一种基于计算机视觉的抑郁症检测与识别系统的制作方法
本发明涉及抑郁症技术领域,尤其涉及一种基于计算机视觉的抑郁症检测与识别系统。
背景技术:
抑郁症被形象地称为“心灵感冒”,意思是说抑郁症像伤风感冒一样,是一种常见的心境障碍。据世界卫生组织(who)预测,到2020年底,抑郁症将成为仅次于缺血性心脏病的第2位致残疾病。1998年,世界精神卫生调查委员会对焦虑障碍、心境障碍、冲动一控制障碍及药物依赖的年患病率、疾病严重度、功能损害程度和接受治疗情况等进行了调查。
目前抑郁症的诊断主要包括自我识别与医院或心理咨询机构的诊断两个部分。抑郁症自我识别的关键是患者是否存在有明显情绪低落,患者终日忧心忡忡、抑郁寡欢、愁眉苦脸、长吁短叹;是否有兴趣的缺乏,患者对任何事情都提不起劲,心里有压抑感,高兴不起来;是否有精力不济、疲劳,无论是做脑力劳动还是体力劳动都觉得疲劳,即使充分休息都不能恢复;是否有明显的睡眠障碍,特别是早醒;典型的抑郁患者,其抑郁心境有晨重夜轻的节律改变的特点,即情绪低落在早晨更严重,而傍晚时有所减轻。也可以借助自评量表(如《贝克抑郁问卷》和《zung自评量表》等)进行自我评估。临床研究中常使用他评量表,如汉密尔顿抑郁量表(hamd)及蒙哥马利抑郁量表(mads)评定疾病严重程度。
造成抑郁症识别率低的原因有多种,有患者自身的“病耻感”作祟、抑郁症伴发症状多样且复杂、医师的诊断能力等原因,但有限的公共卫生人力资源则是更为严重的因素。随着社会对精神卫生服务的需求大量增加,精神科医护人员技术力量的匮乏更加突出。目前传统的抑郁症检测与诊断方法需要大量投入人力、物力成本,并且对患者的识别诊断过程耗时长且复杂,所以需要一种基于计算机视觉的抑郁症检测与识别系统。
技术实现要素:
基于现有的抑郁症检测与诊断方法需要大量投入人力、物力成本,并且对患者的识别诊断过程耗时长且复杂的技术问题,本发明提出了一种基于计算机视觉的抑郁症检测与识别系统。
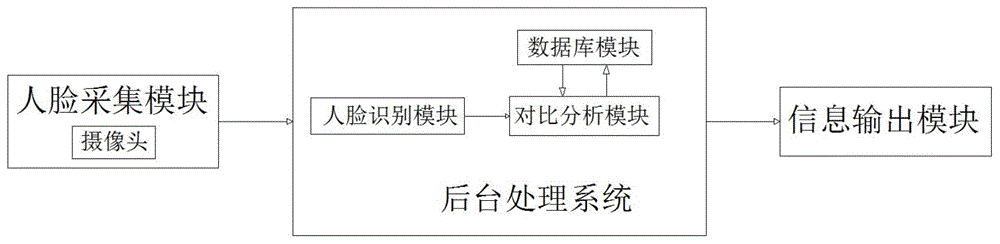
本发明提出的一种基于计算机视觉的抑郁症检测与识别系统,包括人脸采集模块,所述人脸采集模块电性连接有后台处理系统,所述后台处理系统电性链接有信息输出模块。
优选地,所述人脸采集模块为摄像头。
优选地,所述后台处理系统包括有人脸识别模块,所述人脸识别模块电性连接有对比分析模块。
优选地,所述对比分析模块双向电性连接有数据库模块。
优选地,该基于计算机视觉的抑郁症检测与识别系统的使用方法为:
步骤一、收集大量抑郁症和非抑郁症人员人脸图像数据,对数据进行标注,并进行人脸检测、关键点检测、人脸矫正、光照归一化和数据增强预处理操作,并以预处理后的数据集对抑郁症识别模型进行微调训练,通过较多次数迭代后获得一个准确率高且鲁棒性高的识别模型;
步骤二、实际测试过程中,首先获取被试者人脸图像数据,经过与训练阶段相同的预处理后对测试数据进行再次增强,增强后数据一次输入识别模型后得到识别结果。
本发明中的有益效果为:
1、通过设置后台处理系统,在对抑郁症筛查过程中,具有检测速度快和在大人口基数情况下,在保证识别效率的同时也兼顾了较高的识别准确率的效果。
2、通过设置人脸采集模块,在使用时,数据采集端提供一张被试人人脸图像即可完成识别,完全是非接触式的,传统识别方法大多需要辅以多种专业检测设备,从而具有为抑郁症识别工作节省大量人力、物力和财力成本的效果。
3、通过设置人脸采集模块,在使用时,实现用户的随时随地接入访问,操作方便且个人隐私受到严格保护,减轻被试人的心理负担,使其能够及时正确地面对抑郁症问题,从而具有对抑郁症进行尽早发现、尽早就诊和尽早治疗的效果。
附图说明
图1为本发明提出的一种基于计算机视觉的抑郁症检测与识别系统的示意图;
图2为本发明提出的一种基于计算机视觉的抑郁症检测与识别系统的单人识别模式流程图;
图3为本发明提出的一种基于计算机视觉的抑郁症检测与识别系统的批量识别模式流程图;
图4为本发明提出的一种基于计算机视觉的抑郁症检测与识别系统的识别模块训练测试流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
参照图1-4,一种基于计算机视觉的抑郁症检测与识别系统,包括人脸采集模块,所述人脸采集模块电性连接有后台处理系统,所述后台处理系统电性链接有信息输出模块;
人脸采集模块为摄像头,后台处理系统包括有人脸识别模块,所述人脸识别模块电性连接有对比分析模块,对比分析模块双向电性连接有数据库模块;
该基于计算机视觉的抑郁症检测与识别系统的使用方法,其使用方法为:
步骤一、收集大量抑郁症和非抑郁症人员人脸图像数据,对数据进行标注,并进行人脸检测、关键点检测、人脸矫正、光照归一化和数据增强预处理操作,并以预处理后的数据集对抑郁症识别模型进行微调训练,通过较多次数迭代后获得一个准确率高且鲁棒性高的识别模型;
步骤二、实际测试过程中,首先获取被试者人脸图像数据,经过与训练阶段相同的预处理后对测试数据进行再次增强,增强后数据一次输入识别模型后得到识别结果;
通过设置后台处理系统,在对抑郁症筛查过程中,具有检测速度快和在大人口基数情况下,在保证识别效率的同时也兼顾了较高的识别准确率的效果;
通过设置人脸采集模块,在使用时,数据采集端提供一张被试人人脸图像即可完成识别,完全是非接触式的,传统识别方法大多需要辅以多种专业检测设备,从而具有为抑郁症识别工作节省大量人力、物力和财力成本的效果;
通过设置人脸采集模块,在使用时,实现用户的随时随地接入访问,操作方便且个人隐私受到严格保护,减轻被试人的心理负担,使其能够及时正确地面对抑郁症问题,从而具有对抑郁症进行尽早发现、尽早就诊和尽早治疗的效果。
本申请中人脸矫正系统代码为:
#net_factory:rnetoronet
#datasize:24or48
def__init__(self,net_factory,data_size,batch_size,model_path):
graph=tf.graph()
withgraph.as_default():
self.image_op=tf.placeholder(tf.float32,shape=[batch_size,data_size,data_size,3],name='input_image')
#figureoutlandmark
self.cls_prob,self.bbox_pred,self.landmark_pred=net_factory(self.image_op,training=false)
self.sess=tf.session(
config=tf.configproto(allow_soft_placement=true,gpu_options=tf.gpuoptions(allow_growth=true)))
saver=tf.train.saver()
#checkwhetherthedictionaryisvalid
model_dict='/'.join(model_path.split('/')[:-1])
ckpt=tf.train.get_checkpoint_state(model_dict)
print(model_path)
readstate=ckptandckpt.model_checkpoint_path
assertreadstate,"theparamsdictionaryisnotvalid"
print("restoremodels'param")
saver.restore(self.sess,model_path)
self.data_size=data_size
self.batch_size=batch_size
#rnetandonetminibatch(test)
defpredict(self,databatch):
#accessdata
#databatch:nx3xdata_sizexdata_size
scores=[]
batch_size=self.batch_size
minibatch=[]
cur=0
#numofall_data
n=databatch.shape[0]
whilecur<n:
#splitmini-batch
minibatch.append(databatch[cur:min(cur+batch_size,n),:,:,:])
cur+=batch_size
#everybatchpredictionresult
cls_prob_list=[]
bbox_pred_list=[]
landmark_pred_list=[]
foridx,datainenumerate(minibatch):
m=data.shape[0]
real_size=self.batch_size
#thelastbatch
ifm<batch_size:
keep_inds=np.arange(m)
#gap(difference)
gap=self.batch_size-m
whilegap>=len(keep_inds):
gap-=len(keep_inds)
keep_inds=np.concatenate((keep_inds,keep_inds))
ifgap!=0:
keep_inds=np.concatenate((keep_inds,keep_inds[:gap]))
data=data[keep_inds]
real_size=m
#cls_probbatch*2
#bbox_predbatch*4
cls_prob,bbox_pred,landmark_pred=self.sess.run([self.cls_prob,self.bbox_pred,self.landmark_pred],feed_dict={self.image_op:data})
#num_batch*batch_size*2
cls_prob_list.append(cls_prob[:real_size])
#num_batch*batch_size*4
bbox_pred_list.append(bbox_pred[:real_size])
#num_batch*batch_size*10
landmark_pred_list.append(landmark_pred[:real_size])
#num_of_data*2,num_of_data*4,num_of_data*10
returnnp.concatenate(cls_prob_list,axis=0),np.concatenate(bbox_pred_list,axis=0),np.concatenate(landmark_pred_list,axis=0)
sys.path.append("../")
fromtrain_models.mtcnn_configimportconfig
fromdetection.nmsimportpy_nms
classmtcnndetector(object):
def__init__(self,
detectors,
min_face_size=20,
stride=2,
threshold=[0.6,0.7,0.7],
scale_factor=0.79,
#scale_factor=0.709,#change
slide_window=false):
self.pnet_detector=detectors[0]
self.rnet_detector=detectors[1]
self.onet_detector=detectors[2]
self.min_face_size=min_face_size
self.stride=stride
self.thresh=threshold
self.scale_factor=scale_factor
self.slide_window=slide_window
defconvert_to_square(self,bbox):
"""
convertbboxtosquare
parameters:
----------
bbox:numpyarray,shapenx5
inputbbox
returns:
-------
squarebbox
"""
square_bbox=bbox.copy()
h=bbox[:,3]-bbox[:,1]+1
w=bbox[:,2]-bbox[:,0]+1
max_side=np.maximum(h,w)
square_bbox[:,0]=bbox[:,0]+w*0.5-max_side*0.5
square_bbox[:,1]=bbox[:,1]+h*0.5-max_side*0.5
square_bbox[:,2]=square_bbox[:,0]+max_side-1
square_bbox[:,3]=square_bbox[:,1]+max_side-1
returnsquare_bbox
defcalibrate_box(self,bbox,reg):
"""
calibratebboxes
parameters:
----------
bbox:numpyarray,shapenx5
inputbboxes
reg:numpyarray,shapenx4
bboxesadjustment
returns:
-------
bboxesafterrefinement
"""
inputimagearray
dets:numpyarray
detectionresultsofrnet
returns:
-------
boxes:numpyarray
detectedboxesbeforecalibration
boxes_c:numpyarray
boxesaftercalibration
"""
h,w,c=im.shape
dets=self.convert_to_square(dets)
dets[:,0:4]=np.round(dets[:,0:4])
[dy,edy,dx,edx,y,ey,x,ex,tmpw,tmph]=self.pad(dets,w,h)
num_boxes=dets.shape[0]
cropped_ims=np.zeros((num_boxes,48,48,3),dtype=np.float32)
foriinrange(num_boxes):
tmp=np.zeros((tmph[i],tmpw[i],3),dtype=np.uint8)
tmp[dy[i]:edy[i]+1,dx[i]:edx[i]+1,:]=im[y[i]:ey[i]+1,x[i]:ex[i]+1,:]
cropped_ims[i,:,:,:]=(cv2.resize(tmp,(48,48))-127.5)/128
cls_scores,reg,landmark=self.onet_detector.predict(cropped_ims)
#probbelongstoface
cls_scores=cls_scores[:,1]
keep_inds=np.where(cls_scores>self.thresh[2])[0]
iflen(keep_inds)>0:
#pickoutfilteredbox
boxes=dets[keep_inds]
boxes[:,4]=cls_scores[keep_inds]
reg=reg[keep_inds]
landmark=landmark[keep_inds]
else:
returnnone,none,none
#width
w=boxes[:,2]-boxes[:,0]+1
#height
h=boxes[:,3]-boxes[:,1]+1
landmark[:,0::2]=(np.tile(w,(5,1))*landmark[:,0::2].t+np.tile(boxes[:,0],(5,1))-1).t
landmark[:,1::2]=(np.tile(h,(5,1))*landmark[:,1::2].t+np.tile(boxes[:,1],(5,1))-1).t
boxes_c=self.calibrate_box(boxes,reg)
boxes=boxes[py_nms(boxes,0.6,"minimum")]
keep=py_nms(boxes_c,0.6,"minimum")
boxes_c=boxes_c[keep]
landmark=landmark[keep]
returnboxes,boxes_c,landmark
#useforvideo
defdetect(self,img):
"""detectfaceoverimage
"""
boxes=none
t=time.time()
#pnet
t1=0
ifself.pnet_detector:
boxes,boxes_c,_=self.detect_pnet(img)
ifboxes_cisnone:
returnnp.array([]),np.array([])
t1=time.time()-t
t=time.time()
#rnet
t2=0
ifself.rnet_detector:
boxes,boxes_c,_=self.detect_rnet(img,boxes_c)
ifboxes_cisnone:
returnnp.array([]),np.array([])
t2=time.time()-t
t=time.time()
#onet
t3=0
ifself.onet_detector:
boxes,boxes_c,landmark=self.detect_onet(img,boxes_c)
ifboxes_cisnone:
returnnp.array([]),np.array([])
t3=time.time()-t
t=time.time()
#print(
#"timecost"+'{:.3f}'.format(t1+t2+t3)+'pnet{:.3f}rnet{:.3f}onet{:.3f}'.format(t1,t2,
#t3))
returnboxes_c,landmark
defdetect_face(self,test_data):
all_boxes=[]#saveeachimage'sbboxes
landmarks=[]
batch_idx=0
sum_time=0
t1_sum=0
t2_sum=0
t3_sum=0
num_of_img=test_data.size
empty_array=np.array([])
#test_dataisiter_
s_time=time.time()
fordatabatchintest_data:
#databatch(imagereturned)
batch_idx+=1
ifbatch_idx%100==0:
c_time=(time.time()-s_time)/100
print("%doutof%dimagesdone"%(batch_idx,test_data.size))
print('%fsecondsforeachimage'%c_time)
s_time=time.time()
im=databatch
#pnet
ifself.pnet_detector:
st=time.time()
#ignorelandmark
boxes,boxes_c,landmark=self.detect_pnet(im)
t1=time.time()-st
sum_time+=t1
t1_sum+=t1
ifboxes_cisnone:
print("boxes_cisnone...")
all_boxes.append(empty_array)
#payattention
landmarks.append(empty_array)
continue
#print(all_boxes)
#rnet
ifself.rnet_detector:
t=time.time()
#ignorelandmark
boxes,boxes_c,landmark=self.detect_rnet(im,boxes_c)
t2=time.time()-t
sum_time+=t2
t2_sum+=t2
ifboxes_cisnone:
all_boxes.append(empty_array)
landmarks.append(empty_array)
continue
#onet
ifself.onet_detector:
t=time.time()
boxes,boxes_c,landmark=self.detect_onet(im,boxes_c)
t3=time.time()-t
sum_time+=t3
t3_sum+=t3
ifboxes_cisnone:
all_boxes.append(empty_array)
landmarks.append(empty_array)
continue
all_boxes.append(boxes_c)
landmark=[1]
landmarks.append(landmark)
print('numofimages',num_of_img)
print("timecostinaverage"+
'{:.3f}'.format(sum_time/num_of_img)+
'pnet{:.3f}rnet{:.3f}onet{:.3f}'.format(t1_sum/num_of_img,t2_sum/num_of_img,t3_sum/num_of_img))
#num_of_data*9,num_of_data*10
print('boxeslength:',len(all_boxes))
returnall_boxes,landmarks
defdetect_single_image(self,im):
all_boxes=[]#saveeachimage'sbboxes
landmarks=[]
#sum_time=0
t1=0
ifself.pnet_detector:
#t=time.time()
#ignorelandmark
boxes,boxes_c,landmark=self.detect_pnet(im)
#t1=time.time()-t
#sum_time+=t1
ifboxes_cisnone:
print("boxes_cisnone...")
all_boxes.append(np.array([]))
#payattention
landmarks.append(np.array([]))
#rnet
ifboxes_cisnone:
print('boxes_cisnoneafterpnet')
t2=0
forlandmarkinlandmarks[count]:
foriinrange(len(landmark)//2):
cv2.circle(image,(int(landmark[2*i]),int(int(landmark[2*i+1]))),3,(0,0,255))
”'
count=count+1
#cv2.imwrite("result_landmark/%d.png"%(count),image)
cv2.imshow("lala",image)
cv2.waitkey(0)
”'
fordataintest_data:
printtype(data)
forbboxinall_boxes[0]:
printbbox
print(int(bbox[0]),int(bbox[1]))
cv2.rectangle(data,(int(bbox[0]),int(bbox[1])),(int(bbox[2]),int(bbox[3])),(0,0,255))
#printdata
cv2.imshow("lala",data)
cv2.waitkey(0);
本申请中光照归一化系统代码为:
fromskimageimportdata,exposure,img_as_float
importmatplotlib.pyplotasplt
image=img_as_float(data.moon())
gam1=exposure.adjust_gamma(image,2)#调暗
gam2=exposure.adjust_gamma(image,0.5)#调亮
plt.figure('adjust_gamma',figsize=(8,8))
plt.subplot(131)
plt.title('originimage')
plt.imshow(image,plt.cm.gray)
plt.axis('off')
plt.subplot(132)
plt.title('gamma=2')
plt.imshow(gam1,plt.cm.gray)
plt.axis('off')
plt.subplot(133)
plt.title('gamma=0.5')
plt.imshow(gam2,plt.cm.gray)
plt.axis('off')
plt.show();
本申请中数据增强系统代码为:
importos
frompilimportimage,imagefilter
importrandom
defmodify_file_path(file_path,middle_name):
(filepath,tempfilename)=os.path.split(file_path)
(filename,extension)=os.path.splitext(tempfilename)
filename=filename+'_'+middle_name+extension
file_path=os.path.join(filepath,filename)
returnfile_path
#水平翻转
defhorizontalflip(file_abs_path):
middle_name='hor'
new_file_path=modify_file_path(file_abs_path,middle_name)
img=image.open(file_abs_path).convert('rgb')
img.transpose(image.flip_left_right).save(new_file_path)
returnnew_file_path
#垂直翻转
defverticalflip(file_abs_path):
middle_name='ver'
new_file_path=modify_file_path(file_abs_path,middle_name)
img=image.open(file_abs_path).convert('rgb')
img.transpose(image.flip_top_bottom).save(new_file_path)
returnnew_file_path
#随机抠图
defrandcrop(file_abs_path):
i_randint=random.randint(1,10)
middle_name='randcrop_%d'%(i_randint)
new_file_path=modify_file_path(file_abs_path,middle_name)
img=image.open(file_abs_path).convert('rgb')
width,height=img.size
#print(width,height)
ratio=0.88#0.8--0.9之间的一个数字
left=int(width*(1-ratio)*random.random())#左上角点的横坐标
top=int(height*(1-ratio)*random.random())#左上角点的纵坐标
crop_img=(left,top,left+width*ratio,top+height*ratio)
im_rcrops=img.crop(crop_img)
im_rcrops.save(new_file_path)
returnnew_file_path;
本申请中模型训练中网络结构的backbone是inceptionresnetv2,并使用大数据集casia-webface作为模型的预训练数据集,网络具体定义如下:
本申请中训练超参数设定中训练目标函数(loss)有多多种可供选择,模型同时采用了考虑类内距离和类间距离的tripleloss作为目标函数;迭代500epoch,batch_size设为128;人脸图片默认尺寸224*224;经过'adagrad','adadelta','adam','rmsprop','mom'等多种优化算法比较后选择了'adagrad'作为最终优化算法对参数进行迭代优化;设置动态学习了,初始值0.1,没100epoch衰减为原来的0.1倍;此外还有shuffle、random_seed等设定,详见如下训练代码片段(超参数设定部分):
本申请中不采用inception_resnet_v2默认的softmax作为最终分类器,而是使用人脸图像经模型特征提取后得到的数字特征训练svm分类器,从结果来看svm分类器的表现效果要优于softmax。2.4.2小节中介绍了如何训练模型,训练好模型后即可使用该模型对人脸照片进行特征提取,此处选用softmax层前面的全连接层(full_connection)的输入作为特征值,到此每张人脸照片都映射成了一个1024维的特征向量,然后根据训练集中的1024维向量及其标签训练svm分类器,训练代码如下:
svm=cv2.ml.svm_create()#ml机器学习模块svm_create()创建
#属性设置
svm.settype(cv2.ml.svm_c_svc)#svmtype
svm.setkernel(cv2.ml.svm_linear)#line,线性
svm.setc(0.01)
#开始训练
result=svm.train(data,cv2.ml.row_sample,label)
训练完成后即获得svm分类器模型,用测试及中样本的1024维代码作为输入,svm模型即可给出预测的该样本的标签(抑郁/正常);
本申请中图像预处理后将其输入特征提取模型,获得n*1024(n为数据增强的倍数,默认为10)维特征矩阵后输入svm分类器后得到n*1的标签预测矩阵,经投票后得到最终预测结果。测试代码片段见下:
实施例一
一种基于计算机视觉的抑郁症检测与识别系统,包括人脸采集模块,所述人脸采集模块电性连接有后台处理系统,所述后台处理系统电性链接有信息输出模块;
人脸采集模块为摄像头,后台处理系统包括有人脸识别模块,所述人脸识别模块电性连接有对比分析模块,对比分析模块双向电性连接有数据库模块;
该基于计算机视觉的抑郁症检测与识别系统的使用方法,其使用方法为:
步骤一、收集大量抑郁症和非抑郁症人员人脸图像数据,对数据进行标注,并进行人脸检测、关键点检测、人脸矫正、光照归一化和数据增强预处理操作,并以预处理后的数据集对抑郁症识别模型进行微调训练,通过较多次数迭代后获得一个准确率高且鲁棒性高的识别模型;
步骤二、实际测试过程中,首先获取被试者人脸图像数据,经过与训练阶段相同的预处理后对测试数据进行再次增强,增强后数据一次输入识别模型后得到识别结果;
通过设置后台处理系统,在对抑郁症筛查过程中,具有检测速度快和在大人口基数情况下,在保证识别效率的同时也兼顾了较高的识别准确率的效果;
通过设置人脸采集模块,在使用时,数据采集端提供一张被试人人脸图像即可完成识别,完全是非接触式的,传统识别方法大多需要辅以多种专业检测设备,从而具有为抑郁症识别工作节省大量人力、物力和财力成本的效果;
通过设置人脸采集模块,在使用时,实现用户的随时随地接入访问,操作方便且个人隐私受到严格保护,减轻被试人的心理负担,使其能够及时正确地面对抑郁症问题,从而具有对抑郁症进行尽早发现、尽早就诊和尽早治疗的效果。
本系统在使用过程中充分利用移动互联网的优势,在单人测试模式中,被试人通过微信小程序端上传个人照片数据至识别模块服务端,经在线识别后实时将识别结果反馈至被试人微信小程序端,被试人通过查看测试报告来了解自己当前抑郁倾向指数,并根据结果决定是否要需要去专业心理咨询机构或医院进行确认;且在单人测试模式下数据采集端依托几乎人人都有的移动设备,使用者也无需额外设备支持,不产生成本,测试报告实时给出,无需长时间等待或二次登录查询。
实施例二
一种基于计算机视觉的抑郁症检测与识别系统,包括人脸采集模块,所述人脸采集模块电性连接有后台处理系统,所述后台处理系统电性链接有信息输出模块;
人脸采集模块为摄像头,后台处理系统包括有人脸识别模块,所述人脸识别模块电性连接有对比分析模块,对比分析模块双向电性连接有数据库模块;
该基于计算机视觉的抑郁症检测与识别系统的使用方法,其使用方法为:
步骤一、收集大量抑郁症和非抑郁症人员人脸图像数据,对数据进行标注,并进行人脸检测、关键点检测、人脸矫正、光照归一化和数据增强预处理操作,并以预处理后的数据集对抑郁症识别模型进行微调训练,通过较多次数迭代后获得一个准确率高且鲁棒性高的识别模型;
步骤二、实际测试过程中,首先获取被试者人脸图像数据,经过与训练阶段相同的预处理后对测试数据进行再次增强,增强后数据一次输入识别模型后得到识别结果;
通过设置后台处理系统,在对抑郁症筛查过程中,具有检测速度快和在大人口基数情况下,在保证识别效率的同时也兼顾了较高的识别准确率的效果;
通过设置人脸采集模块,在使用时,数据采集端提供一张被试人人脸图像即可完成识别,完全是非接触式的,传统识别方法大多需要辅以多种专业检测设备,从而具有为抑郁症识别工作节省大量人力、物力和财力成本的效果;
通过设置人脸采集模块,在使用时,实现用户的随时随地接入访问,操作方便且个人隐私受到严格保护,减轻被试人的心理负担,使其能够及时正确地面对抑郁症问题,从而具有对抑郁症进行尽早发现、尽早就诊和尽早治疗的效果。
本系统使用时充分利用移动互联网的优势,在批量测试模型下,可在指定测试场地提前部署网络摄像头,开始测试后,被试人群无需自行做任何操作,只有从摄像头覆盖范围内正常通过即可,网络摄像头将实时采集的人脸图像数据上传至识别模块服务端,服务端实时进行识别,并在设定的时间间隔内完成个体去重及报告汇总后给出测试人数、测试时间、及每个个体的具体测试报告等。
本系统的数据采集端基于移动互联网,批量测试模式下数据采集摄像头部署方便且无需被试群参与部署,不给被试人群增加任何成本,且总体成本可控,测试报告一次性给出,保证了被试人群个人隐私的安全性。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!