基于听觉的盲人辅助感知头戴式装置
1.本实用新型涉及的是一种导航设备领域的技术,具体是一种基于听觉的盲人辅助感知头戴式装置。
背景技术:
2.现有的盲人避障技术多采用语音提示的方法提醒盲人,这需要人脑进一步对文字进行加工处理,不够直观,并且用文字同时传达过多信息容易产生混淆。
技术实现要素:
3.上本实用新型针对现有技术存在的述不足,提出一种基于听觉的盲人辅助感知头戴式装置,利用声音模拟,以增强现实的方法直观帮助盲人避障。
4.本实用新型是通过以下技术方案实现的:
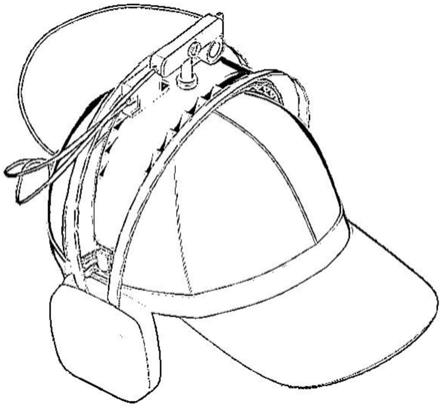
5.本实用新型涉及一种基于听觉的盲人辅助感知头戴式装置,包括:头戴固定结构、深度相机、多声道耳机、温度传感器、处理器和卫星导航器,其中:深度相机位于头戴固定结构的上方,耳机位于头戴固定结构的两侧,温度传感器和卫星导航器位于头戴固定结构与深度相机之间,处理器位于头戴固定结构的后侧并分别与深度相机、耳机、卫星导航器和温度传感器相连。
6.所述的处理器包括:依次相连的图像处理器、温度采集器、语音识别器、视觉听觉转化器和声音输出器,其中:图像处理器接收深度相机采集的深度信息并从中识别出物体的种类、方位、距离和尺寸;温度采集器通过温度传感器采集物体温度信息并传输至视觉听觉转化器;语音识别器获取并识别盲人发出的指令;视觉听觉转化器将物体的种类、方位、距离和尺寸转换为对应的不同音色、频率、相位差和强度的声音信息并传输至声音输出器,声音输出器根据障碍物方位、距离和大小对应分配至不同声道并通过耳机的相应声道播放。
7.所述的图像处理器,采用但不限于低时延高精度的神经网络实现物体的种类、方位、距离和尺寸的识别。
8.所述的语音识别器,识别切换普通避障模式或导航模式的指令以及识别导航模式下的目的地指令。
9.所述的声音信息包括:模拟障碍物声音、高温和低温警告、道路识别和指引和生物与非生物信息识别。
10.所述的处理器中的传输,可以采用高级语言编程,例如:python和matlab,其中:音频的传输采用数据流非阻塞的方式。
11.所述的转换包括:障碍物种类识别与音色匹配、障碍物与盲人距离与声音强度匹配、障碍物大小与声源数目匹配、动态障碍物与声音变化规律匹配。
12.所述的分配是指:通过声音输出器生成最终输出的音频矩阵y,该音频矩阵y包括针对物体的矩阵y
o
和强化边缘的矩阵y
e
组成。,即为y=y
o
+y
e
,其中:针对物体的矩阵采用精
确到像素的方式逼近面声源发声以更充分的利用深度信息,生成的音频矩阵对于每一个物体都带有物体形状维度的立体声信息,再通过多声道耳机声道维度的立体声信息提供给用户更丰富的体验;强化边缘的矩阵通过对边缘声音信息进行强化得到。
13.针对物体的矩阵其中,n为声道的数量,每一个声道的音频向量m为本帧检测到的物体的数目,β(θ) 为方向角函数,衰减矩阵元素a为归一化因子,距离矩阵元素d
ijk
=||xyz[i,k,:]
‑ꢀ
h[j,k,:]||2其中i=1,2...n,j=1,2,...m,k=1,2,...k,||
·
||为矩阵的l2范数,矩阵d精确到一个像素,音频序列y的长度t
la
st、f
s
分别为音频持续时间和音频采样率,表示下取整,对于音频序列的点列延迟矩阵相对距离矩阵d
rel
=d
‑
min(d,1), min(d,1)为d矩阵在每行方向上的最小值,v为当前环境下的声速。
[0014]
当需要产生的音频矩阵为y∈r
l
×
n
,其中:n为声道的数量,深度相机和彩色相机返回的物体位置矩阵k为一个物体在图像中占据的最大的像素数量,即轮廓所包含的像素数目,xyz矩阵的精度是每个物体包含的每一个像素点的坐标。建模的声道位置矩阵矩阵生成距离矩阵d∈r
n
×
m
×
k
,r为实数,由距离矩阵根据声压衰减经验公式,r为实数,由距离矩阵根据声压衰减经验公式得到由于衰减引起的衰减矩阵,其中q为考虑点声源在室内位置的指向性因子; r为测点离开声源的距离,环境常数为室内平均吸音系数;s为室内总表面积;由于本问题中的通过声道之间的相位差提供方位信息,所以在处理相位时只关心距离之差,因此将距离矩阵d转化为相对距离矩阵,显然经过处理后得到的d
rel
每列有一个元素为0,对应于定位时的基准声道。基于相对距离矩阵,得到对于音频序列的点列延迟矩阵,由点列延迟矩阵delay和对应的声源序列y。
[0015]
所述的强化边缘,是指将物体的边缘视为线性声源,通过计算获得其声音到达两耳时的综合声场,该算法可以采用如下步骤:将检测到的边缘端点的像素坐标由相机内参矩阵映射到相机坐标,结合深度信息得到实际坐标,此即真实世界的边缘线,再由自由声场中的声压衰减公式积分得到该边缘线声源的声压函数,由此得出距离矩阵,从而生成强化边缘的矩阵y
e
。具体可以使用霍夫变换进行边缘检测,即通过在一个参数空间中进行投票程序在特定类型的形状内找到候选对象的不完美实例,在该参数空间中,通过计算累加器空间中的局部最大值得到候选对象,该累加器空间由霍夫变换算法构建得到。
[0016]
所述的霍夫变换是从黑白图像中检测直线(线段),能容忍特征边界描述中的间隙,并且相对不受图像噪声的影响,具体为:
[0017]
①
设检测到的边缘的端点的像素坐标分别为x
a
,x
b
,由相机内参矩阵其中f
x
=f/dx,f
y
=f/dy,f为焦距,(u0,v0)是图像坐标系原点在像素坐标系中的坐标,dx和 dy分别为每个像素在图像平面x和y方向上的物理尺寸;将像素坐标映
射为相机坐标x
a
,x
b
,乘以深度相机得到的深度z后便可以得到真实世界中的坐标,此即为一条真实世界中的边缘线;
[0018]
②
针对此边缘线,由自由声场中的声压衰减公式积分得到该边缘线声源的声压函数:其中:d为观测点距离该边缘线声源中心线的距离,θ
a
,θ
b
为观测点与a,b间的夹角,从而产生强化边缘的矩阵y
e
。
[0019]
技术效果
[0020]
本实用新型整体解决现有技术能够测得障碍物方位但不能分辨障碍物具体种类的不足,无法测得物体大小与距离的不足,同时,现有技术只能对静态物体进行测量,无法判断动态物体的运动状态。与现有技术相比,本实用新型测量盲人面前障碍物的大小与距离,并且将其对应声音的频率与强度传递给盲人,让盲人能够直观地感受到障碍物的物理状态。本实用新型具有针对动态障碍物的测量器,能够通过声音的变化将动态障碍物的运动状态传递给盲人,帮助盲人避开动态障碍物。
附图说明
[0021]
图1为本实施例的斜视图;
[0022]
图2为本实施例的正视图;
[0023]
图3为本实施例的后视图
[0024]
图中:头戴固定结构1、深度相机2、耳机3、温度传感器4、处理器5、电源6、gps 7;
[0025]
图4为普通避障模式下设备工作流程图;
[0026]
图5为耳机声道分布图;
[0027]
图6为具体实施例音频可视化结果图。
具体实施方式
[0028]
如图1和图2所示,本实施例包括:头戴固定结构1、深度相机2、耳机3、温度传感器4、处理器5、电源6和卫星导航器7,其中:深度相机2位于头戴固定结构1的上方,耳机3位于头戴固定结构1的两侧,温度传感器4和卫星导航器7位于深度相机2和耳机3之间,处理器5和电源6相连且位于头戴固定结构1的后侧并分别与深度相机2、耳机3、温度传感器4和卫星导航器7相连。
[0029]
所述的深度相机2为realsense
tm depth camera d435i相机。
[0030]
所述的耳机3为物理7.1声道耳机,如razertiamat 7.1
v2
。
[0031]
所述的卫星导航器为gps。
[0032]
所述的处理器5包括:依次相连的图像处理器、温度采集器、语音识别器、视觉听觉转化器和声音输出器,其中:图像处理器接收深度信息并识别深度图片中的轮廓得到物体信息和温度采集器采集到的物体温度信息传输至视觉听觉转化器;语音识别器识别盲人发出的指令;视觉听觉转化器将物体信息对应相应的声音音色、频率,以及不同声道声音的相位差和强度传输至声音输出器;声音输出器将声音信息传输至耳机3的相应声道。
[0033]
所述的物体信息包括:种类、方位、距离和尺寸。
[0034]
所述的声音信息包括:模拟障碍物声音、高温和低温警告、道路识别和指引和生物
与非生物信息识别。
[0035]
所述的视觉听觉转换器根据障碍物种类识别与音色匹配、障碍物与盲人距离与声音强度匹配、障碍物大小与声源个数匹配、动态障碍物与声音变化规律匹配,即用合成模拟的声音来表示物体的种类,比如木质类物体如桌椅等,使用较钝的木质音色;金属制物品,使用较亮的金属音色;对人已经产生固有印象的对象,如人,使用脚步声表示;电脑,使用敲击键盘的声音表示。物体与盲人的距离和声音的强度符合线性关系,离盲人越近,发出的声音强度越强。一个物体对应的声源数目取决于物体的大小分布,对于像水杯,手机,电脑之类的小物品,采用一个中心声源,而对于像桌子,床,门之类的大物体,采用边界和中心多点声源。对于动态障碍物,应用多普勒效应,物体运动的速率用声音的频率变化来表示,物体靠近盲人,声音频率变高且靠近速度越快频率越高,物体远离盲人,声音频率变低且远离速度越块频率越低。
[0036]
所述的声音输出器根据障碍物方位、距离、大小和/或温度,对应不同声道输出,该声音输出器包括:多声道耳机共有8个声道,其中:一个为中置声道,左右两侧各有前置、侧环绕和后置环绕共6个声道,以及一个低音声道;当模拟物体处于不同方位时不同声道接收到的声音的相位差、强度差,将得到的对应关系应用到不同方位模拟声源中。例如:当温度传感器测量到高于65℃的物体时,对盲人发出高温警告;当测量到低于0℃的物体时,对盲人发出低温警告;对于温度在25~45℃之间的动态物体,将被视为生命体,并以特殊的声音传递给盲人。
[0037]
所述的语音识别器在待机请款下识别切换普通避障模式和导航模式的指令,在导航模式下识别盲人输入目的地的指令。
[0038]
所述的普通避障模式是指:通过头戴固定结构1确定使用者与深度相机2的相对位置,基于深度相机2对于物体方位信息的分辨能力,将其采集到的视觉信息,以及温度传感器4所采集到的温度信息,经处理器5处理后转化为声音信息,并传输到物理7.1声道耳机中,利用物理7.1声道耳机对于三维空间声音的高还原度,将声音传递给盲人,通过分辨声音的音色、强度、频率信息来判断障碍物的类别,具体方位和距离,从而达到避障的效果。
[0039]
所述的导航模式是指:盲人发出目的地指令,处理器5中的语音识别器识别目的地并传输给卫星导航器7,卫星导航器接收指令后规划路线并传递给处理器,处理器的声音输出器通过耳机模拟目标路线的道路声音,并传递给盲人,实现导航效果。
[0040]
经过具体实际实验:在普通避障模式下,对于室内环境,戴上装置的盲人能够通过提示声音解房间的结构,如墙壁、门窗等,同时知晓房间内的布局,如桌椅、电视、电脑等,以及房内细节,如水杯、手机的方位等;对于室外环境,装置能够提示盲人车道线、树木的位置,尤其对于动态障碍物,如汽车、自行车、行人等,装置能够提示盲人他们的速度和来向,帮助盲人避障行走。
[0041]
实际实施场景示例:通过深度相机所拍摄的实景图片识别出种类与尺寸,同时通过深度图像得到障碍物与盲人的距离。将所得到的障碍物的信息,通过上述算法计算,向耳机传输所需声音,将声音可视化后如图6所示,纵坐标对应声音的幅值,横坐标对应发声点数,其中:
②④
为图中两个人所对应输出的声音,
①③⑤
分别为电视,椅子和鼠标所对应输出的声音,
⑥
为上述五个物体混合输出的声音。
[0042]
与现有技术相比,本实用新型测量盲人面前障碍物的大小与距离,并且将其对应
声音的频率与强度传递给盲人,让盲人能够直观地感受到障碍物的状态。本实用新型具有针对动态障碍物的测量器,能够通过声音的变化将动态障碍物的运动状态传递给盲人,帮助盲人避开动态障碍物。此外,本实用新型还增加温度测量器,能够对盲人发出低温或高温警告;增加生命体与非生命体的区分的功能,帮助盲人更好得认识面前的环境,增加一层保护措施。本实用新型增加导航模式,盲人选择上述普通避障模式或导航模式,导航模式下,盲人通过语音指令输入目的地,装置模拟目标路线的道路声音指引盲人,实现导航功能。并且器之间的串联使用多线程编程,采取纯python和python+matlab混合编程两种方式,产生音频时采用数据流非阻塞式编程的方式,结合低时延高精度的神经网络进行目标识别,使得用户在得到低延时,高精度,多信息的丰富体验。
[0043]
上述具体实施可由本领域技术人员在不背离本实用新型原理和宗旨的前提下以不同的方式对其进行局部调整,本实用新型的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本实用新型之约束。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1