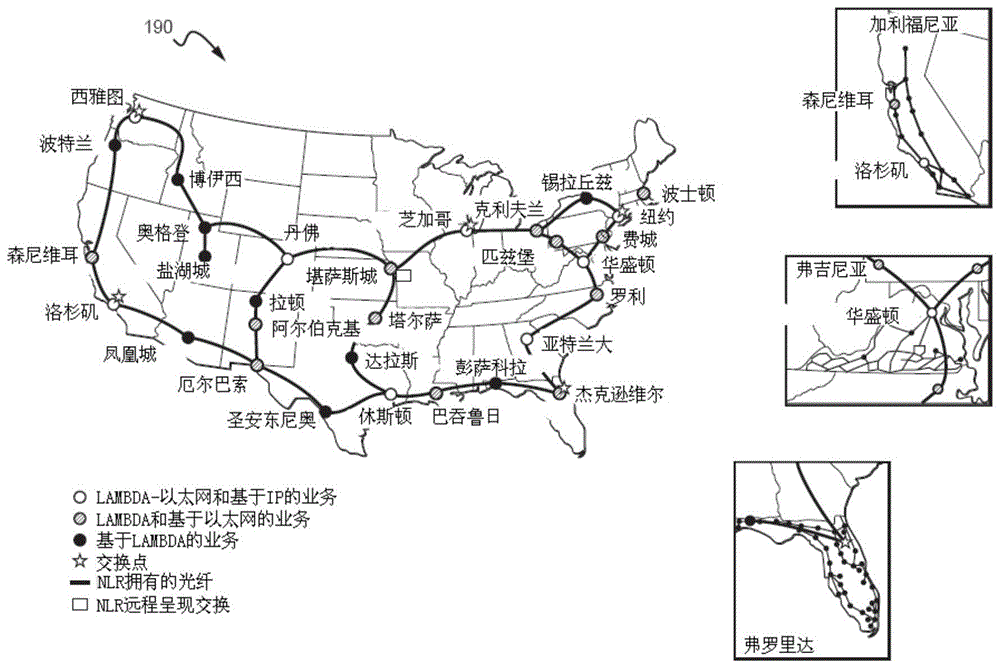
图1中,显示了申请人可进入的nationallambdarailtm(nlr)190。
nlr190是遍布全国的,先进的光纤网络基础设施,可以作为主干网用于预期的分布式分析系统。nlr190是一高速的,光纤网络基础设施,覆盖了12000英里,遍布了美国的21个洲。nlr190在使用上并没有强加任何限制,比如进行商业传输,提供用户以完全的灵活性和控制力。nlr190具有全部的1600gbps容量,以完成了40g的部分,并计划在进行中(自2012起)的100g的部分,nlr190是尖端的网络平台,可广泛的用于先进的研究项目和公私合营的项目。超过280个参与的大学和联邦实验室使用了nlr190。nlr190是第一横贯大陆的,具有10-gbit容量的以太网。nlr190具有5个国际交换点,并通过合作伙伴依靠globallambdaintegratedfacility与全世界网络相连。
基因组分析流管理系统
图2显示了一基因组分析系统200的概略图。
分析引擎240可以分布于多个节点(例如节点230,231,232,233,234和235是用于说明的节点,但实际并不仅限于图2中显示的节点),并通过网络互相连接,比如nlr290,一光纤网络,一集成或独立的广域网,城域网,企业专用网络,虚拟专用网络,内联网,无线网络,或其它网络。
节点230,231,232,233,234和235可包括计算机,客户端,服务器,对端,或优选的包括高性能计算设备(hpcs)。节点也可包括网络基础设施本身,交换机(例如
节点230,231,232,233,234和235通常为基因分析节点,通常目的节点为基因组分析设置或编译,节点专用于一特别的基因组分析作用或职责,比如路由,处理,排序,转移,数据清理,映射,或其它功能。无论一特别的节点的作用或职责如何,在某些实施例中这些作用或职责可以从一些丢失的节点中把功能迁移至另一节点。
节点230,231,232,233,234和235可包括分析管理节点230,节点230掌握着一特别的分析过程,例如dna和rna序列分析,基因表达谱,排列分析,基因组比较分析,模式搜索,dna主题分析,dna启动分析,dna和/或rna二级和三级结构分析,dna复制数变异,dna甲基化,微小rna分析,mrna表达谱,剪接变体分析,蛋白质序列(以及在某些情况下的结构)分析,或其它基因组分析工具和方法(例如,系统树装配,进化距离计算,突变率的测定等)。
节点的一可接受的形式可包括一或多个建模引擎,并如共有的美国临时专利所述,此引擎运行于图形处理单元(gpus)上。此专利的专利号为61/673943,申请日为2012/07/20中,并且它与涉及的专利合并成一体,并且具有优先权。
节点230,231,232,233,234和235可包括分析设备管理功能,并掌管了系统的部分功能或基因组分析系统的全部功能。可以有一管理节点230,作为系统的一接口运行,并具有自动的或用户生成的仪表盘,以监视或管理基因组数据流,或基因组分析流。管理节点230可用于在数据上创建注释或标记,创建处理指令,标准化数据或分析,管理存储器,或其它功能。管理节点230可定义常量,命名规范,属性,浏览方法,操作方法,使用方法,数据和分析质量控制参数,和其它功能。管理节点230可提供一接口,通过它用户(例如,一系统管理员,管理员,终端用户等)可用于提出功能和分析请求。管理节点230可通过一api,一客户端计算机或服务器,笔记本电脑,平板电脑,移动设备,浏览器,或其它接口进行配置或编译。管理节点230可用于添加,重复,改变,或取消分析;确定或设置序列数据的属性;合并或排列在基因组数据库储藏室内的序列数据;以另一路线分析;或其它功能。
节点230,231,232,233,234和235可根据要求,独自运行或合并运行。节点230,231,232,233,234和235可串行的,并行地,反复的,或其中一些方法的组合运行。当一病人需要特别分析或紧急处理时,或数据的特别分析需要大量的处理时间/资源时,这种方式是有利的。
分析引擎240由节点230,231,232,233,234或235,以及网络290组成。分析引擎240可能运行于管理节点230的支配之下。分析引擎240从排序设备210,211,或212(排序设备210,211,或212是用于说明的设备,但实际并不仅限于图2中显示的设备)中获得基因数据。排序设备210,211,或212可用于配置或编译同分析引擎240的通信(例如,引擎240作为一整体,个体节点230-235,通过管理节点230等)。排序设备210,211,或212可通过排序设备接口220,221,或222或其它因特网,网络,或通信协议和接口,与分析引擎240进行通信。接口的实例可以是一或多个协议,可能包括的协议如下:transmissioncontrolprotocol(tcp),hypertexttransferprotocol(http),commoninternetfilesystem(cifs),networkfilesystem(nfs),filetransferprotocol(ftp),securefiletransferprotocol(sftp),hypertexttransferprotocolsecure(https),networkaddresstranslation(nat),securecopyprotocol(scp),或其它已知的或未实现的协议。例如,排序设备210至212可以配置成在一或多个防火墙后运行。在相应的提供者办公室配置时,排序设备210至212可通过防火墙发送一http请求至一或多个设备接口220至222,设备接口220至222可被配置为一http服务器。在请求接收时,设备接口220至222可建立一与相应的序列设备的连接(例如,一tcp/ip会话,ssl会话等),并可能穿过防火墙,通过一nat连接。排序设备210至212随后可以通过接口220至222,发送它们的基因组数据至节点230至235,基因组数据可作为一原始数据流,作为通过ftp传送的文件,作为一xml流,或其它格式。
例如,一分析流管理的初始实验利用了一专有的基于udp的主从式架构,它被称为“输送者”,其中数据流使用aes-128编码加密。初始的实验包括20个输送者客户端的实例,每个运行于sunnyvale市,加州,每个都具有双线程,最大传输单元为9000,每线程的传输速率限制为240mb/sec。所有的输送者客户端的实例同时连接三个运行的输送者服务器的实例,服务器位于phoenix市,亚利桑那州。所有的传送和处理的统计数据都使用zabbix监视包收集。由phoenix的防火墙测量,传输速度的中间值为8.232gb/sec,其中最高的1%达到了高于9.55.gb/sec的尖峰值。这个总体的传输速度代表了每17.4秒一外显子组的吞吐量。在实验设置中,流对象代表了数据流从一端流向另一端(例如,线程和输送者的实例),以用于每个病人,以及数据的分析和传送。此外,流对象也可认为是代表了收集或监视的统计数据。
排序设备210,211,或212通常位于远端设备或健康护理提供者250,251,或252,例如位于一照料点,购物中心,医生的诊所,药房,研究或临床实验室,或其它场所。排序设备210,211,或212决定了生物标本中的核苷酸的顺序。遗留的排序设备缺乏与预期的分析系统200连接的能力,却可以通过排序设备接口220,221或222与分析引擎240相连。排序设备接口可被构建成零件市场模块配置,或使排序设备适合于连接分析引擎240。一基因组设备接口的实际技术可包括由digiinternational,inc.(参考urlwww.digi.com;digiconnectme,digiconnectwi-me,portserver等)或lantronixinc.(参考urlwww.lantronix.com;
排序设备210,211,或212可位于一照料点,购物中心,医生的诊所,药房,实验室,或其它提供者的位置250,251,或252。当排序设备210,211,212变得更流行和价格划算时,它们可以布置在任何地点。排序设备210,211,或212可以接入移动手持设备,可被美国运输安全局使用的安全设备,便携设备,实验室,笔记本电脑,或其它设备。排序设备210,211,或212可发送至紧急区域,那些区域紧急需要确定突然爆发的疾病的特性,这些疾病由疾病控制盒预防中心(cdc)或类似的公共健康机构所识别,以追踪在发展中国家或发达国家中出现的传染病,或解决在恐怖分子,战时或冲突情况下的生物威胁。
自身的网络290或提供者250,251,或252可以具有一报表服务器(例如,microsoftreportingservicesreportserver)或其它的报表引擎(未在图2中指出),以提供报表模板,用户定义的报表,基因组绘图工具,视觉输出,或其它信息。可以由报表生成器,报表设计器,或其它方式以产生报表。
排序设备210,211,或212可作为“转接器”运行,以使之连接至“云”,“云”由分析引擎240表示。如果排序设备是遗留设备(为显示),缺乏必要的通信能力,被动的,或连接的设备没有其它设备的能力,排序设备接口220,221,或222可以是排序设备的局部设备。一简单排序设备接口220,221,或222可连接一或多个其它设备以根据分析需求交换数据。设备接口220,221,或222可以根据制造商,型号,附属机构,医疗组,或其它类别进行管理。因而,管理节点230可以与排序设备通信,以确保每个设备根据需要的分析在生态系统内进行正确的运转或参与合作。
优选的,整个的系统200被构造成以并行地方式运转。基因组分析系统200可同时支持上百个,上千个的进程,或更多的排序设备,并且系统200可同时分析上百个,上千个,或更多的病人。系统200也可支持处理,或是种群的基因分析,或是样本的群体。
基因组分析系统200可以高速的并行处理许多病人。处理速度基于在一给定时间内,每单位时间有多少病人被处理,并可能处理完成。例如,基因组分析系统200可以以至少每天5个病人的速率,把序列数据处理成基因组数据。在典型的实施例中,基因组分析系统200可以以至少每天10个病人的速率,把序列数据处理成基因组数据。更优选的,每小时至少处理10个病人,而更优选的是,每天至少处理100个病人,或甚至更优选的,每小时至少处理100个病人。
分析引擎240处理基因组数据。分析引擎240可以为一独立的病人处理基因组数据,并且分析引擎240可以比较基因组数据从一病人处相对一种群资料组或具有相似人口统计或其它分组的样本的区别。申请人抛出术语“人类统计数据”以代表人类的统计学的或基础基因组的数据,用以比较病人的数据。人类统计数据可包括发现于公共基因组数据库中的数据,逐步演进的数据库,可用于连续的收集数据,私有的数据库,或一标准化的顺序。作为一种标准化基因组序列的功能,分析引擎240可以处理序列数据以产生基因组数据。标准化基因序列可以是一种统计学的编译,来自于病人的种群或亚群体特征或其它的数据源。基于标准化基因组序列,基因组数据可包括一热点,一加权的参考点,或一优先次序,以用于分析。基于标准化序列,分析引擎240也可产生一不同的序列或一粗略的队列。
分析引擎240可向排序设备210,211,或212提供反馈。分析引擎240可使用管理节点230作为一接口,以及被配置或被编译,以允许用户在排序设备210,211,或212之间提供反馈。用户可提供排序设备指令,比如重复排序请求,开始或停止排序请求,发送或接收数据请求,删除数据请求,管理许可请求,或其它指令请求。
一基因组分析流可认为是一数据流,它来自于依赖于分析仪器240的排序设备210,211,或212至一通知点,例如提供者250,251,或252。因而,一分析流可被认为是一明显的易管理对象,它可以被控制,被操纵或被管理。数据流对象可包括数据流属性,以描述数据流的特性。属性的例子包括一数据流识别器(例如,guid,uuid,名字等),一分析拓扑,原始信息点(例如,照料标识点,排序设备标识),通知信息点(例如,健康护理提供者标识等),病人信息,通知触发标准,账单编码,账单或发票信息,或其它涉及数据流的信息。管理节点230,或其它系统内的单元,利用数据流属性恰当的管理数据流的分析,路由,报表,告警或其它管理功能。数据流对象可进一步包括基因组数据,基因组数据实际上在分析的不同阶段被处理。数据流也被认为代表基因组数据的数据流。因而,数据流可以同时被批量处理或作为一全数据流从端到端管理。由于数据或结果被收集和发送至用户,基因组分析可同时进行。数据流可以是一易管理的对象,它由管理节点230管理。管理节点230可以通过管理至少一分析流对象(例如,一分析数据流,一应用于序列数据的分析路由等)管理分析引擎240,其中分析流对象是根据一或多个管理功能产生的,管理功能可能包括修改一分析路由,根据一数据流对象举例一分析流,基于分析流对象进行一件事物,对一分析告警,基于分析流对象构建一通知触发器,解构一分析流,或其它的管理功能,以管理分析流。
分析引擎240可认为是一动态系统,动态系统可根据基因组分析的需要改变它的处理,分析,或路由配置。管理节点230可由用户控制,或可被配置成在一分析运算中自动的管理和配置其它节点。这些配置的改变或指令管理着分析流,并且它们可包括流管理功能,例如产生一通知,以作为基因组数据,一处理状态,一分析引擎管理状态,一告警,一警报,一排序设备指令,一分析建议,一预测,一诊断,一中间节点通信,一获得更高可信度的请求,或其它通知的功能。管理节点也可产生一通知,用于在分析网络中配置一路由。管理节点不仅可以重路由数据流,也可以处理节点链条,以管理全部的分析流。
管理节点230提供一或多个工具,以管理分析节点230,231,232,233,234和235,分析流或分析引擎240。管理节点230可包括一仪表盘以管理整个系统,一仪表盘用于特别的组,一仪表盘提供给用户,一仪表盘用于信号分析,用户分析的多个仪表盘,一仪表盘用于设计报表和分析输出,一仪表盘用于输入和输出分析,一视觉仪表盘用于监视系统,或其它仪表盘。预期的仪表盘可呈现基因组分析流对象信息,其中的图像可指出有多少流对象的集合正在处理,并可能实时观看。进一步的,流对象可通过这个仪表盘控制,其方式有例示数据流,解构数据流,去激活数据流,使用数据流有效的监视系统,或应用其它控制。
分析系统200可被配置或被编译,以路由数据或分析数据流。依赖于序列数据所在的州,其它的基因组数据是如何路由的,分析系统的负载如何,分析引擎240可在分析节点230,231,232,233,234和235中建立处理路由。分析引擎240可建立处理路由,作为预期的诊断,预测,优先次序,紧迫性,序列注释,交通负载,分析负载,计算带宽,存储器限制,告警状态,分析状态,用户定义的输入,基因组分析类型,需要请求的分析迭代次数,置信级,或其它分析参数的功能。在这个实施例中,分析引擎240可呈现特定的配置,以适合于当前的分析。例如,优先的数据可被路由至一高容量的处理节点,而低紧迫性的数据可作为批量处理在一低容量的节点运行。必须考虑到如下场景,即病人属于一种特别的一群人,他们具有低概率的不良的基因突变。基于人口统计信息或基因组谱信息,依赖一高容量,高流通量拓扑,管理节点230可配置一或多个其它节点。高容量,高流通量拓扑在病人数据进入时进行相应的处理,并可能形成一或多个fifo缓冲的数据流。当导入一特别有趣的病人数据流时,可能由于一紧急情况,管理节点230分配一或多个节点,作为一专用拓扑以分析此紧急病人的数据。这些资源的获得可能影响高容量,高流通量的拓扑。然而,紧急病人的数据可以及时的处理以解决此突发情况。
分析引擎240可作为一付费服务运行,这需要用户注册,提交支付信息,或登录系统以获取进入基因组分析系统的能力。节点230,231,232,233,234和235中管理节点230可管理用户列表,许可要求,登录功能,支付系统,以及其它相关功能。由于基因组分析流对象依赖分析引擎240进行处理,一或多个管理节点230可以监视进行分析的资源或业务范围。基于计算的使用内容,管理节点230可为一或多个账户计费(例如,健康护理提供者账户,保险账户,病人账户等),以提供相应的服务。费用可以基于那些需要分析,紧急处理,优先次序,用于分析的算法,或其它基因组分析流对象属性的资源来计算。
基于图像识别,分析引擎240可进一步处理序列数据。基于图像识别,排序设备210,211,或212也可以处理序列数据。从连续时间编码放大显微镜检查(steam)或其它处理中得到的基因组输出或其它数据输出可被翻译成一dna碱基。在碱基呼叫步骤中,每个来自数据输出的图像可作为一用于特别的dna碱基的指示器运行。例如,图像可认为是一种条形码的形式,而被识别。进一步的,图像可以是分析流的一部分,用于通过它传输。
steam是一种高通量的成像方法。不像传统的图像传感器,如电子耦合器件(ccd)和互补金属氧化物半导体(cmos)设备,steam可以提供极度快速的快门速度,而无需高强度的照明。steam方法把一二维图像映射成一一维的放大的连续时域波形。steam首先把信息冲压在宽带光脉冲的频谱上,随后把频谱映射成时域的连续数据流。此方法即提供图像数据流和放大功能,也在高速度下捕获快速的物理现象。steam具有至少比传统的ccd快1000倍的帧速率,并高达每秒610万帧。此外,此方法提供27ps(皮秒)的快门速度。
作为一种高通量的成像方法,steam可以用于识别罕见的疾病细胞,癌细胞,或其它生物的或基因组的材料。在分析系统200中,这个细胞识别方法可以具有多种应用,包括癌症筛检和其它诊断测试。
可以进一步预测,分析系统200可以使用一种算法,比如尺度不变量特征变换(sift)或其它算法,以执行图像识别。sift是一种用于图像识别的纵所周知的算法,它使用一种本地图像特征向量,向量对于照明,图像鼻,缩放,翻译,视角,变换和旋转都是不变的。特征通过分期的过滤进行检测(例如,尺度空间极值检测,关键点定位,方位分配,关键点描述符的产生等),并且为它们创建了图像密匙。因而,从分析系统获得的图像可以被分析,以决定它们是否具有符合已知的对象的相应特征(例如sift特征等)。
例子中的技术可用于进行基因组分析,其中包括那些由five3genomics,llc提供的技术(参考urlfive3genomics.com),它们在美国专利申请2012/0066001中有所讨论,并在国际专利申请wo2013/086424,wo2013/086355,wo2013/062505,wo2013/052937,和wo2011/139345有所提及。额外的技术包括时间编码放大显微镜检查(steam),以及在sanborn等人的2012/0059670专利中讨论的技术。
通过扩展模块使用的基因组分析流管理系统
图3说明了本法明的另一技术,其中使用了一扩展模块370配置排序设备310。
扩展模块370可以是一后市设备,或者扩展模块370可以融入排序设备310自身。或者,扩展模块370可融入分析云300(例如,一网络服务,软件即服务(saas),基础设施即服务(iaas),平台即服务(paas)等),或其它配置。扩展模块370也可包含一应用程序包或在一或多个硬件平台上的基于云的应用程序执行。
扩展模块370可以以各种方法配置或并入,以促进设备,分析流,或分析系统300(例如,nlr390和hpc330,331,332,333,334,或335)之间的通信。根据许多传输格式,扩展模块370可以把预分析的序列数据打包,其中传输格式可由每个分析设备/节点330,331,332,333,334,或335定义。扩展模块370可以是一硬件模块,用来连接一遗留的序列设备310,序列设备310作为一序列设备运行,或用来连接已存排序设备中的序列设备310,或连接遗留的设备至其它设备。排序设备310自身可以作为扩展模块370运行。排序设备310也可包括存储媒体301,用于存储指令,其包括扩展模块370的功能。扩展模块370或它的功能可以整合到分析节点330,331,332,333,334,或335中,或者扩展模块370可以作为一软件适配器运行,软件适配器可以与一远端的可网络激活的定序器310通信。扩展模块370的其它配置,排序设备310,和其它设备,都是可期待的,无论是否为集成设备,嵌套设备,具有集成功能的设备,或隔离的设备或功能。
优选的,扩展模块370可进行预处理,以注释原始数据,用于进一步的分析。原始数据的排序注释协助了分析系统300解释数据是怎样进行分析的。排序注释可包含许多种的注释,例如分析节点的归属,数据的归属,原始输入数据,预分析和注释的序列,输出;分析和数据流的路径;和其它因素。序列注释可提供在原始数据和预先存在的或公共的基因组数据库之间的一粗略的队列,以获取一初步的诊断,预测,或其它分析结果。例如,序列注释可包括特定病人的数据,疾病或诊断相关的数据,识别基因组中推定的或真实序列位置的数据,等。因而,序列注释也可提供更广泛的初步分析,比如注释原始数据如何匹配一大型的分析,优先信息(例如,何种基因或热点应当首先被分析并在何处分析),紧急信息,或其它因素。例如,扩展模块370可从排序设备310处接收序列数据,并预分析此序列数据。预分析306可以在一xml文件流内打包序列数据,并包括注释,以指出在xml文件流中作为标签展示的不同规则,需要,或其它因素。
扩展模块370可以通过一或多个需要的有线或无线连接,与分析系统300,分析引擎240,排序设备310,或分析节点330,331,332,333,334,或335通信。扩展模块370可利用所有形式的有线或无线连接方式,连接分析引擎240和分析节点/设备330,331,332,333,334,或335,包括蜂窝网连接(例如,gsm,cdma等),wimax,wigig,wi-fi,wi-fidirect,或其它类型的无线基础设施。扩展模块370也可以使用所有形式的有线或无线连接方式,连接排序机310,例如ethernet,wifi,wigig,usb,w-usb,bluetooth或其它所有形式的连接。
扩展模块370可包含一些附件组件,以允许模块同分析设备300或排序设备310互相作用。可用的组件包括许可证管理器304,控制器303,存储器305,以及预分析器306。由于从排序设备310中获得了原始数据,预分析器306可预处理数据,以形成一或多个预分析的序列307。
控制器303连接排序设备310。或者,控制器303可通过一端口360连接排序设备310。控制器303提供一双向数据通路,通过它命令,指令,原始数据,注释,分析流,和其它信息可以在排序设备310,扩展模块370和分析系统300中交换。控制器303可进一步从分析系统300和分析设备/节点330,331,332,333,334,或335中接收命令,以控制排序设备310。
扩展模块370也可包括一预分析器306,预分析器306获取原始数据(例如,从排序设备310中直接接收的数据),并进行预分析以产生预分析序列307。基于序列或其它的排序设备310中的存储器301中的基因组数据,扩展模块305中的存储器,分布式分析网络300中的存储器,分析设备/节点330,331,332,333,334,或335,公共数据源,或其它数据源,预分析可以产生序列注释。扩展模块370产生预分析序列307,预分析序列307可包括沿着其它数据的序列注释,那些数据可从原始序列中获取,例如初步的基因标识(例如,通过名字或功能),基因组热点,基因组比较(例如,和参考序列,或优先测试),病人和种群比较,比较原始数据和排序的基因组数据得到的粗略的队列,其中基因组数据来自公共基因组数据库或其它数据库,以及其它数据。其它注释也可包括推定位置,疾病关联,相对多度信息,基因关联,核酸等级,监管链,原始组织或组织样本,病人信息,病人识别器,人口统计信息,地理信息,诊断信息,健康护理提供者信息,序列分析目的,账户信息,家族信息,病历,心理记录信息,种系,或其它信息。
扩展模块370允许了排序设备310与分析系统300和分析设备/节点330,331,332,333,334,或335的通信。扩展模块370转移预分析序列307至分析设备/节点330,331,332,333,334,或335,用于进一步的处理,并基于序列注释307进行转移。例如,扩展模块370可把日常或紧急的数据转移至疾病控制中心(cdc),研究中心,或其它的中心330,331,332,333,334,或335。
扩展模块370也可以产生序列注释307,序列注释307控制了在相同排序设备310内的数据的处理或其它分析设备/节点330,331,332,333,334,或335的数据处理。这些注释创建了处理参数,例如路由参数,优先级参数,紧急情况参数,服务等级参数,计费参数,支付参数,许可证控制参数,管理处理参数,或其它处理参数。
通过分析系统300,许可证管理器304允许模块370控制至分析设备或节点330,331,332,333,334,或335可操作的访问。许可证管理器304可包括一或多个密匙(例如,用户密匙)以及合并的不同信息或授权方法或鉴定,例如具有一用户标识,一些允许的使用,一许可证有效期,一用于服务类型或分析类型的许可水平,一用于许可的服务类型或分析类型的指示器,一分析账户,和一分析管理模块。
许可证管理器304可作为一权限管理实施模块运行。在某些实施例中,根据一许可证规则集,许可证管理器304可编译成指导分析引擎300,以决定排序设备310是否具有足够的权限或特权访问分析引擎300提供的服务。例如,排序设备310可以配置在一医生的诊室内。医生可支付会员费以接入基因组分析引擎300的一或多个服务。许可证管理器304可检验医生的会员账户,以判断医生是否具有良好的声誉,或判断医生可接入的服务水平。由于排序设备310提供数据至分析引擎300,许可证管理器304可正确的记录医生访问分析引擎300的账户费用。
许可证管理器305也可以监视或管理一或多个涉及排序设备310的基因组分析流对象的一账户。此账户可包括照料提供者的账户,病人的账户,保险账户或其它账户。由于序列数据通过排序设备310产生,许可证管理器304可把一流对象标识作为一注释附着在序列数据上,以允许分析引擎300进行正确的路由,或直接进行分析。
序列数据的基因组分析流的预处理
图4说明了一种方法400,用于预处理基因组数据,这些基因组数据可以与图3中的扩展模块370共同使用,其中图3中的扩展模块370可以作为一预处理引擎使用。
方法400始于步骤410,包括提供访问一预处理引擎的入口。例如,预处理引擎包括一或多个图3中描述的扩展模块370。步骤410也需要用户订购一服务或许可,解锁访问,安装软件,鉴别他们的接入,授权他们的接入,或利用其它形式的鉴定以接入预处理引擎。提供的接入可以覆盖一广泛的范围,包括出售预处理引擎,安装预处理引擎,合并预处理引擎至一遗留设备设计,或制造一可用的预处理引擎。
步骤420可提供一先验知识库的接入,知识库存储了已知的分析相关的信息。知识库可包括关于已知序列的分析相关的数据,或其它形式的分析数据。如图3所示,知识库可位于分析设备300,公共基因组数据库,实验室数据库,私有的数据库,用户定义或创建的数据库,或其它的知识库。为了进一步分析,预处理引擎使用此数据以正确的注释序列数据。如图3所示,知识库可位于扩展模块370的存储器305内,可位于远端位置的存储器内,可位于排序设备310的存储器301内,可以是一订购的数据库,或可以是任何种类或形式的存储器。
如图3所示,在步骤430中,预处理引擎接收了原始序列数据,通常直接从一排序设备310中接收。原始序列数据可来自于一存储器,缓冲器,数据库,或其它资源。原始序列数据可以为任何形式(例如,axt,bam,bambam,bed,maf,微阵列,sam,wig,xml,或其它格式)。原始序列数据可包含从一排序设备接收的数据,用于在完成分析前进行预处理。
预处理400的方法也可以包括步骤440,用于执行一原始数据的粗略队列,并对应于源自任何先验知识库的已知的基因组安置,以产生一序列注释。通过基于一相对于染色体的位置,相对于染色体内的位置,与一已知的等位基因关联,与一已知的标记关联,与一已知的突变关联,或与任何已知的图案关联,或与来自一先验知识库的排序关联,或与经验数据的收集关联,粗略的调整原始数据,原始数据的粗略的排列促进了基因组数据的处理和分析。
如图3所示,原始数据的预处理可并行地进行处理,这贯穿于分析系统300的始终。一部分已经预分析的数据流可以通过分析系统300转移,以用于分析,而更新的部分的数据流正在进行预处理。此并行处理可以基于定序器的输出实时进行。
步骤450可包括相关的具有原始序列的序列注释,以产生预处理的序列数据。此步骤包括预处理过程,以决定一些原始序列数据的内容水平。根据来自知识库的信息,相关的具有原始序列的序列注释可以基于一或多个政策或规则执行,以便于正确的注释原始序列数据。
序列注释可覆盖一广范围的信息。序列注释可包含在一基因组中的位置(例如,在特定的染色体或染色单体,染色体外等),一已知的疾病标记,一突变(例如,突变/转换/颠换点,插入,删除,易位等),一诊断代码,一程序代码,一账单代码,分析路由信息,统计信息,病人信息,一统计人口,一地理坐标,一监管链,或者其它方面。序列注释也可包含一提供给健康护理提供者的推荐,一治疗推荐,一用于预防性或根治性的治疗推荐,一疑似诊断,一预测,一分析优先级,一告警触发器,一告警通知,一用于未来分析的请求,一用于更高信任度的请求,一可能结果的列表,一志愿疗程的请求,一危险指示或一特殊条件的易染病体质,或其它信息。
步骤460可包括转移预处理序列数据至一序列分析设备,以用于进一步或更详细的分析。转移预处理序列的过程可包括把已注释的预处理序列数据传送至一分析设备330,331,332,333,334,或335,如图3所示。优选的,如图3所示,这些预处理的序列被推送至设备330,331,332,333,334,或335,但是预处理序列也可被设备330,331,332,333,334,或335拉回。预处理序列可通过合适的协议的传送,比如http,ftp,ssl,https,专有协议,xml或其它协议。
交互式基因组分析流管理系统
图5说明了本发明的另一例子,其中一分析设备500可以与一或多个序列设备交互(例如排序设备510或511)。设备500可通过一适配器571或适配器572接入或控制排序设备。如之前所述,图3中的扩展模块是一适配器的合适选择。虽然适配器571和适配器572分别配置在排序设备510和511的外部,仍预期适配器的作用和功能可以被整合或并入下一版本的排序设备510和511。
图5中的预期的分析系统包括一分析引擎(例如nlr590和hpc530,531,532,533,534,或535)和一适配器571或572。如之前讨论的那样,如图3所示,适配器571和572,或扩展模块300可作为一设备附着在排序设备510上,可整合在排序设备510或511内,成为排序排序设备511本身,或作为适配器572使用或运行,适配器572作为一分析云的部分,可能为云500,建造于nlr590和分析节点530,531,532,533,534,或535上。在其它的实施例中,适配器571和572可通过端口561或562与排序设备510或511通信。依赖于目标排序设备的不同,适配器571或572可采取不同的形式。
如图5所示,分析引擎500可通过分析系统产生部分的或完全的基因组序列的分析。
适配器571连接一排序设备510,并允许在设备510与分析设备530,531,532,533,534,或535之间的通信,或甚至在生态系统500内其它设备间的通信。适配器571可允许多重排序设备以一协同方式并行地运行。
适配器571或572也可允许设备提交命令或指令501至排序机510或511。在一些实施例中,通过排序设备510或511,适配器571或572从一“设备”格式转变指令501成一可理解的命令。
适配器571可坐落于邻近排序设备510处,或在适配器572远离排序设备511的情况下,远离排序设备510。虽然图5说明了每个排序设备510或511由一适配器571或572,系统仍可在每个排序设备中设置多个适配器,把每个适配器适用于多个排序设备,或使多个适配器交互多个排序设备。例如,当远端适配器572用于命令格式的转换时,一接近排序设备510的适配器571可包括一用于验证的许可证管理器。
适配器571或572可包括一或多个策略规则集,用于管理命令的提交和响应。在图5中,适配器571或572的规则集可管理时间问题,缓冲区,密匙,令牌,预分析指令,命令,先验知识库,以及基因组分析系统中的其它元素。
每个适配器等级适合于不同构造或模型的排序设备。此外,通过多个排序设备适配器,预期排序设备的异质的混合可以与一单个的公共核心分析引擎共同使用。多个排序设备适配器可适用于多个排序设备。例如,适配器571可根据一由分析引起500所了解的,公共的,标准化的协议格式进行运转。进一步的,适配器571可包含一或多个转换模块,以便把公共的,标准化的协议转换成一特定设备的协议,以供排序设备510使用。
例如,可以提交至排序设备510或511的指令包括指令501,以重复(例如,增加在基因组中特定或全部区域的排序深度),终止,或启动排序,或在不同的设备中协调相同病人样本的并行地排序。指令501也可以用于发送数据,删除数据,或优选排序顺序。指令501可指出应当转移或预定的排序数据。指令501也可包括许可证管理指令。进一步的,指令501可基于一些因素得到,这些因素包括病人数据;健康护理提供者;疾病信息;或其它因素。
分布式基因组存储设备
图6提供了分布式基因组存储设备600的图解说明。在一些实施例中,基因组记录存储与分析节点630,631,632,633,634,或635,它们与数据库680,681,682,683,684,或685或基因组分析系统600中的其它设备关联。其中有多个基因组数据库储存室,包含但并不仅限于美国国家生物技术信息中心(ncbi),欧洲分子生物学实验室-欧洲生物信息学研究所(embl-ebi),日本dna数据库(ddbj),国际核酸序列数据库合作所(insdc),ncbi参考序列(refseq),脊椎动物基因组注释数据库(vega),共同编码序列(ccds),或其它储存室。
存储于数据库680,681,682,683,684,或685中的记录可根据任何需要的格式存储。一记录可成为一完整的基因组;部分的基因组;涉及基因或区域的序列(例如,覆盖已知的snp,突变,或基因组中的其它改变,包括易位和复制);元数据(例如,科学的和/或中间的注释以用于特定序列);分析的结果;排序医生的评论;统计数字;或数据的其它部分。优选的,存储于680,681,682,683,684,或685中的记录涉及病人的种群,并根据人口统计学进行研究和分析。
存储于数据库680,681,682,683,684,或685中的记录可在基因组数据间存储不同的数据;在一病人和标准人类间存储不同的数据;在一病人和一种群间存储不同的数据。参考或人口统计学因素以一抽样时间,一组织,一人,一种性别,一家庭,一社区,一人口统计学,一标准化序列,一疾病,一食物,一环境,一年龄,和其它人口统计学因素为基础。更优选的,这些差异以bambam格式和/或以一系统树的格式表示。
优选的实施例包括一基因组搜索引擎630;它允许用户提交问询。搜索引擎630在记录数据库680,681,682,683,684,或685中寻找匹配的记录,并可以通过序列或其它因素进行索引,存储于记录索引680中。分布式基因组数据库600可基于许多标识符进行索引,例如一病人标识符,一种群标识符,一人口统计学,一疾病,一诊断,一性别,一年龄,一位置,一占有,一种风险因素,一序列,一种基因,一条通路,一等位基因,一预测,或其它识别器。
可采用多种方式,让一终端,例如一计算机650,通过网络690向记录索引640的搜索引擎630发出询问。它们可以是一自然语言的询问;一关键词搜索;一序列搜索;机器命令;api;或其它方式的询问数据。
分析数据流
迄今为止,本发明主要注重于基因组分析流管理。然而,已公开的横跨大陆的分析流管理系统可应用于除基因组分析之外更广泛的照料领域。通过有效的构建分析部署点的综合系统,此公开的技术跨越了已知的基因组分析,而这个系统在之前是不可能整合的。
图7显示了一总体的学习系统,它可以提供可变化的健康护理。在部署点中,分析流作为可管理的基于计算的对象,流过生态系统。例如,一数据的健康护理流可从知识域(例如,模型,人工智能等)的内容中装入分析数据。由于一个体的健康护理流被具体化和填充了原始数据(例如,基因组信息,生物统计学,保险计划数据,等),相应流对象可路由数据至一或多个恰当的分析身体,用于覆盖或嵌入相应的分析数据(例如,诊断,预测,推荐,晋升等)。
个体的数据流随后可以考虑为一装配的人形信号引擎,以表示个体,甚至个体的生命。因而,通过一发送域,流对象可路由流数据,在发送域中个体的流数据可提供至健康护理提供者,照料站,实验室,药店,救济院,或其它场所。在发送域中的每个成分也可以在个体的健康护理流中添加数据。
由于个体的健康护理流随着一特定主题(例如,一特定疾病状态)的发展,或随着它们的横跨一生的发展而变得成熟,流对象可以随后在支付域内路由数据至结果驱动的站。因而,公开的流管理引擎可直接发送相关数据至股东,股东主要负责流分析的最终处理。例如,流对象可发送至一雇主,一政府,一金融机构,一救济金管理员,或其它具有相关流数据的场所。
除了基因组学,公开的生态系统可处理其它类型的流数据。例如,公开的分析引擎也可以提交具有推测的蛋白质组(参考five3tmurlfive3genomics.com/technologies/paradigm)分析流,或提交实际的定量蛋白质组(参考oncoplexdxtmurlwww.oncoplexdx.com)。而且,这些数据可进一步的涉及或结合一或多个临床协议数据库(参考evititmurlwww.eviti.com),此数据库连接了无数的临床协议,用于许多不同的癌症类型,并进一步收集了数以千计的肿瘤学家治疗遭受不同疾病状态的病人的案例。相关的实际治疗和健康护理提供者的流分析节点(例如,paradigm,oncoplex等),提供了更广阔的视角,以作为一领先指标指出,对于个体的一生是照料的如何之好,而非在一疾病状态发生后再行照料。因而,一个体的健康护理分析流可以始于他们出生时,而可能在他们死亡后继续以同他们后裔绑定的方式存在。真实的体会是,公开的生态系统可认为是“生命护理”,或特别的对于癌症来说,是一基于流的“癌症护理”。
个人的生命可视为一从摇篮到坟墓的流对象,它引导了流数据从一分析节点至另一分析节点。公开的聚集系统,其中系统建立了统计或确定了发现,可了解个人的一生。因而,系统可以了解超出当前疾病状态范围内容。一个人的疾病状态,过往,现在,或将来,也可以对应其它的信息,相对于“大数据”包括健康成像(参考qiimagingtm,位于urlwww.qiimaging.com),或包括结果水平(参考可能的net.orangetm,参考urlwww.ndorange.com)。进一步的,流对象可存储与横跨世代的家族管理器中,其中流对象可横跨相关的同时期的家族成员或横跨好几代。在这是实施例中,分析流在后生的层面提供了视角。
在图7中所有说明的动态成分中的整合,具有评估横跨一或多个分析流对象的生命期限的后生效果的能力。例如,一关于当前分析流的实时的治疗协议可以产生积极的,消极的,或中性的治疗效果,对于相关后裔的分析流的效果也是相同。在某些实施例中,分析流对象可认为是后生流对象,甚至为跨代的后生流对象。
对于公开的学习为主的生活照顾,甚至癌症照顾,分析流可进一步获得数据的增加,数据来自于更多的特定信息,包括特定的基因组信息。在某些实施例中,排序设备可把序列数据增加至一分析流,序列数据可以是双微小体,微小rna,相关循环肿瘤细胞的基因组信息,或其它信息。这些数据也可跨越一或多个分析流,特别是外生数据流。
分析流也可利用生物计量的数据,包括把生命体征监视数据整合入一或多个分析流中。如果一个体雇佣了一或多个健康护理提供者(例如,一医生的诊室,一医院,救护车等),健康护理提供者经常收集一或多个数据点的数据。过去,所有超过99%收集的数据被丢弃了。在公开的生态系统中,所有的数据可以存储或整合入个人的健康护理分析流中。例如,一病人的生命体征数据可通过isironatmdeviceconxtm技术收集,数据随后通过一电子病历交换机进行路由。进一步的,生命体征数据可限制于或整合于一分析流对象。因而,实时的生命体征数据(例如,多元分析,因素分析,推断等)可与其它的数据相关流体相联系。例如,实时脉搏血氧计数据可横跨一或多个后生的流对象,与基因组数据相联系。
本发明的另一特点是包括基于分析数据的社会网络构造,其中分析数据从流对象的数据流管理中获得。由于数据流相关的一或多个流对象通过分析节点,流对象可被注释分析的配置文件,其中分析的配置文件可被认为表示了可能的与流对象相关的健康护理文本。分析引擎可随后为终端用户(例如,病人,股东,健康服务提供者,服务提供者,付款人等)提供建议,以加入或示例在类似的配置文件上彼此之间的社会网络。例如,考虑如下场景,当一组病人具有相似的基因组的配置文件时,也许会具有类似的表型的配置文件,与一brca突变相关。为响应发现,分析引擎作为一社会网络的引擎运转,它可以对病人或其它股东可用,通过它股东可以交流或分享经验。社会网络也可以作为一公共网络或一个别的,独立网络,它可能依赖于分子的指纹识别的本性。因而,基于流的社会网络可以向公众开放,向那些展示特殊基因组的配置文件的个体开放,甚至仅限于与股东相关的具有一特别基因组配置文件的特别的病人。社会网络可提供病人间的相互支持,护理提供者之间的知识分享,股东间的询证照料的协调发送,决策支持,家庭护理集合,救济院支持,或其它类型的在股东间的连续信息交换。
虽然之前的社会网络的例子讨论了基于一健康护理环境的社会网络,社会网络也可支持其它类型的活动,包括基于分析配置文件信息的信息分享。例如,一个体的喜恶可以与基因组的特性相关,并可以同其他推荐的具有相似特性的个体分享。考虑到一基于基因组的社会网络,其参与者具有他们的“生物标志”(例如,基因组,蛋白质组,通路等)信息用于分析,并提供了关于喜爱或厌恶的音乐,或其它内容的特征。公开的分析引擎可尝试建立具有基因组特征的音乐属性内的相关性。引擎随后可以向其他参与者提供基于他们特征的音乐建议。另一例子可包括基于他们的基因在特征匹配人群。例如,一人可基于互补特征,相似特征,或其它特征进行匹配。虽然社会网络涉及健康护理,音乐和匹配,它也可以延伸到这些市场之外。例如,附加的基于基因组的社会网络可以包括博彩网络,购物网络,娱乐网络(例如,品酒,影视俱乐部等),教育或学术网络(例如,家庭教师,学习小组等),业余爱好网络,或其它类型的网络。
通过与相关实体或技术的已存的关系或伙伴关系,申请人具有递交上述分析管理系统的唯一的能力,此项能力由上面讨论的实验设备所证明。进一步的,共有的美国临时申请,其申请号为61/842316,61/842323和61/842325,申请日为2013/07/02,通过归纳健康护理分析流,描述了健康护理管理的不同特点。例如,申请号为61/842323的申请公开了一种能量平衡,它表示了贯穿人的一生的健康护理分析流数据的一可视图像。能量平衡显示为一朵花,而每个花瓣对应一或多个流对象度量。例如,度量可以代表活动水平,睡眠,营养,运动,卡路里,曝光至病原体的危险,或其它涉及对应流对象的个人。花瓣的尺寸,颜色,形状或其它属性可代表相应的度量范围。绿色可表示度量是一可接受的范围,而红色表示度量是不可接受的。
附加事项
下述表格表示了本发明的权利要求。表1包括排序系统的权利要求,包括连接一扩展模块的排序设备,以允许其与一分布式的基因分析系统通信。
表1:带有扩展模块的排序系统
表2概括了一种方法,用于预处理原始序列数据,其中预处理的数据可被转移至一基因组分析设备。
表2:序列数据的预处理
表3显示了一序列分析系统,其中基因组分析系统可以通过双向交换与排序设备互向联络,以管理一基因组分析流。排序设备可使用一或多个适配器。
表3:在分析引擎和排序设备间相互排序
表4显示了一基因组存储设备,它具有一分布式数据和基因组搜索引擎。如之前所述,有多项问题阻碍了下面几项事物实现的能力:(1)快速传输大基因组数据至处理和存储位于集中式的数据中心的计算机,(2)精确的访问在一病人的癌症组织的dna中发现的所有变异,(3)识别在异质疾病中的许多克隆,比如癌症,以及(4)在细胞的信号通路上预测每个克隆的每个变异的系统性影响。公开的分布式系统提供了大量的,缩放的可获取的信息。进一步的,申请者已成功的演示了克服所有这四个困难的能力,以及在正确的时间,为正确的病人预报正确的治疗的能力。作为一快速的和具有陆地宽度的演示,申请者实验使6000个外显子组在69小时内或每个病人在82秒内经历700英里的传送,处理,和突变分析。传输通过nationallambdarail进行,它是一12000英里的光纤网络,遍布美国的医院,诊所,和大学,用于快速的和鲁棒性的传输具有压倒性带宽的数据。
表4:分布式基因组存储设备
除了本发明中已描述的内容,显而易见的对于那些本领域的技术人员,做出许多修改而不背离本发明的内容是可能的。因而本发明并不仅限于附属的权利要求中的范围。而且,为了解释说明书和权利要求,所有的术语应当以一种广泛可能的方式在与文中的解释一致。特别的,术语“包含”和“包括”应当以一种非排他的方式被解释为关于元件,组件,或步骤,以表示相关的元件,组件,或步骤,以用于被展示,或利用,或同其它的未被明显提及的元件,组件,或步骤相结合。其中说明书的权利要求中指出的至少一从组a,b,c…和n中选择的内容,文中应当按照要求解释为只有一组中的元件,而非a加n,或b加n,等。
- 还没有人留言评论。精彩留言会获得点赞!