一种基于深度强化学习的足式机器人运动控制方法及系统与流程
本发明属于足式机器人运动控制技术领域,尤其涉及一种基于深度强化学习的足式机器人运动控制方法及系统。
背景技术:
足式机器人具有多关节、强非线性、多种运动模式的特点,同时,地外星体非结构化环境下地表材质、刚度、地形等信息缺失或不精确,都给足式机器人的运动控制,特别是兼顾快速性和稳定性的高性能运动控制,带来了巨大的挑战。经典的基于模型的运动控制方法对模型精度依赖强,设计过程复杂,难以处理高维对象,并且不能充分发挥机器人的移动能力,特别是对模型不确定性和环境未知性的适应能力非常有限,难以应对地外天体表面的未知非结构化环境。
技术实现要素:
本发明解决的技术问题是:克服现有技术的不足,提供了一种基于深度强化学习的足式机器人运动控制方法及系统,实现足式机器人的运动控制,在不需要对象动力学模型和环境模型,并且不需要有标注的训练样本的前提下,让机器人主动在环境中进行探索,根据环境给予的反馈对自身行为进行评估,根据评估结果不断改善自身运动控制策略,最终从大量的失败中积累经验,逐步学习得到适用于当前训练环境的最优运动策略,实现在未知环境下的高效平稳移动。
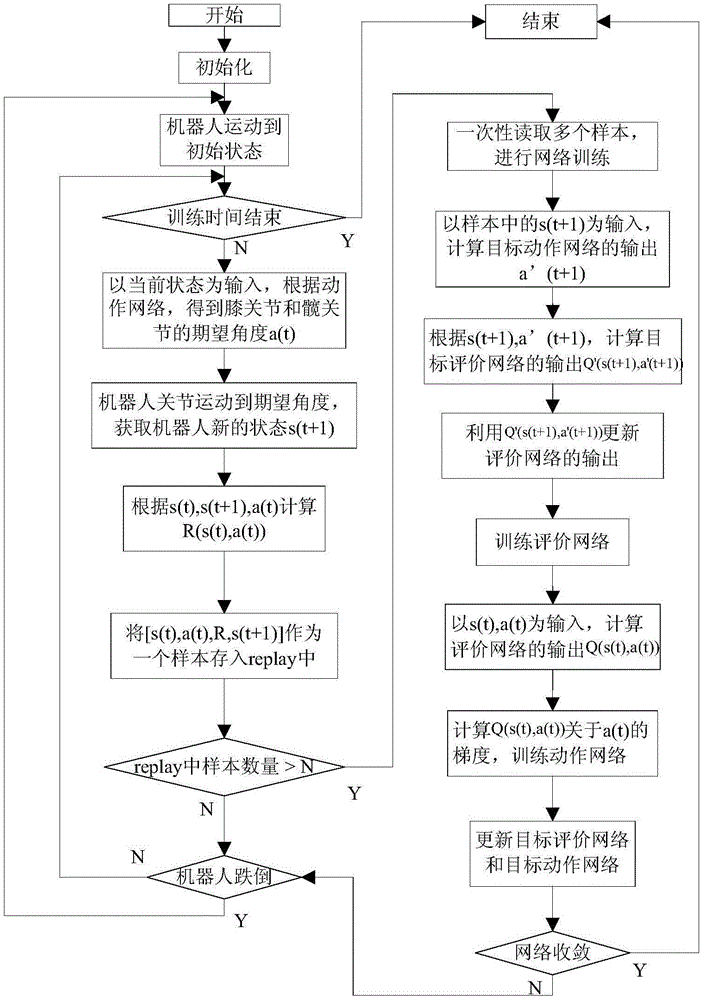
本发明目的通过以下技术方案予以实现:根据本发明的一个方面,提供了一种基于深度强化学习的足式机器人运动控制方法,所述方法包括如下步骤:(1)在webots仿真环境中构建足式机器人3d模型;其中,足式机器人3d模型包括本体和四个腿,其中,四个腿分别与本体相连接,四个腿均位于本体下部;每个腿包括小腿、膝关节、大腿和髋关节;其中,小腿通过膝关节与大腿相连接,大腿通过髋关节与本体相连接;(2)初始化足式机器人3d模型的状态,预设t时刻即时奖励函数r(s(t),a(t))以及累积奖励函数q(s(t),a(t)),其中,s(t)为机器人在t时刻的机器人3d模型的状态,a(t)为机器人3d模型的在t时刻的膝关节和髋关节的期望角度;(3)构建动作网络及目标动作网络;构建评价网络及目标评价网络;(4)在t时刻机器人3d模型的状态s(t)下,通过动作网络生成膝关节和髋关节的期望角度a(t),在t+1时刻使得机器人3d模型的膝关节和髋关节运动至期望角度a(t),此时读取机器人的状态信息s(t+1),计算t+1时刻机器人3d模型运动的即时奖励函数r(t+1),将[s(t),a(t),s(t+1),r(t+1)]作为一个样本存储在replay变量中;(5)重复步骤4,直到搜集了多个样本后,从replay变量中随机选取一定数量的样本,利用目标动作网络生成s(t+1)对应的a’(t+1),以此为输入,再利用目标评价网络得到累积奖励函数q的值q'(s(t+1),a'(t+1));其中,a’(t+1)为t+1时刻的目标动作网络的输出值;(6)利用replay变量中存储的即时奖励函数r(t+1)对累积奖励函数q的值q(s(t),a(t))进行更新;(7)以[s(t),a(t)]为输入,q(s(t),a(t))为输出,构建训练样本,对评价网络进行训练,得到新的评价网络权值θc(t+1);(8)以机器人3d模型的状态s(t)为输入,并根据动作网络得到膝关节和髋关节的期望角度a(t),根据s(t)和a(t)得到步骤7中新的评价网络的输出即累积奖励函数q(s(t),a(t)),并进一步计算q(s(t),a(t))关于a(t)的梯度,基于此梯度对动作网络进行训练,得到新的动作网络权值θa(t+1);(9)根据步骤7中的得到的新的评价网络的权值θc(t+1)更新目标评价网络的权值θct(t+1);根据步骤8中得到的新的动作网络的权值θa(t+1)更新目标动作网络的权值θat(t+1);(10)重复步骤(4)-(9),直至动作网络、目标动作网络、评价网络和目标评价网络收敛;(11)根据足式机器人3d模型的状态,利用步骤10中收敛的动作网络得到足式机器人3d模型的膝关节和髋关节的期望角度,实现足式机器人3d模型的运动控制。
上述基于深度强化学习的足式机器人运动控制方法中,在步骤(2)中,初始化足式机器人3d模型的状态为预设足式机器人3d模型的质心位置、质心速度、姿态、角速度、膝关节和髋关节的初始角度。
上述基于深度强化学习的足式机器人运动控制方法中,在步骤(2)中,即时奖励函数为r(s(t),a(t))=w1×前进速度(t)-w2×姿态偏差(t)-w3×位置偏差(t),其中,w1、w2和w3均为常数。
上述基于深度强化学习的足式机器人运动控制方法中,在步骤(2)中,累积奖励函数为:
上述基于深度强化学习的足式机器人运动控制方法中,在步骤(6)中,即时奖励函数r(t+1)对累积奖励函数q的值q(s(t),a(t))进行更新的公式为:q(s(t),a(t))=r(t+1)+γq'(s(t+1),a(t+1))。
上述基于深度强化学习的足式机器人运动控制方法中,在步骤(9)中,权值θct(t+1)为:θct(t+1)=θc(t+1)τ+θct(t)(1-τ),其中,τ为常数。
上述基于深度强化学习的足式机器人运动控制方法中,在步骤(9)中,权值θat(t+1)为:θat(t+1)=θa(t+1)τ+θat(t)(1-τ),其中,τ为常数。
上述基于深度强化学习的足式机器人运动控制方法中,在步骤(3)中,动作网络及目标动作网络的输入均为步骤2中的机器人3d模型的状态s(t),动作网络的输出为膝关节和髋关节的期望角度a(t),目标动作网络的输出值为a’(t);动作网络的权值为θa(t),目标动作网络的权值为θat(t)。
上述基于深度强化学习的足式机器人运动控制方法中,在步骤(3)中,评价网络及目标评价网络的输入均为步骤2中的机器人3d模型的状态s(t)和膝关节和髋关节的期望角度a(t),评价网络的输出为累积奖励函数q(s(t),a(t));目标评价网络的输出为累积奖励函数q'(s(t),a(t));评价网络的权值为θc(t),目标评价网络的权值为θct(t)。
根据本发明的另一方面,还提供了一种基于深度强化学习的足式机器人运动控制系统,包括:第一模块,用于在webots仿真环境中构建足式机器人3d模型;其中,足式机器人3d模型包括本体和四个腿,其中,四个腿分别与本体相连接,四个腿均位于本体下部;每个腿包括小腿、膝关节、大腿和髋关节;其中,小腿通过膝关节与大腿相连接,大腿通过髋关节与本体相连接;第二模块,用于初始化足式机器人3d模型的状态,预设t时刻即时奖励函数r(s(t),a(t))以及累积奖励函数q(s(t),a(t)),其中,s(t)为机器人在t时刻的机器人3d模型的状态,a(t)为机器人3d模型的在t时刻的膝关节和髋关节的期望角度;第三模块,用于构建动作网络及目标动作网络;构建评价网络及目标评价网络;第四模块,用于在t时刻机器人3d模型的状态s(t)下,通过动作网络生成膝关节和髋关节的期望角度a(t),在t+1时刻使得机器人3d模型的膝关节和髋关节运动至期望角度a(t),此时读取机器人的状态信息s(t+1),计算t+1时刻机器人3d模型运动的即时奖励函数r(t+1),将[s(t),a(t),s(t+1),r(t+1)]作为一个样本存储在replay变量中;第五模块,用于通过第四模块搜集了多个样本后,从replay变量中随机选取一定数量的样本,利用目标动作网络生成s(t+1)对应的a’(t+1),以此为输入,再利用目标评价网络得到累积奖励函数q的值q'(s(t+1),a'(t+1));其中,a’(t+1)为t+1时刻的目标动作网络的输出值;第六模块,用于利用replay变量中存储的即时奖励函数r(t+1)对累积奖励函数q的值q(s(t),a(t))进行更新;第七模块,用于以[s(t),a(t)]为输入,q(s(t),a(t))为输出,构建训练样本,对评价网络进行训练,得到新的评价网络权值θc(t+1);第八模块,用于以机器人3d模型的状态s(t)为输入,并根据动作网络得到膝关节和髋关节的期望角度a(t),根据s(t)和a(t)得到新的评价网络的输出即累积奖励函数q(s(t),a(t)),并进一步计算q(s(t),a(t))关于a(t)的梯度,基于此梯度对动作网络进行训练,得到新的动作网络权值θa(t+1);第九模块,用于得到的新的评价网络的权值θc(t+1)更新目标评价网络的权值θct(t+1);得到的新的动作网络的权值θa(t+1)更新目标动作网络的权值θat(t+1);第十模块,用于将动作网络、目标动作网络、评价网络和目标评价网络收敛;第十一模块,用于根据足式机器人3d模型的状态,利用步骤10中收敛的动作网络得到足式机器人3d模型的膝关节和髋关节的期望角度,实现足式机器人3d模型的运动控制。
本发明与现有技术相比具有如下有益效果:
(1)本发明基于深度确定性策略梯度法,首次实现了足式机器人在未知环境下的平稳快速移动。该方法突破了现有控制方法对对象动力学模型和环境模型的依赖,极大地降低了现有控制器设计中参数调试的工作量,并且能够同时对多种运动模式同步进行运动控制策略的学习和训练,不需要分别设计。更重要的是,由于机器人是在主动地环境探索过程中不断地学习得到最优的运动策略,所以当机器人结构或设计参数改变时,或者地表接触条件变化时,只需要进行短暂的训练,这一智能运动控制方法即可适用于相似对象和相似环境。
(2)本发明所提出的深度确定性策略梯度法,在连续运动空间下,依靠深度神经网络实现策略函数和值函数的建模,通过合理的算法设计和充分的学习训练,能够在连续动作空间中得到最优的控制策略。这一过程是通过机器人自主探索和学习实现的,不需要人为干预,并且前期大量的学习训练可以在webots机器人仿真软件中实现。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1是本发明实施例提供的基于深度强化学习的足式机器人运动控制方法的流程图;
图2是本发明实施例提供的足式机器人的结构示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
图1是本发明实施例提供的基于深度强化学习的足式机器人运动控制方法的流程图。如图1所示,该方法包括如下步骤:
(1)在webots仿真环境中构建足式机器人3d模型,设置环境变量,包括机器人密度、重量、引力系数、地表摩擦力、关节电机参数、控制周期等。足式机器人3d模型包括本体和四个腿,其中,四个腿分别与本体相连接,四个腿均位于本体下方且分别位于左前、左后、右前和右后;每个腿包括小腿、膝关节、大腿和髋关节;其中,小腿通过膝关节与大腿相连接,大腿通过髋关节与本体相连接。
(2)初始化足式机器人3d模型的状态(预设质心位置、质心速度、姿态、角速度、膝关节和髋关节的初始角度),设置t时刻即时奖励函数
r(s(t),a(t))=w1×前进速度(t)-w2×姿态偏差(t)-w3×位置偏差(t)
以及累积奖励函数(状态-动作值函数)
其中s(t)为机器人在t时刻的机器人3d模型的状态,a(t)为机器人3d模型的在t时刻的膝关节和髋关节的期望角度,r(s(t),a(t))为奖励函数,w1、w2和w3均为常数,q(s(t),a(t))为累积奖励函数,γ为常数。
(3)构建动作网络及目标动作网络,动作网络及目标动作网络的输入均为步骤(2)中的机器人3d模型的状态s(t),动作网络的输出为膝关节和髋关节的期望角度a(t),目标动作网络的输出值为a’(t);动作网络的权值为θa(t),目标动作网络的权值为θat(t);
构建评价网络及目标评价网络,评价网络及目标评价网络的输入均为步骤(2)中的机器人3d模型的状态s(t)和膝关节和髋关节的期望角度a(t),评价网络的输出为累积奖励函数q(s(t),a(t));目标评价网络的输出为累积奖励函数q'(s(t),a(t));评价网络的权值为θc(t),目标评价网络的权值为θct(t);
以步骤(2)中的机器人3d模型的状态s(t)作为输入,膝关节和髋关节的期望角度a(t)作为输出,初始化深度神经网络,包括动作网络及目标动作网络;以机器人3d模型的状态s(t)和膝关节和髋关节的期望角度a(t)为输入,累积奖励函数q(s(t),a(t))为输出,初始化深度神经网络,包括评价网络及目标评价网络;
(4)在t时刻机器人3d模型的状态s(t)下,通过动作网络生成膝关节和髋关节的期望角度a(t),在t+1时刻使得机器人3d模型的膝关节和髋关节运动至期望角度a(t),此时读取机器人的状态信息s(t+1),计算t+1时刻机器人3d模型运动的即时奖励函数r(t+1),将[s(t),a(t),s(t+1),r(t+1)]作为一个样本存储在replay变量中。
(5)不断重复步骤(4),直到搜集了多个样本后,从replay变量中随机选取一定数量的样本,利用目标动作网络生成s(t+1)对应的a’(t+1),以此为输入,再利用目标评价网络得到累积奖励函数q的值q'(s(t+1),a'(t+1));其中,a’(t+1)为t+1时刻的目标动作网络的输出值;
(6)利用replay变量中存储的即时奖励函数r(t+1)对累积奖励函数q的值q(s(t),a(t))进行更新
q(s(t),a(t))=r(t+1)+γq'(s(t+1),a(t+1))
(7)以[s(t),a(t)]为输入,q(s(t),a(t))为输出,构建训练样本,对评价网络进行训练,得到新的评价网络权值θc(t+1);
(8)以机器人3d模型的状态s(t)为输入,并根据动作网络得到膝关节和髋关节的期望角度a(t),根据s(t)和a(t)得到步骤(7)中新的评价网络的输出即累积奖励函数q(s(t),a(t)),并进一步计算q(s(t),a(t))关于a(t)的梯度,基于此梯度对动作网络进行训练,得到新的动作网络权值θa(t+1);
(9)根据步骤(7)中的得到的新的评价网络的权值θc(t+1)更新目标评价网络的权值θct(t+1):θct(t+1)=θc(t+1)τ+θct(t)(1-τ);
根据步骤(8)中得到的新的动作网络的权值θa(t+1)更新目标动作网络的权值θat(t+1):θat(t+1)=θa(t+1)τ+θat(t)(1-τ);其中,τ为常数。
通过上述过程,完成目标动作网络和目标评价网络的一次训练。
(10)重复步骤(4)-(9),直至所有的网络(动作网络、目标动作网络、评价网络和目标评价网络)收敛
(11)根据足式机器人3d模型的状态,利用步骤(10)中收敛的动作网络得到足式机器人3d模型的膝关节和髋关节的期望角度,实现足式机器人3d模型的运动控制。
即可实时地根据机器人运动状态得到控制指令,该控制指令能够实现累积奖励q的最大化。
以四足机器人足式运动为例,说明本发明的实施过程。
首先在webots仿真环境下,建立足式机器人3d模型。设定机器人本体坐标系(图2):机器人重心位置为原点,z轴为垂直向上方向,x轴在水平面内指向机器人侧面,y轴在水平面内指向机器人前进方向。设定全局坐标系(图2):水平面上起点为全局坐标系原点,z轴垂直向上,y轴指向北极。俯视机器人,以本体坐标系原点位置为中心,将机器人的四个腿分别命令为左前、右前、左后、右后。每条腿有两个自由度,分别是髋关节h沿x轴转动和膝关节k沿x轴转动。因此,在足式运动下,选取足式机器人3d模型的控制量为:
a=[θhfrθkfrθhflθkflθhbrθkbrθhblθkbl]
其中θ为关节角度,下标h表示髋关节,k表示膝关节,f和b分别为前、后,l和r分别为左、右。
选取机器人的状态量为:
s=[pxpypzvxvyvzθrollθpitchθyawwxwywz]
其中,px和vx分别为全局坐标系下机器人沿x方向位置和速度,θrollθpitchθyaw分别为机器人本体的滚动角(沿本体y轴旋转)、俯仰角(沿本体x轴旋转)和侧滑角(沿本体z轴旋转)。
设置即时奖惩函数为:
r(s(t),a(t))=1000vy(t)-50(|θpitch(t)|+|θroll(t)|+|θyaw(t)|)-
100(|px(t)-pxd(t)|+|py(t)-pyd(t)|+|pz(t)-pzd(t)|)
选取步骤2状态动作值函数中的γ=0.95。
依据步骤3,以s作为网络输入,a为网络输出,建立并初始化动作网络和评价网络,网络含有5个隐层,每个隐层包含500个神经元,神经元的激活函数为relu函数:
φ(a)=max(0,a)
依据步骤4,从webots中获取足式机器人3d模型的状态s(t),输入动作网络,得到a(t),机器人各关节在t+1时刻到达a(t)给出的期望角度,读取当前状态s(t+1),并计算即时奖励r(s(t),a(t))。将s(t),a(t),r(s(t),a(t)),s(t+1)存储于变量replay中。
不断重复步骤4,当replay中样本数量大于1000时,随机选取200个样本,根据步骤5,计算目标动作网络和目标评价网络的输出。并利用目标评价网络的输出,依据步骤6,对累积奖励函数q的值q(s(t),a(t))进行更新。
至此,即可用样本{[s(t),a(t)][q(s(t),a(t))]}对评价网络进行训练。
根据步骤8,更新动作网络的权值θa(t+1)。再根据步骤9,利用动作网络和评价网络,更新目标动作网络和目标评价网络的权值。
至此,一次训练过程完毕。不断重复步骤4-9,在经过约20000次迭代后,网络收敛。
本实施例还提供了一种基于深度强化学习的足式机器人运动控制系统,该系统包括:第一模块,用于在webots仿真环境中构建足式机器人3d模型;其中,足式机器人3d模型包括本体和四个腿,其中,四个腿分别与本体相连接,四个腿均位于本体下部;每个腿包括小腿、膝关节、大腿和髋关节;其中,小腿通过膝关节与大腿相连接,大腿通过髋关节与本体相连接;第二模块,用于初始化足式机器人3d模型的状态,预设t时刻即时奖励函数r(s(t),a(t))以及累积奖励函数q(s(t),a(t)),其中,s(t)为机器人在t时刻的机器人3d模型的状态,a(t)为机器人3d模型的在t时刻的膝关节和髋关节的期望角度;第三模块,用于构建动作网络及目标动作网络;构建评价网络及目标评价网络;第四模块,用于在t时刻机器人3d模型的状态s(t)下,通过动作网络生成膝关节和髋关节的期望角度a(t),在t+1时刻使得机器人3d模型的膝关节和髋关节运动至期望角度a(t),此时读取机器人的状态信息s(t+1),计算t+1时刻机器人3d模型运动的即时奖励函数r(t+1),将[s(t),a(t),s(t+1),r(t+1)]作为一个样本存储在replay变量中;第五模块,用于通过第四模块搜集了多个样本后,从replay变量中随机选取一定数量的样本,利用目标动作网络生成s(t+1)对应的a’(t+1),以此为输入,再利用目标评价网络得到累积奖励函数q的值q'(s(t+1),a'(t+1));其中,a’(t+1)为t+1时刻的目标动作网络的输出值;第六模块,用于利用replay变量中存储的即时奖励函数r(t+1)对累积奖励函数q的值q(s(t),a(t))进行更新;第七模块,用于以[s(t),a(t)]为输入,q(s(t),a(t))为输出,构建训练样本,对评价网络进行训练,得到新的评价网络权值θc(t+1);第八模块,用于以机器人3d模型的状态s(t)为输入,并根据动作网络得到膝关节和髋关节的期望角度a(t),根据s(t)和a(t)得到新的评价网络的输出即累积奖励函数q(s(t),a(t)),并进一步计算q(s(t),a(t))关于a(t)的梯度,基于此梯度对动作网络进行训练,得到新的动作网络权值θa(t+1);第九模块,用于得到的新的评价网络的权值θc(t+1)更新目标评价网络的权值θct(t+1);得到的新的动作网络的权值θa(t+1)更新目标动作网络的权值θat(t+1);第十模块,用于将动作网络、目标动作网络、评价网络和目标评价网络收敛;第十一模块,用于根据足式机器人3d模型的状态,利用步骤10中收敛的动作网络得到足式机器人3d模型的膝关节和髋关节的期望角度,实现足式机器人3d模型的运动控制。
本实施例针对足式机器人这样一种新型移动机构和全新的复合运动模式,基于深度确定性策略梯度法,首次实现了足式机器人在未知环境下的平稳快速移动,得到了一种全新高效的复合移动方式。该方法突破了现有控制方法对对象动力学模型和环境模型的依赖,极大地降低了现有控制器设计中参数调试的工作量,并且能够同时对多种运动模式同步进行运动控制策略的学习和训练,不需要分别设计。更重要的是,由于机器人是在主动地环境探索过程中不断地学习得到最优的运动策略,所以当机器人结构或设计参数改变时,或者地表接触条件变化时,只需要进行短暂的训练,这一智能运动控制方法即可适用于相似对象和相似环境。
本实施例所提出的深度确定性策略梯度法,在连续运动空间下,依靠深度神经网络实现策略函数和值函数的建模,通过合理的算法设计和充分的学习训练,能够在连续动作空间中得到最优的控制策略。这一过程是通过机器人自主探索和学习实现的,不需要人为干预,并且前期大量的学习训练可以在webots机器人仿真软件中实现。
以上所述的实施例只是本发明较优选的具体实施方式,本领域的技术人员在本发明技术方案范围内进行的通常变化和替换都应包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!