基于神经网络和自然对话的阿尔兹海默症风险预估方法
1.本发明涉及人工智能识别、语言学分析领域,更具体地,涉及一种基于神经网络和自然对话的阿尔兹海默症风险预估方法。
背景技术:
2.阿尔兹海默症是一种起病隐匿的进行性发展的神经系统退行性疾病。年龄每增加五岁,阿尔兹海默症的患病率约增加一倍。随着人口的老龄化,阿尔兹海默症的发病率逐年上升,严重危害老年人的身心健康和生活质量,给患者及家人造成了深重的痛苦,也给家庭和社会带来负担,成为严重的社会问题。
3.但与此同时,阿尔兹海默症的潜伏期极长,且病因迄今未明,目前也没有确定的技术手段可以完全治愈该疾病。因此,阿尔兹海默症的预测成了控制该疾病的关键手段。
4.目前,针对阿尔兹海默症的预测方法主要有神经影像学检查、相关基因的检查预测等,但这些预测方法普遍检查周期长、工程量大而且可能会对患者造成严重的生理及心理负担,在大规模应用上具有一定的难度。
5.为减轻患者检查的生理及心里负担,进一步考虑低侵入性的手段。中国专利“cn113951834a基于视觉transformer算法的阿尔兹海默症分类预测方法”通过对阿尔兹海默症患者的核磁共振成像的图像样本进行ac-pc矫正等预处理,进而通过训练好的卷积神经网络模型进行分类预测,实现了对阿尔兹海默症的分类预测,但其算法存在手动提取特征带来的主观性问题。
6.中国专利“cn113935330a基于语音的疾病预警方法、装置、设备及存储介质”,通过对收集的目标语音数据进行切片、编码、转换,实现对语义的提取,并通过统计学方法实现对早期的阿尔兹海默症潜在患者的筛查,但通过统计学方法进行处理,需要大量的实验样本,成本较大。
技术实现要素:
7.为解决背景技术提出的问题,如针对手动提取特征可能带来的主观性问题和统计方法的高成本问题,本发明提出了一种基于神经网络和自然对话的阿尔兹海默症风险预估方法。
8.为实现上述目的,本发明的技术方案如下;
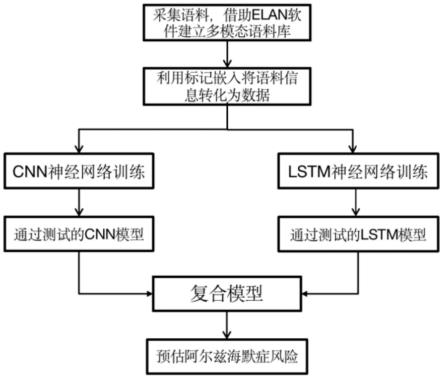
9.本发明基于神经网络和自然对话的阿尔兹海默症风险预估方法,包括采集阿尔兹海默症测试者的自由表达语料,使用语言处理软件elan对语料进行转写、切分和标注;利用目前通用的语音、图像识别文字转化系统和标记嵌入(token embedding)将文本内容转化为数据并建立多模态语料库;利用卷积神经网络(cnn)模型与长短期记忆神经网络(lstm)模型用于文本分析,作为预估阿尔兹海默症的数据。
10.上述基于神经网络和自然对话的阿尔兹海默症风险预估方法具体包括以下步骤:
11.s1.采集至少20名阿尔兹海默症测试者10分钟的有效自由表达语料,利用标记嵌
入(token embedding)将文本内容转化为数据;
12.s2.根据s1中的数据制成数据集,进行预处理及归一化得到特征数据集,将其按照3:1随机分配成训练数据集、测试数据集;
13.其中特征数据集规模为e个的一维张量,e为整数,表示语义、语法、顺序、句法等语言标志物和语言模式;
14.s3.根据数据集规模和输出要求构建cnn神经网络模型,应用s2中的训练数据集进行训练进一步应用测试数据集对此模型进行测试检验;
15.s4.将s1中的数据进行随机处理,得到含有时间序列的训练样本数据集、测试样本数据集,其中,数据集规模为f个二维张量,其中f为整数,表示包含有时间序列的语义、语法、顺序、句法等语言标志物和语言模式;
16.s5.根据数据集规模和输出要求构建lstm神经网络模型,应用s4中的训练样本数据集进行训练,进一步应用测试样本数据集对此模型进行测试检验;
17.s6.将通过步骤s3中的cnn神经网络模型处理的输出值及通过步骤s5中的lstm神经网络模型处理的输出值并列组成矩阵,作为输入值,进行一层全连接层处理,通过两层隐藏层,输出最终结果以one-hot形式表达,作为预估阿尔兹海默症的数据,辅助医生对阿尔兹海默症的诊断。
18.上述基于神经网络和自然对话的阿尔兹海默症风险预估方法的步骤s1中所述阿尔兹海默症测试者的要求是:老年和老年前期的人群,主要为60-65岁的老年群体,能够进行语言表达,身体状况基本良好,测试者男女基本比例为1:1。
19.另外所述采集到的有效自由表达语料,先利用目前通用的语音、图像识别文字转化系统转化得到多个包含语料信息的语言文本文档,再应用token embedding方法将文本内容转化为数据。
20.所述应用token embedding方法将文本内容转化为数据即应用token embedding方法对语料信息进行特征提取,得到语言文本的矩阵,具体为包括:
21.s11.依据采集到的语料信息确定文本中的句子最大长度,对于文本中长度不同的文本句子进行长裁短补,生成词典;
22.s12.将词典的词做个词频排列,得到规模为n
×
1的单词组合,针对每个单词进行数值赋值,赋值保证每个单词对应不同的数字;
23.s13.将每个数字转化成规模为1
×
m浮点数组合,从而得到一个n
×
m形式的矩阵;将每个维度作为一个特征,其相应的强烈程度决定了小数的大小、正负;
24.s14.将句子的每个词对应的数字的行取出,按顺序转置为列,得到语言文本的矩阵。
25.上述基于神经网络和自然对话的阿尔兹海默症风险预估方法的步骤s3中所述构建cnn神经网络模型是:针对于步骤s2得到的数据及集规模构建多个卷积层,具体参数如下:卷积核为32个随机的m
×
1矩阵,步长为1,不进行插空卷积,通过如上卷积层得到32个二维张量,通过对每个张量进行比较得到每个的全局最大值,以全局最大值为依据设计全连接层的分配权重,将卷积后得到的二维张量通过全连接层和两层隐藏层处理,得到one-hot形式的输出结果。
26.上述基于神经网络和自然对话的阿尔兹海默症风险预估方法的步骤s3中所述训
练cnn神经网络模型是将步骤s2中的训练数据集放入构建好的cnn神经网络模型中进行训练,通过梯度下降法不断调整权重和偏置,使代价函数最终波动在误差允许范围内,此时即生成了适宜的cnn神经网络模型。
27.上述基于神经网络和自然对话的阿尔兹海默症风险预估方法的步骤s3中所述测试是将测试数据集放入生成的cnn神经网络模型中进行检测,检验测试效果;若测试得到的误差,在训练误差周围波动,即测试效果良好;反之,则进一步调整cnn神经网络模型的结构或参数。
28.上述基于神经网络和自然对话的阿尔兹海默症风险预估方法的步骤s5中构建lstm神经网络模型:对步骤s1中数据进行归一化如下处理:
[0029][0030]
其中,是第i个平均值,σi是第i个标准差,形成训练样本数据集。
[0031]
上述基于神经网络和自然对话的阿尔兹海默症风险预估方法的步骤s5中训练lstm神经网络模型:将步骤s4中的训练样本数据集放入构建的lstm神经网络模型中进行训练,最终生成lstm神经网络模型;再将测试数据集放入训练lstm神经网络模型中进行检测,若测试得到的误差,在训练误差周围波动,即测试效果良好;反之,则调整lstm神经网络模型的结构或参数。
[0032]
目前多数语音识别系统采用词袋方法将文字转化为数字,即在信息检索中,假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,认为文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。此方法虽然对文字内容的长度不限制,但由于无法判别文本单词顺序,难以进行文本分析。故为考虑阿尔兹海默症患者语言的连贯、语法、停顿等影响因素,本发明采用token embedding,并基于此建立多模态语料库语料库,实现对阿尔兹海默症风险的初步预估。
[0033]
与现有技术相比,本发明基于神经网络和自然对话的阿尔兹海默症风险预估方法具有如下优点及有益效果:
[0034]
1、本发明基于神经网络和自然对话的阿尔兹海默症风险预估方法在自然对话过程的语音信息的基础上,经过多模态语料库和算法处理,对录音者进行阿尔兹海默症的定量风险评估。
[0035]
2、本发明采用token embedding,并基于此建立多模态语料库,考虑了阿尔兹海默症患者语言的连贯、语法、停顿等影响因素,实现对阿尔兹海默症风险的初步预估。
[0036]
3、本发明相对于传统的阿尔兹海默症预测方法而言,可减轻患者检查时的身体和心理负担,缩短检查周期,降低实验成本,有利于大规模推广。
附图说明
[0037]
图1为本发明基于神经网络和自然对话的阿尔兹海默症风险预估方法流程图;
[0038]
图2为token embedding流程示意图;
[0039]
图3为cnn网络结构图;
[0040]
图4为lstm网络结构图;
[0041]
图5为cnn-lstm结合图;
[0042]
图6为lstm具体神经元图解;
[0043]
图7为dnn网络结构。
具体实施方式
[0044]
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本技术的实施例及实施例中的特征可以相互组合。
[0045]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
[0046]
在本说明书中,对某些术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、步骤、方法或者特点可以在任一个或多个实施例或示例中以合适的方式结合。
[0047]
下面结合图1至图7和实施例对本发明的技术方案做进一步的说明。
[0048]
图1为本发明基于神经网络和自然对话的阿尔兹海默症风险预估方法流程图。
[0049]
图2为token embedding流程示意图;通过语音、图像识别文字转化系统得到的一个语言文本文档,对文本中长度不同的句子进行长裁短补,生成有词频排列的词典,将词典中的每个词转化成一串小数来表示,如在附图2中将like等词转化成了一串小数。
[0050]
图3为cnn网络结构图;数据通过卷积层提取输入信号中的隐藏特征,再经过池化层压缩输入的特征,减小计算量,接着通过全连接层输出t个元素,再用softmax函数作为激活函数,把每一个元素的范围都限定在0~1内,且所有的元素之和为1,从而得到cnn神经网络模型,经过训练数据集的不断训练,根据训练误差判定模型构建是否合格,如果合格则用于测试集测试,如果不合格,则重新构建网络模型,重新进行cnn神经网络模型训练。
[0051]
图4为lstm网络结构图;将数据归一化得到样本数据,让样本数据经过lstm模块中的遗忘门、输入门、输出门、细胞门进行训练,再经过全连接层通过softmax函数进行激活,得到相应的lstm神经网络模型,训练误差如果合格,则模型建立成功,不合格则重新构建网络模型进行训练。
[0052]
图5为cnn-lstm结合图;对于经过从cnn神经网络模型中输出的结果与从lstm神经网络模型中输出的结果,经过一层全连接层dnn处理,再用softmax函数激活,输出最终结果作为预测阿尔兹海默症的依据。
[0053]
图6为lstm具体神经元图解;lstm具体神经元公式和图解:
[0054]it
=σ(w
xi
x
t
+w
hiht-1
+w
cict-1
+bi)
[0055]ft
=σ(w
xf
x
t
+w
hfht-1
+w
cfct-1
+bf)
[0056]ct
=f
tct-1
+i
t
tanh(w
xc
x
t
+w
hcht
+bc)
[0057]ot
=σ(w
xo
x
t
+w
hoht-1
+w
coct
+bo)
[0058]ht
=o
t
tanh(c
t
)
[0059]
图7为dnn网络结构。
[0060]
实施例1
[0061]
本实施例基于神经网络和自然对话的阿尔兹海默症风险预估方法,主要包括以下步骤:
[0062]
s1.采集至少20名阿尔兹海默症测试者10分钟的有效自由表达语料,利用标记嵌入(token embedding)将文本内容转化为数据。
[0063]
s2.根据s1中的数据制成数据集,进行预处理及归一化得到特征数据集,将其按照3:1随机分配成训练数据集、测试数据集;
[0064]
其中特征数据集规模为e个的一维张量,e为整数,表示语义、语法、顺序、句法等语言标志物和语言模式。
[0065]
s3.根据数据集规模和输出要求,构建cnn神经网络模型,作为阿尔兹海默症语料数据训练网络模型;并运用s2中的训练数据集进行训练,生成训练cnn神经网络模型,再应用测试数据集对此模型进行测试检验。
[0066]
s4.将s1中的数据进行随机处理,得到含有时间序列的训练样本数据集、测试样本数据集,其中,数据集规模为f个二维张量,其中f为整数,表示包含有时间序列的语义、语法、顺序、句法等语言标志物和语言模式。
[0067]
s5.根据数据集规模和输出要求,构建lstm神经网络模型;并运用s4中的训练样本数据集进行训练,生成训练lstm神经网络模型,再应用测试样本数据集对此模型进行测试检验。
[0068]
构建lstm神经网络模型:对步骤s1中数据进行归一化如下处理:
[0069][0070]
其中,是第i个平均值,σi是第i个标准差,形成训练样本数据集。
[0071]
进而进行lstm神经网络模型处理:
[0072]it
=σ(w
xi
x
t
+w
hiht-1
+w
cict-1
+bi)
[0073]ft
=σ(w
xf
x
t
+w
hfht-1
+w
cfct-1
+bf)
[0074]ct
=f
tct-1
+i
t
tanh(w
xc
x
t
+w
hcht
+bc),
[0075]
σ是sigmoid函数,w
xi
、w
hi
、w
ci
分别遗忘门、输出门、细胞门与输出门之间的权重;w
xf
、w
hf
、w
cf
分别是输入门、输出门、细胞门与遗忘门之间的权重,wxc、whc是记忆细胞和其他门之间的权重,c
t-1
是上一个细胞状态;bi、bf、bc分别为两个门及记忆细胞的偏置。
[0076]
具体的,单个lstm模块的输出ht由tanh函数确定,具体公式为:
[0077]ot
=σ(w
xo
x
t
+w
hoht-1
+w
coct
+bo)
[0078]ht
=o
t
tanh(c
t
)
[0079]
式中,w
xo
为遗忘门和输出门的权重,w
ho
为输出门和输出门的权重,w
co
为细胞门和输出门的权重,bo是输出门和记忆细胞的偏置,下标o代指i、f、c。
[0080]
得到的输出通过全连接层dnn处理(如图7),并由softmax函数激活,将向量进行相同维度的压缩,且每个元素之和为1,范围均在(0,1),最后输出结果
[0081]
s6.将通过步骤s3中的cnn神经网络模型处理的输出值及通过步骤s5中的lstm神经网络模型处理的输出值并列组成矩阵,作为输入值,进行一层全连接层处理,通过两层隐藏层,输出最终结果以one-hot形式表达,作为预估阿尔兹海默症的数据,辅助医生对阿尔兹海默症的诊断。
[0082]
实施例2
[0083]
在本实施例中,更具体提供一种基于神经网络和自然对话的阿尔兹海默症风险预估方法,其具体包括以下步骤:
[0084]
s1:走访广东某老人院,在得到受访老年人允许的情况下,通过摄像机完整记录不少于10分钟的现场即席自然会话。在通过elan将多模态语料进行转写、切分、标注后,结合利用语音、图像识别文字转化系统得到的文本内容,采取token embedding方法提取语义、语法、顺序、节律及停顿等语言标志物和语言模式,进一步应用矩阵保存数据。
[0085]
s2:根据s1中的数据制成数据集,进行预处理及归一化得到特征数据集,归一化处理之后矩阵的数据范围比较接近,对于网络误差降低较有帮助;归一化之后数据结构和存储量大小不变。再将其按照3:1随机分配成训练数据集,测试数据集。
[0086]
s3:根据输入矩阵规模和输出要求,构建cnn神经网络模型,作为阿尔兹海默症语料数据训练网络模型。
[0087]
将s2中的训练数据集放入s3中的cnn神经网络模型中进行训练,通过梯度下降法不断调整权重和偏置,当最终误差达到特征数目的1/10000或者训练次数超过10000次,停止训练。对训练后的网络利用训练样本集进行正确率交叉检验,在训练样本随机抽取20%的数据进行交叉验证,训练集正确率越接近100%,理论分类效果越好。若未达到90%,则修改网络参数重新训练。
[0088]
将测试数据集放入生成的cnn网络模型中进行检测,检验测试效果。若测试得到的误差,在训练误差周围波动,即测试效果良好;反之,则需要进一步调整cnn神经网络模型的结构或参数,可相应地增加卷积层的数目,调整卷积核的大小、步长等。
[0089]
s4:进一步考虑录音时的时间序列,利用embedding方法提取将时间、语义、语法、顺序、节律、停顿等语言标志物和语言模式,进一步应用矩阵保存数据。将得到的数据进行预处理及归一化得到特征数据集,再将其按照3:1随机分配成训练数据集,测试数据集。
[0090]
s5:根据数据集规模和输出要求构建多层lstm神经网络模型作为阿尔兹海默症风险预估的训练模型。
[0091]
将s4中的训练样本数据集放入多层lstm神经网络模型中进行训练,当最终误差达到特征数目的1/10000或者训练次数超过1000次,停止训练。对训练后的网络利用训练样本集进行正确率交叉检验,在训练样本随机抽取20%的数据进行交叉验证,训练集正确率越接近100%,理论分类效果越好。若未达到90%,则修改网络参数重新训练。最终生成多层lstm神经网络模型。
[0092]
将测试数据集放入lstm神经网络模型中进行检测。若测试得到的误差,在训练误差周围波动,即测试效果良好;反之,则需要进一步调整lstm神经网络模型的结构或参数,可相应地增加lstm的时间步长,修改的lstm单元的公式等。
[0093]
s6:把s3输出值及s5输出值作为输入值,进行一层全连接层处理,通过两层隐藏层,输出one-hot形式的最终结果,作为预估阿尔兹海默症风险的定量数据,辅助医生对阿尔兹海默症的诊断。
[0094]
实施例3
[0095]
本实施例在实施例1的基础上,应用token embedding方法对语料信息进行特征提取,得到语言文本的矩阵,具体为包括:
[0096]
应用token embedding方法对语料信息进行特征提取。依据采集到的信息确定文本中的句子最大长度,对于文本中长度不同的文本句子进行长裁短补,生成词典,将所有文档的词做个词频排列,得到规模为n
×
1的单词组合,针对每个单词进行数值赋值,赋值仅需要保证每个单词对应不同的数字即可,进一步将每个数字转化成规模为1
×
m浮点数组合,从而得到一个n
×
m形式的矩阵。将每个维度作为一个特征,其相应的强烈程度决定了小数的大小、正负。将句子的每个词对应的数字的行取出,按顺序转置为列,得到语言文本的矩阵表示,如图2所示。
[0097]
此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
[0098]
值得说明的是,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1