一种抑郁症患者预后药效评估系统及其评估方法与流程
本发明属于数据识别领域,特别涉及一种抑郁症患者预后药效评估系统及其评估方法。
背景技术:
个体对具体治疗方式的应答效果不同,若能提前预测患者对治疗方式的应答,则可根据预测结果有目标的选择最佳治疗方案,避免盲目的试验治疗并达到节省医疗费用、提高治愈率的效果。在预测抗抑郁药物治疗效果方面,个性化药物的使用仍处于起步阶段。很少有人研究建立预测模型来估计抗抑郁药物治疗反应的方法。
技术实现要素:
发明目的:针对上述问题,本发明提供一种抑郁症患者预后药效评估系统及其评估方法,能够基于患者治疗前特征进行药效预测,辅助指导医护人员做出精准治疗,提高治疗效果。
技术方案:本发明提出一种抑郁症患者识别系统,包括数据源层、分析处理层和应用层;
数据源层:用于将原始数据经过处理和清洗后作为系统的数据源;
分析处理层:用于数据挖掘分析和建立预测模型;
应用层:用于将分析处理层的分析结果进行展示以及提供预测模型的使用入口。
进一步的,所述数据源层包括候选基因甲基化测序数据、临床数据和量表信息;
所述分析处理层包括数据挖掘模块和预测模型建立模块;
所述应用层包括挖掘结果展示模块和预测模型应用模块。
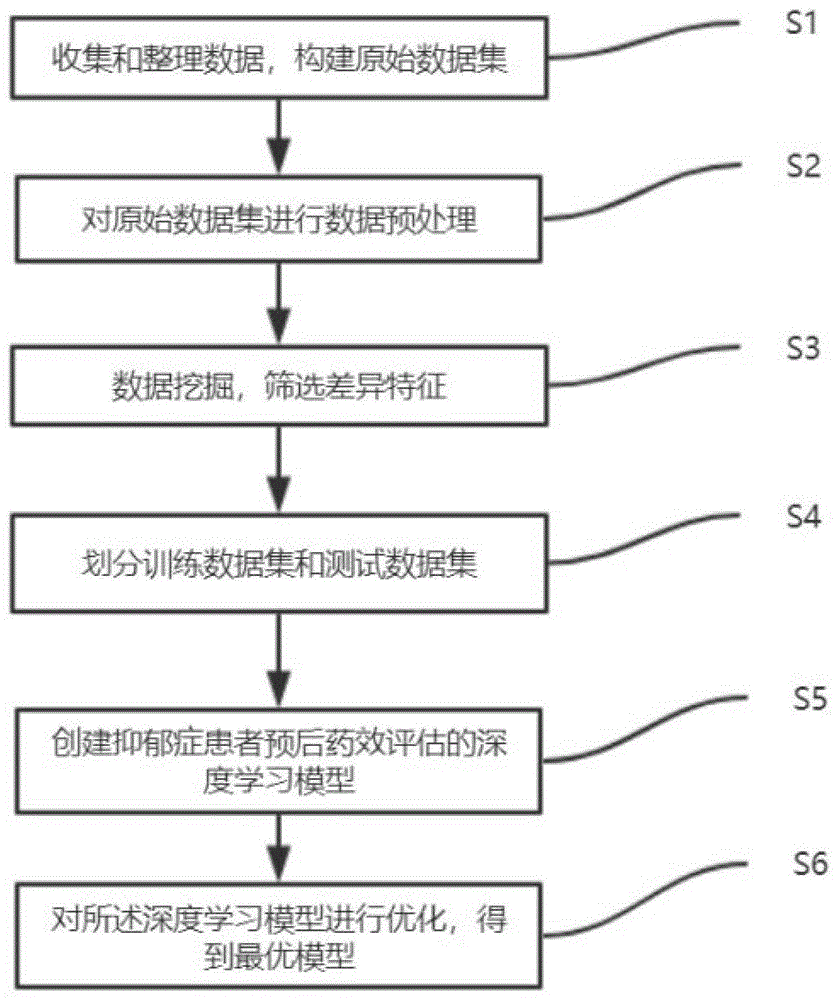
一种如上所述的抑郁症患者预后药效评估系统的评估方法,包括如下步骤:
(1)收集和整理数据,构建原始数据集,其中数据包括候选基因甲基化测序数据、临床信息和诊断量表数据;
(2)对原始数据集进行数据预处理得到实验数据集;
(3)对预处理之后得到的实验数据集进行数据挖掘,筛选差异特征,建立输入数据集;
(4)将输入据集划分为训练数据集和测试数据集;
(5)创建抑郁症患者预后药效评估的深度学习模型,利用训练数据集对创建的深度学习模型进行训练;
(6)利用测试数据集对训练好的深度学习模型进行性能评估,并在评估过程中对模型进行不断优化,得到最优模型。
进一步的,所述步骤(1)中收集和整理数据,构建原始数据集合的具体步骤如下:采集符合诊断标准入组的抑郁症患者的跟踪治疗数据,数据包括候选基因甲基化测序数据,临床数据,诊断量表数据。将上述3类数据整理合并作为原始数据集合。
进一步的,所述步骤(2)中数据预处理包括类别特征编码、缺失值处理、异常值分析和数据标准化。原始数据集进行数据预处理之后得到实验数据集。
进一步的,所述步骤(3)中数据挖掘,筛选差异特征的具体步骤如下:通过统计学方法或机器学习方法对数据进行数据挖掘,筛选出差异特征,并基于这部分特征建立模型;对实验数据集进行特征选择之后得到输入数据集。
进一步的,所述步骤(4)中将输入数据集划分为训练数据集和测试数据集的具体步骤如下:将输入数据按比例分割为训练集和测试集,所述训练集和测试集比例通常为0.7:0.3或0.8:0.2。
进一步的,所述步骤(5)中创建抑郁症患者预后药效评估的深度学习模型的具体步骤如下:
(5.1)为训练数据集中的每一个目标位点构建一个神经网络,所述神经网络是以全连接神经网络模型与输出层sigmoid函数构建,包括输入层、隐藏层和输出层;
(5.2)设定所述神经网络模型的输入层,其中,假定训练样本数为m,训练数据集中每个样本的特征数为n,则训练数据集的输入矩阵表示为x(m*n),其中所述的每一行表示一个样本的所有特征,每一列对应所述的特征数据;输入神经元个数设置为n,使用的激活函数为relu;
(5.3)设定所述神经网络每层之间采用全连接的方法,即除输入层外,模型中各个神经元存储的数据与上一层所有神经元有关;即所述神经网络模型的隐藏层,隐藏层的输入数据为输入层的输出数据,隐藏层神经元个数设置为m,使用的激活函数为relu;
(5.4)设定所述神经网络模型的输出层,其中,输出层的输入数据为隐藏层的输出数据,输出层神经元个数设置为c,使用的激活函数为sigmoid;所述sigmoid函数公式为:
(5.5)将训练数据集带入构建的深度学习模型中,其中,输入神经元个数n=n=19,隐藏层1神经元个数m=12,隐藏层2神经元个数m=4,输出层神经元个数c=1,以输入向量所对应的输出值作为目标真实值训练模型。
进一步的,所述步骤(6)中利用测试集对训练好的深度学习模型进行性能评估的具体步骤如下:将测试集输入到训练好的神经网络中,验证评估过程中调整模型超参数对模型进行不断优化,找到最优模型超参数合集。
近年来,机器学习因其可基于患者治疗前基线特征进行疗效预测的功能逐渐被用来指导抑郁症治疗方案的选择。与传统的机器学习方法相比,深度学习表现出更高的分类准确性。基于上述考虑,我们使用深度学习基于候选基因甲基化测序数据、临床基本信息、量表信息构建抑郁症治疗结果的预测模型是可行且有效的。
本发明采用上述技术方案,具有以下有益效果:
本发明以多维分析、数据挖掘和深度学习技术为基础,设计能够实现抑郁症预后药效预测的模型及系统,可以揭示数据信息中隐藏的病人情况和治疗结果的趋势,辅助指导医护人员做出精准治疗,提高治疗效果并降低医疗成本。
附图说明
图1为本发明的流程图;
图2为具体实施例中抑郁症患者预后药效评估模型示意图;
图3为具体实施例中神经网络模型示意图;
图4为具体实施例中抑郁症患者预后药效评估模型的准确性示意图;
图5为本发明的结构示意图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,但是本发明要求保护的范围并不局限于此。
实施例1
如图1~3所示,本发明一种基于深度学习的抑郁症患者预后药效评估方法,所述方法包括以下步骤:
s1:收集和整理数据,构建原始数据集,数据包括候选基因甲基化测序数据、临床信息和诊断量表数据;
s2:对原始数据集进行数据预处理得到实验数据集,数据预处理包括类别特征编码、缺失值处理、异常值分析、数据标准化等;
s3:对预处理之后得到的实验数据集进行数据挖掘,筛选差异特征,建立输入数据集;
s4:将输入数据集按照一定比例随机划分为训练数据集和测试数据集;
s5:创建抑郁症患者预后药效评估的深度学习模型,利用训练数据集对创建的深度学习模型进行训练;
s6:利用测试数据集对训练好的深度学习模型进行性能评估,并在评估过程中对模型进行不断优化,得到最优模型。
在一些具体的实施例中,所述s1中收集和整理数据,构建初步数据集合的具体步骤如下:采集符合诊断标准入组的抑郁症患者的跟踪治疗数据,数据包括候选基因甲基化数据(开展药物治疗之前对抑郁症患者进行候选基因甲基化测序),临床数据(包括患者年龄、受教育水平、婚姻状况、首次发病年龄、服药状况、发病次数等基本信息),诊断量表数据(包括贝克自杀意念评分、药物不良反应评分、多伦多述情感障碍评分等访谈测评信息)。将上述3类数据整理合并作为原始数据集合。
可选的,在其中一个实施例中,所述s2对原始数据集合进行数据预处理得到实验数据集的具体步骤如下:
s201:数据预处理可以提高数据的质量,有助于提高后续学习模型的精度。根据临床实际情况,大多数直接数据无法实现实时采集,且采集频率也存在一定差异,这会导致数据分布稀疏。由于医疗数据具有复杂性、异构性以及时序不连续等特点,导致采集的原数据存在大量噪声,如存在异常值、数据缺失等问题,需要对原始数据进行清洗之后才能进一步使用。数据预处理包括包括类别特征编码、缺失值处理、异常值分析、数据标准化等。
s202:类别型特征如性别特征,取“男性”和“女性”两个值,这种特征不是连续型特征,需要使用特征编码进行处理。为了避免人为引入次序,使用独热编码对这一类特征进行编码。
s203:缺失值通常编码为空白,nan或其他占位符。这样的数据不能直接作为参数传入到模型中。缺失值的处理策略,可以选择直接丢弃,或者使用缺失值所在行或列的平均值、中值或众数等对其进行填补。考虑到甲基化数据种某些测序位点出现缺失的原因,进行填补不能反应真实的测序结果,所以选择直接丢弃缺失值存在的行或者列。临床数据和量表数据对其进行缺失值填充。
s204:异常值的存在对最后的结果分析会产生影响。如何处理取决于异常值的产生原因以及应用目的。若是由随机因素产生,忽略或者剔除异常值即可,若是由不同机制产生,需要重点关注。考虑到此实例中异常数据点的存在符合实际结果,给予保留。
s205:为了消除数据特征之间的量纲影响,需要对特征进行标准化处理,使不同指标之间具有可比性。标准化方法有min-max标准化、log函数转换、反正切函数转换、标准差标准化(zero-meannormalization)。选择min-max标准化的方法对特征进行处理。所述min-max标准化公式为:
s206:原始数据集进行以上数据预处理之后得到实验数据集。
在一些具体的实施例中,所述s3对实验数据集进行数据挖掘,筛选差异特征,建立输入数据集的具体步骤如下:通过统计学方法或机器学习方法对数据进行数据挖掘,筛选出差异特征,并基于这部分特征建立模型,可以提高模型的预测能力。实验数据集进行特征选择之后得到输入数据集。
在一些具体的实施例中,所述s4将输入数据集按照一定比例划分训练数据集和测试数据集的具体步骤如下:预处理之后的数据集被划分为训练数据和测试数据,其中训练集数据用于模型的训练,测试数据不参与模型训练,用于优化模型和检验模型的预测能力。获取方式是在处理所有的数据之后按一定的比例分割训练集和测试集,该比例通常为0.7:0.3和0.8:0.2,如在0.8:0.2中,0.8为训练集,0.2为测试集。
在一些具体的实施例中,所述s5创建抑郁症患者预后药效评估的深度学习模型的具体步骤如下:
s501:为训练数据集中的每一个目标位点构建一个神经网络,所述神经网络是以全连接神经网络模型与输出层sigmoid函数构建,包括输入层、隐藏层和输出层。
s502:设定所述神经网络模型的输入层,其中,假定训练样本数为m,训练数据集中每个样本的特征数为n,则训练数据集的输入矩阵表示为x(m*n),其中所述的每一行表示一个样本的所有特征,每一列对应所述的特征。输入神经元个数设置为n,使用的激活函数为relu。
s503:设定所述神经网络模型的隐藏层,隐藏层的输入数据为输入层的输出数据,隐藏层神经元个数设置为m,使用的激活函数为relu。
s504:设定所述神经网络模型的输出层,其中,输出层的输入数据为隐藏层的输出数据,输出层神经元个数设置为c,使用的激活函数为sigmoid。所述sigmoid函数公式为:
s505:将训练数据集带入构建的深度学习模型中,其中,输入神经元个数n=n=19,隐藏层1神经元个数m=12,隐藏层2神经元个数m=4,输出层神经元个数c=1,以输入向量所对应的输出值作为目标真实值训练模型。
在一些具体的实施例中,所述s6利用测试集对训练好的深度学习模型进行性能评估的具体步骤如下:将测试集输入到训练好的神经网络中,验证评估过程中调整模型超参数对模型进行不断优化,找到最优模型超参数合集。
实施例2
如图4所示,以实施例1的方法为基础,对符合标准入组的291例抑郁症患者采集治疗数据,并进行建模分析。
1、对符合标准入组的291例抑郁症患者在服药治疗前进行候选基因甲基化测序,其中候选基因为:htr1a,htr1b,s100a10和bdnf,对测序结果进行质量控制和分析,得到dna甲基化测序的ewas分析结果,测序位点数为449个;采集患者的临床数据(包括患者年龄、受教育水平、婚姻状况、首次发病年龄、服药状况、发病次数共13项基本信息)和诊断量表数据(包括贝克自杀意念评分、药物不良反应评分、多伦多述情感障碍评分共5项访谈测评信息);将上述3类数据整理合并作为原始数据集合,共467个特征信息;
2、原始数据集进行数据预处理,包括类别特征编码、缺失值处理、异常值分析、数据标准化。使用独热编码对类别特征进行编码;对甲基化测序数据中的缺失值选择直接丢弃,临床数据和量表数据的连续特征的缺失值根据各自原始分布特征采用所在列的随机数进行填充,离散特征的缺失值采用众数填充;考虑到异常数据点的存在符合实际结果,给予保留;最后选择min-max标准化的方法对特征进行处理。原始数据集进行数据预处理之后得到实验数据集;
3、通过统计学方法对数据进行数据挖掘,筛选出19个差异特征,将其作为输入数据集;
4、输入数据按照0.8:0.2的比例划分为训练集和测试集;
5、为269个样本数据分别构建一个神经网络;其中输入层(inputlayer)神经元个数为19个,隐藏层1神经元为12个,隐藏层2神经元个数为4个,输出层为1个;隐藏层所使用的激活函数为relu,输出层函数为sigmoid,随机梯度下降学习率为0.01,迭代次数为200,批输入数据为32;
6、将训练数据集中每个样本的19个测序位点信息作为神经网络的输入向量,代入模型,以输入向量所对应的y值作为目标真实值训练模型;
7、将测试集数据输入到训练好的模型中,将测试集合的预测效果与真实结果做比较,对模型的超参数不断进行优化,得到最优模型的超参数合集。模型最终预测性能结果如图4所示。
实施例3
如图5所示,提出了一种抑郁症药效辅助诊疗系统,其特征在于,包括:
a:基本数据处理的数据源层,将原始数据经过处理和清洗后作为系统的数据源;
b:分析处理层,包括两个模块,分别是:数据挖掘分析模块和预测模型建立模块;
c:应用层,将分析处理层的分析结果进行展示以及提供预测模型的使用入口。
- 还没有人留言评论。精彩留言会获得点赞!