基于多参数的心血管疾病风险预测网络模型及其构建方法与流程
本发明涉及一种风险预测模型,具体涉及一种基于多参数的心血管疾病风险预测网络模型及其构建方法。
背景技术:
心血管疾病风险的准确预测对预防及早期治疗心血管疾病具有重要意义。据2018年中国心血管病报告显示,中国约有2.9亿人患有心血管疾病,死亡率高达居民疾病死亡率的40%,其中农村心血管疾病死亡率持续高于城市心血管疾病死亡率,目前心血管疾病的患病率和致死率在我国仍呈上升趋势。如何减少和避免患有心血管疾病是降低心血管疾病致死率的工作重心,而对存在患有心血管疾病风险人群进行精准检查,是减少心血管疾病死亡率的关键方法。
目前心血管疾病的诊断方式一般为临床血管造影术和影像诊断,这对医院的基础医疗水平要求较高,对于检查人员而言不但费用昂贵而且对人体具有一定的创伤。临床实践证明,医生可通过血压、血糖、血脂的升高以及心电图和胆固醇异常等关联属性进行评估心血管疾病风险,但这对医生的理论知识和实践经验要求非常高。随着人工智能方法在智慧医疗方面的应用越来越广泛,利用其对临床医疗生理数据进行分析预测,为医生诊断提供辅助指导已经成为精准医疗的基础。
目前,现有心血管疾病风险预测方法,例如随机森林方法、支持向量机方法、二维卷积神经网络方法等大部分仍是针对于医学影像作出的预测,针对多生理参数数据的模型少且效果不理想。
技术实现要素:
为了解决现有心血管疾病风险预测模型存在的无法针对多种生理参数进行预测并且预测效果不理想的问题,本发明提供一种基于多参数的心血管疾病风险预测网络模型及其构建方法。
本发明为解决技术问题所采用的技术方案如下:
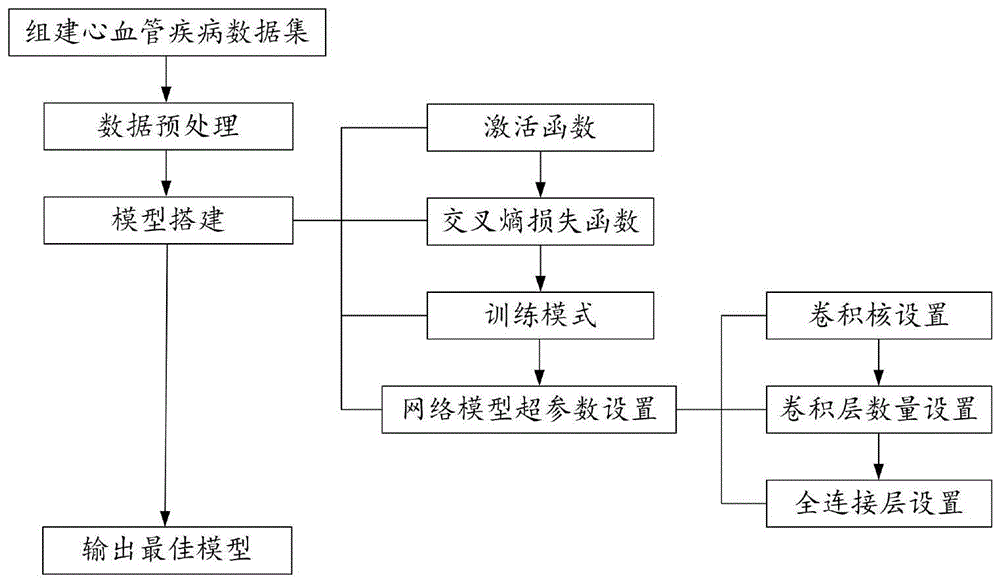
本发明的基于多参数的心血管疾病风险预测网络模型的构建方法,包括以下步骤:
步骤一、组建心血管疾病数据集;
步骤二、对数据集数据进行预处理,并将预处理后的数据集划分成训练集和测试集;
步骤三、模型搭建
所述训练集和测试集中均包括样本和标签,训练集数据在训练过程中通过前向传播和反向传播最小误差进行模型训练,通过测试集数据对训练好的模型进行评估。
进一步的,步骤一具体包括以下步骤:
采用heartdisease心血管疾病数据集中的cleveland子数据集作为心血管疾病数据集,来源于uci数据库,该数据集中含有303条数据,每条数据均包含13个特征属性和1个标签属性,数据集属性及描述如表1所示:
表1
num表示对数据的分类标签,包含3类数据,标签值为0表示没有患病风险的数据,标签值为1表示有患病风险的数据,标签值为2表示已经患有心血管疾病的数据。
进一步的,步骤二具体包括以下步骤:
(1)采用缺失值所在属性的平均值对数据集中的缺失值进行补充;
(2)将数据集中的非数值型特征值进行数值转换,将性别中的female转化成0,male转化成1;
(3)针对数据集中不同数据属性之间的不同取值范围,采用归一化和标准化处理,采用公式(1)进行均值归一化处理:
其中,μ表示数据集中同一属性的所有数据均值,σ表示数据集中同一属性的所有数据均差,x表示数据输入值,x*表示归一化后数据输出值;
(4)将标签值转换成独热码,将0转换成001,1转换成010,2转换成100,并将数据集中的数据随机打乱,按训练集数据数量与测试集数据数量之比为7:3的比例将数据集划分成训练集和测试集。
进一步的,步骤三具体包括以下步骤:
s301、构建relu激活函数;
s302、构建交叉熵损失函数;
s303、设置训练模式;
s304、设置网络模型超参数。
进一步的,步骤s301中,所述relu激活函数的表达式如式(2)所示:
f(x)=max(0,x)(2)
其中,f(x)表示relu激活函数,x表示数据输入值。
进一步的,步骤s302中,所述交叉熵损失函数用于衡量输出预测概率分布与真实类别概率分布,若分类函数采用softmax函数,则交叉熵损失函数的表达式如式(3)所示:
其中,l表示损失值,yj表示真实值概率分布,sj表示预测值概率分布,t表示分类类别,j表示某一类别,j∈(1,t)。
进一步的,步骤s303中,采用两种优化方法进行训练:
第一种采用mini-batch梯度下降算法,将数据集划分成相同大小的batch数据,batch数据的大小为20,构建数据生成器,依次分批读取数据,即每次读取一个batch数据直接送入模型;
第二种采用adam优化算法最小化损失函数,其权重更新公式如式(4)所示:
其中,α表示自适应性学习率,α为0.001,t表示次数,mt表示梯度的一阶矩估计,
进一步的,步骤s304具体包括以下步骤:
s3041、卷积核设置
卷积神经网络结构包括:输入层、两层卷积层、两层池化层、全连接层、输出层,两层卷积层、两层池化层和全连接层组成隐藏层;
模型训练的具体流程如下:
s30411、开始;
s30412、调用数据集;
s30413、网络初始化,赋予初值;
s30414、调用训练集;
s30415、依次分批读取训练集数据,即每次读取一个batch数据直接送入网络;
s30416、利用公式(2)给出的relu激活函数求出隐藏层输出;
s30417、利用公式(3)给出的交叉熵损失函数求出输出层输出;
s30418、求出输出层偏差;
s30419、判断输出层偏差是否满足设定要求;
s30420、是的话,则直接输出模型,结束训练;否的话,则按照公式(4)调整隐藏层到输出层的连接权值,再调整输入层到隐藏层的连接权值,更新权重后重复s30415至s30419,直到输出层偏差满足设定要求;
通过设置不同数量及大小的卷积核进行模型训练,通过训练参数、分类时间、最高准确率、最终准确率对结果进行分析,选取分析结果中准确率最高的三种网络模型结构,对比卷积核大小对网络模型结构的影响,结果显示,搭建两层卷积神经网络时卷积核数量为32且卷积核大小为2时,网络模型效果最佳;
s3042、卷积层数量设置
设置卷积核数量为32、大小为2,按步骤s3041进行模型训练;通过对卷积层层数不同的卷积神经网络进行对比,结果显示,当卷积层数量为2时,网络模型效果最佳;
s3043、全连接层设置
全连接层共设置为两层连接层,第一层为全连接层的神经元数目,将提取到的多维特征参数映射成一维特征参数,并采用relu激活函数对神经元进行激活;第二层全连接层为softmax层,用于预测输出值概率分布和目标值概率分布的相似性,通过式(5)计算出预测值概率:
其中,t表示类别种类,si表示第i个神经元的输出,z表示全连接层的输出向量,zi表示向量z的第i个输出,zk表示向量z的第k个输出,t表示分类类别,k表示某一类别,k∈(1,t);
按步骤s3041进行模型训练,结果显示,全连接层的神经元数量为512时,网络模型效果最佳;
综上,搭建卷积核数量为32、卷积核大小为2、神经元数量为512的两层卷积神经网络作为心血管疾病风险预测网络模型。
通过本发明的构建方法构建出的一种基于多参数的心血管疾病风险预测网络模型,可通过检测者的年龄、性别、胸痛类型、静息血压、血清胆固醇、空腹血糖、静息心电图、最大心率等13项生理参数来评估患有心血管疾病的风险。
本发明的有益效果是:本发明提出了一种能够利用多种生理参数的1-dcnn心血管疾病风险预测网络模型,此模型利用的多项临床数据简便易得,模型适用范围广泛。一维卷积神经网络(1-dimensionalconvolutionalneuralnetworks,1-dcnn)在处理一维数据时效果显著,在心拍类别识别、实时心脏按压评估、心律不齐分类等方面,准确率能够达到98%及以上的效果。
本发明的基于多参数的心血管疾病风险预测网络模型通过血糖、血压、心电、胆固醇等13余项生理参数预测检测者是否存在患有心血管疾病风险的可能性,与现有技术相比,具有以下优点:
1、针对于目前现有训练集数据训练过程中,需要全部训练数据集经过一次完整的迭代(epoch)才会进行一次权值更新,权值更新速度慢。本发明采用mini-batchm梯度下降法进行优化,它是将其全部训练集数据分成大小相同的batch数据进行分批训练,每训练一个batch就会更新一次权值,但是,数据虽然并没有全部参与训练,但仍然需要加载,造成了占用内存和需要花费更长时间,因此,本发明在采用mini-batch梯度下降法的基础上,搭建了一个数据生成器,将数据集切割成制定的batch大小数据加载入数据生成器中,直接将数据生成器中的数据送入模型进行训练,既解决了全部数据迭代一次才会更新一次权值的问题,又释放了内存,缩短训练时间。
2、本发明通过判断模型的训练误差的大小来决定权值更新方向。训练集大小,需要经过慎重综合考虑,过大则导致下降方向不会发生改变,过小则导致训练误差不收敛,经过多次反复试验,本发明将batch大小设置为20。
3、目前对于心血管疾病的风险评估主要集中在临床冠状动脉造影术、医学影像、24小时动态心电图等手段,这些方法不仅对人体有创伤、检查费用贵,并且检查麻烦。人体的常规生理参数在心血管疾病的风险评估方面起到的重要作用并没有被人们重视起来。通过大量的医学经验可知,丰富的理论知识和实践经验的医生可通过血压、血糖、血脂的升高、心电图和胆固醇异常等关联属性进行评估心血管疾病风险。因此,本发明的模型可以通过检测者的年龄、性别、胸痛类型、静息血压、血清胆固醇、空腹血糖、静息心电图、最大心率等13项生理参数来评估患有心血管疾病的风险。
4、本发明的基于多参数的心血管疾病风险预测网络模型可以适应多种场合的需要,其数据可以是来源于医院检查后的临床数据,还可以是社区医院、门诊数据等,也可以是家庭式医疗监护仪器采集的生理数据。因此,本发明的模型所需数据来源广泛,便于采集,充分发挥了多种生理参数与心血管疾病之间的关联性,在测试集中取得100%准确率。
附图说明
图1为本发明的基于多参数的心血管疾病风险预测网络模型的构建方法流程图。
图2为卷积神经网络的结构图。
图3为模型训练流程图。
图4为所有卷积核大小均为2的1-dcnn模型中在训练参数、分类时间、最高准确率(acc)、最终准确率(acc)4个方面的对比图。图4a为训练参数变化图;图4b为分类时间变化图;图4c为最高准确率变化图;图4d为最终准确率变化图。
图5为卷积核大小对网络模型结构的影响。图5a为训练参数变化图;图5b为分类时间变化图;图5c为最高准确率变化图;图5d为最终准确率变化图。
图6为不同卷积层数量的acc-loss变化图。图6a为两层卷积神经网络的acc-loss变化图,图6b为三层卷积神经网络的acc-loss变化图;图6c为四层卷积神经网络的acc-loss变化图。
图7为全连接层不同神经元数量的acc-loss变化图。图7a为神经元数量为512的acc-loss变化图;图7b为神经元数量为256的acc-loss变化图。
具体实施方式
以下结合附图对本发明作进一步详细说明。
如图1所示,本发明的基于多参数的心血管疾病风险预测网络模型的构建方法,具体包括以下步骤:
步骤一、组建心血管疾病数据集
所使用的数据来源于uci数据库,采用的数据集为heartdisease心血管疾病数据集中的cleveland子数据集。该子数据集中含有303条数据,每条数据中都包含13个特征属性和1个标签属性,数据集属性及描述如表1所示。
表1
其中,num表示的是对数据的分类标签,共包含3类数据,标签值为0的表示的是没有患病风险的数据,标签值为1的表示的是有患病风险的数据,标签值为2的表示的是已经患有心血管疾病的数据。
步骤二、数据预处理
步骤一所获得的原始数据集中含有缺失值和非数值型特征值,需要对其进行预处理,包括缺失值补充、非数值型特征值转换和数据归一化处理。
对缺失值进行补充,采用缺失值所在属性的平均值进行补充;将非数值型特征值进行数值转换,将性别中的female转化成0,male转化成1;针对数据集中不同数据属性之间的不同取值范围,采用归一化和标准化消除量纲不同的影响,针对数据属性采用公式(1)进行均值归一化处理。
其中,μ表示数据集中同一属性的所有数据均值,σ表示数据集中同一属性的所有数据均差,x表示数据输入值,x*表示归一化后数据输出值。
为使特征属性之间距离计算更加合理,将标签值转换成独热码,将0转换成001,1转换成010,2转换成100,并将数据集中的数据随机打乱,按照训练集数据数量与测试集数据数量之比为7:3的比例将数据集划分成训练集和测试集。
步骤三、模型搭建
按照步骤二将心血管疾病数据集划分成训练集和测试集,训练集和测试集中均包括样本和标签;训练集数据在训练过程中通过前向传播和反向传播最小误差进行模型训练,通过测试集数据对训练好的模型进行评估,检测其泛化能力的强弱。
s301、relu激活函数
数据在隐藏层中的特征提取、分类过程,都需要激活函数来增加提取的特征的非线性,弥补原有线性网络的表达能力,将经过激活后的特征图通过函数保留并映射到下一层中。所用激活函数均选择relu激活函数,其表达式如式(2)所示。
f(x)=max(0,x)(2)
其中,f(x)表示relu激活函数,x表示数据输入值,可以使网络更快地收敛,因为在一半区域内小于0的数据不会反向传播,在一定程度上解决了梯度消失问题。
s302、交叉熵损失函数
交叉熵损失函数用于模型训练。交叉熵损失函数用于衡量输出预测概率分布与真实类别概率分布,若分类函数采用softmax函数,则交叉熵损失函数的表达式如式(3)所示。
其中,l表示损失值,yj表示真实值概率分布,sj表示预测值概率分布,t表示分类类别,j表示某一类别,j∈(1,t)。
s303、训练模式
为了提高训练出的模型效果,在原有网络训练结构的基础上进行了两种优化。
第一种采用mini-batch梯度下降算法进行优化,在对数据集进行梯度下降训练时不采用全部数据集,而是采用划分成相同大小的batch数据进行训练,加速梯度下降。
一般来说,batch将决定整个网络的训练方向,对模型的训练效果有重要影响,过大可能导致下降方向不会发生改变,过小可能导致训练误差不收敛。
虽然mini-batch梯度下降算法是对数据进行分批训练,但是仍然会将全部数据集一起送入模型,因此,为了解决上述问题,本发明构建了一个数据生成器,依次分批读取数据,即每次读取一个batch数据直接送入模型,解决了占用内存、浪费时间等问题,综合数据集特性,将batch数据的大小设置为20。
第二种优化方式则是针对随机梯度下降算法的局限性,即只能使用单一学习率更新所有的权重,改用adam优化算法最小化损失函数,它能够根据过计算梯度的一阶矩估计和二阶矩估计、针对不同的参数设置自适应性学习率,其权重更新公式如式(4)所示。
其中,α表示自适应性学习率,t表示次数,mt表示对梯度的一阶矩估计,
s304、网络模型超参数设置
s3041、卷积核设置
如图2所示,卷积神经网络结构主要包括:输入层、两层卷积层、两层池化层、全连接层、输出层。其中,两层卷积层、两层池化层、全连接层组成隐藏层。
首先,按照图3所示流程进行模型训练。具体流程如下:
s30411、开始;
s30412、调用数据集;
s30413、网络初始化,赋予初值;
s30414、调用训练集;
s30415、依次分批读取训练集数据,即每次读取一个batch数据直接送入网络;
s30416、利用公式(2)给出的relu激活函数求出隐藏层输出;
s30417、利用公式(3)给出的交叉熵损失函数求出输出层输出;
s30418、求出输出层偏差;
s30419、判断输出层偏差是否满足设定要求;
s30420、是的话,则直接输出模型,结束训练;否的话,则按照公式(4)调整隐藏层到输出层的连接权值,再调整输入层到隐藏层的连接权值,更新权重后重复s30415至s30419,直到输出层偏差满足设定要求。
通过设置不同数量及大小的卷积核,通过训练参数、分类时间、最高准确率、最终准确率(acc)4个方面对实验结果进行分析,结果如图4所示。
从图4中可以看出,当两层卷积层的卷积核数量为8*8时,卷积神经网络训练特征参数是18593,最高准确率为79.62%,当卷积核数量为16*16时,参与训练的特征参数增加到35395,最高准确率为100%。由此可得出,当卷积神经网络从训练集中所提取的特征参数过少时,其不能完全学习到训练集的数据特征,模型的预测效果较差,随着卷积核数量的增加,参与训练的特征参数增多,模型的准确率得到提高,提升了20.38%。当卷积核数量为32*32时,参与训练的特征参数为69763,模型的准确率达到最优,最高准确率和最终准确率均为100%;在这之后,随着卷积核数量的增加,参与训练的特征参数越多,最高准确率和最终准确率均有所下降,其中最高准确率保持在92.31%左右,但最终准确率最低只有84.62%,这表明,卷积神经网络提取到足够的特征参数后,模型预测能力达到最高,之后,特征参数增多,使得网络过于细化学习训练集数据,导致其模型泛化能力减弱,准确率反而下降。
选取图4中准确率最高的三种网络模型结构,对比卷积核大小对于网络模型结构的影响,结果如图5所示。其中,横坐标为卷积核的数量(个),纵坐标分别表示其训练参数、分类时间、最高准确率(acc)、最终准确率(acc)变化图。
从图5可以看出,当网络模型结构中卷积核数量相同的情况下,卷积核大小为2时较卷积核大小为3时参与训练的特征参数更少、运算时间更快、准确率更高,其分类结果更稳定。
综合图4和图5可知,卷积神经网络最高准确率为100%的有三个,其卷积核数量分别为16、32和256,卷积核大小均为2。但卷积核数量为16和256时其结果并不稳定,在多次迭代后,其准确率反而下降,最终准确率仅为92.31%,结合考虑分类时间,发现搭建两层卷积神经网络时卷积核数量为32且卷积核大小为2时,网络模型效果最佳。
s3042、卷积层数量设置
卷积神经网络性能不仅与卷积核的数量与大小有关,还与卷积层数量相关,故设置卷积核数量为32、大小为2。然后按照图3所示流程进行模型训练,其具体操作步骤同步骤s3041。
通过对卷积层层数不同的卷积神经网络进行对比实验,其结果如图6所示。其中,trainloss表示训练集损失,testloss表示测试集损失,trainacc表示训练集准确率,testacc表示测试集准确率。
如图6所示,随着迭代次数(epoch)的增加,三种模型无论是训练集还是测试集的loss均呈现逐渐下降趋势,图6(a)中,测试集准确率达到100%,超出测试集准确率的0.091%,而图6(b)和图6(c)中训练集准确率均比测试集准确率高,测试集准确率最高只有92.31%。故当卷积层数量为2时,网络模型效果最佳。
s3043、全连接层设置
全连接层共设置为两层连接层,第一层为全连接层的神经元数目,将前面提取到的多维特征参数映射成一维特征参数,并采用relu激活函数对神经元进行激活;第二层全连接层被称为softmax层,用于预测输出值概率分布和目标值概率分布的相似性,通过式(5)可计算出预测值概率。
其中,t表示类别种类,si表示第i个神经元的输出,z表示全连接层的输出向量,zi表示向量z的第i个输出,zk表示向量z的第i个输出,t表示分类类别,k表示某一类别,k∈(1,t)。
然后按照图3所示流程进行模型训练,其具体操作步骤同步骤s3041,结果如图7所示。从图7可以看出,全连接层的神经元数量为512时,测试集的损失值一直呈下降趋势,测试集准确率一直维持在100%;但神经元数量为256时,测试集的损失值在后10次训练过程中出现了损失值下降趋势平缓,甚至有上升趋势,其最高准确率只有92.31%。
以上结果表明,搭建卷积核数量为32、大小为2、神经元数量为512的两层卷积神经网络作为本发明的心血管疾病风险预测网络模型在预测心血管疾病风险时效果最佳。
步骤四、将测试集数据送入上述已经训练好的心血管疾病风险预测网络模型中,得出心血管疾病风险评估结果。
模型评估试验
对于本模型主要从准确率(accuracy)、精确率(precision)、召回率(recall)、f1-score、分类时间这5个方面进行评估。准确率、分类时间是评价模型总体分类性能的重要指标,精确率、召回率、f1-score是评价数据某一类的分类结果的重要指标,分类时间指程序运行所用时间,其具体公式如下所示:
其中,tp、fp、fn、tn分别表示混淆矩阵的分类结果,其所表示的含义如表2所示。
表2混淆矩阵
算法结果对比试验
为了评估本发明所建立的心血管疾病风险预测网络模型的性能,在相同数据集中采用不同方法进行心血管疾病的预测实验,其结果如表3所示。
表3不同算法对比
试验表明,现有的机器学习方法如随机森林、支持向量机对于心血管疾病的预测结果都不理想,随机森林准确率只有81.3%,三种分类的平均召回率、精确率和f1-score值均不高;支持向量机模型算法准确率达到85.7%,其召回率、精确率、f1-score值在80%左右;将数据集组合成二维数据的方法,构建的基于二维卷积神经网络模型准确率达到89.89%,其召回率、精确率、f1-score值在85%左右;而本发明的心血管疾病风险预测网络模型在测试集中准确率达到100%,比随机森林方法提高18.7%,比支持向量机方法提高14.3%,比二维卷积神经网络方法提高10.11%,比其他三种模型准确率提高了至少10.11%,本发明的心血管疾病风险预测网络模型更具有优势。
本发明针对心血管疾病数据集特性,通过优化1-dcnn卷积神经网络结构和关键参数,建立了两层卷积层的卷积核数量为32、大小为2的卷积神经网络模型,该模型通过对血糖、血压、心电、胆固醇等多生理参数进行预处理,并在卷积层及池化层中自动提取预处理后的数据集的特征参数,实现了对于有、无患有心血管疾病风险和已经患有心血管疾病的三种结果分类。将该模型应用于医院诊断和家庭医疗中,能够增强人民对于心血管疾病的预防意识、提高人民的基础医疗水平,能为医生诊断提供辅助支持。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!