基于遗传禁忌搜索算法的机器人运动学参数辨识方法与流程
本发明涉及机器人运动学标定技术领域,具体涉及一种基于遗传禁忌搜索算法的机器人运动学参数辨识方法。
背景技术:
机器人运动学标定通常可分为建模、测量、参数辨识和补偿四个步骤,在实际情况中,机器人末端误差与运动学参数误差的关系是非线性的,但通常基于线性误差模型进行运动学参数辨识,因此会引起辨识的偏差。大多数均忽略参数的二阶误差项,但经过多次迭代可以减小其影响,能够有较高的辨识精度。进行运动学参数辨识最常用的方法为最小二乘法,该方法不需考虑扰动信息,但需要方程的数量大于辨识参数的数量,也就要求测量数据点较多,计算量较大,并且需要设计合理的轨迹,具有一定的局限性;还有的使用遗传算法对运动学参数进行辨识,但是遗传算法容易陷入局部最优;禁忌搜索起初是为了解决组合优化问题而提出,随着应用场景的扩展,后来也应用于连续优化问题中,禁忌搜索算法是一种局部搜索算法,对于每一个可行解,都需要计算出其邻域集,并且要计算出邻域中每个点的适应度值并进行一系列的操作,如果初始解选的不好的话,禁忌搜索算法的计算效率是比较低的。
技术实现要素:
为了克服现有技术存在的缺陷与不足,本发明提供一种基于遗传禁忌搜索算法的机器人运动学参数辨识方法,对机器人运动学误差模型进行辨识,能够在解的全局范围内进行寻优,且能跳出局部最优解,缩短计算时间。
本发明的第二目的在提供一种基于遗传禁忌搜索算法的机器人运动学参数辨识系统。
本发明的第三目的在于提供一种存储介质。
本发明的第四目的在于提供一种计算设备。
为了达到上述目的,本发明采用以下技术方案:
一种基于遗传禁忌搜索算法的机器人运动学参数辨识方法,包括下述步骤:
构建机器人的运动学模型及机器人的误差模型;
设置种群大小,随机产生初始种群;
将机器人末端实际位置和理论位置的x,y,z误差平方和的倒数作为适应度函数,计算种群中每个个体的适应度;
采用适应度函数输出最佳个体作为禁忌搜索算法的初始解;
构建邻域集:按照邻域规则生成邻域环,在邻域环内随机取多个点作为初始解x的邻域集;
将辨识的参数作为机器人运动学参数,利用已知的关节角度求得机器人末端的理论位置,将所有点实际位置和理论位置坐标差平方和的均值作为适应度,根据该适应度,计算邻域集各点的适应度和当前点的适应度;
对邻域集中各点的适应度按从小到大进行排序,取最小适应度的点作为邻域的最佳点,标记为x′;
判断x′的适应度是否小于初始解x的适应度,若不小于则进行禁忌表中禁忌次数判断,若小于则将当前解替换为x′,并且更新禁忌表;
禁忌次数判断:判断x′在禁忌表中的禁忌次数是否大于等于设定值,若大于等于设定值则按照邻域各点适应度排序,取邻域的下一个最优点作为x′;若小于设定值则将当前解替换为x′,并且更新禁忌表;
判断是否已经超出邻域内的最后一个点,若超出则取邻域内所有点的平均值作为x′,若不超出则进行禁忌次数判断;
判断是否达到禁忌搜索的最大迭代次数,若未达到则返回构建邻域集,若达到则输出最佳解和最佳解的适应度。
作为优选的技术方案,所述按照邻域规则生成邻域环,所述邻域规则设置为:通过适应度乘以个体上下界的差向量动态调整邻域半径。
作为优选的技术方案,所述禁忌表的长度设置为5。
作为优选的技术方案,所述计算种群中每个个体的适应度后,还包括二进制编码、进化种群和二进制解码步骤,具体为:
对种群中每个个体进行二进制编码;
设置选择概率、交叉概率和变异概率,先对二进制编码后的染色体进行选择运算,然后对选择后的染色体进行单点交叉运算,然后对交叉后的染色体进行单点按位取反的操作得到进化种群;
判断是否到达最大迭进化次数,未达到最大迭进化次数则计算种群中每个个体的适应度,达到最大迭进化次数则对结果种群中的每个染色体进行二进制解码。
作为优选的技术方案,所述机器人采用六自由度机器人,机器人的运动学模型采用md-h运动学模型。
作为优选的技术方案,所述md-h运动学模型建立关节轴参考坐标系的步骤包括:
确定z轴方向、坐标系原点及x轴方向;
确定z轴方向:关节i处建立的坐标系命名为坐标系i-1,如果关节i是旋转轴关节,z轴方向和关节旋转轴的轴线一致;如果关节i是移动关节,将其移动方向定为z轴轴线方向;
确定坐标系原点及x轴方向:
当相邻两关节轴线zi-1和zi为异面直线时,在两轴线之间有且仅有一条最短公垂线,x轴的方向为最短公垂线从zi-1指向zi的方向,坐标系的原点为z轴和x轴的交点;
当相邻两关节轴线zi-1和zi为平行线时,两轴之间存在多条长度相同的公垂线,选择与前一关节坐标系原点相交的公垂线作为最短公垂线,x轴的方向为最短公垂线从zi-1指向zi的方向,坐标系的原点为z轴和x轴的交点;
当相邻两关节轴线zi-1和zi为相互垂直时,选择两轴所在平面的法线作为公垂线,x轴的方向为公垂线的方向,坐标系原点即为公垂线与两轴的交点;
确定y轴的方向:通过右手定则确定y轴的方向。
作为优选的技术方案,所述md-h运动学模型在经典的d-h模型中每个关节坐标系上增加了一个绕y轴的转动β,当相邻两个关节轴线平行时,用βi取代di,此时di为零;当相邻两个关节轴线不平行时,定义βi为零;
构建相邻关节参考坐标系齐次变换矩阵为:
根据每个关节处的齐次变换矩阵得到机器人的误差模型,表示为:
pg-p=mθδθ+mαδα+maδa+mdδd+mβδβ
δθ=[δθ1,δθ2,…,δθ6]’
δα=[δα1,δα2,…,δα6]’
δa=[δa1,δa2,…,δa6]’
δd=[δd1,δd2,…,δd6]’
δβ=δβ3
其中,c代表cos(),s代表sin(),pg表示机器人末端在激光跟踪仪下建立的基坐标系的实际位置,p表示根据机器人运动学模型和关节角度求得的末端理论位置,mθ、mα、ma、md、mβ分别为δθ、δα、δa、δd、δβ的系数矩阵。
为了到达上述第二目的,本发明采用以下技术方案:
一种基于遗传禁忌搜索算法的机器人运动学参数辨识系统,包括:误差模型构建模块、初始种群构建模块、种群个体适应度计算模块、初始解构建模块、邻域集构建模块、适应度计算模块、排序模块、适应度判断模块、禁忌次数判断模块、邻域范围判断模块和迭代次数判断模块;
所述误差模型构建模块用于构建机器人的运动学模型及机器人的误差模型;
所述初始种群构建模块用于设置种群大小,随机产生初始种群;
所述种群个体适应度计算模块用于将机器人末端实际位置和理论位置的x,y,z误差平方和的倒数作为适应度函数,计算种群中每个个体的适应度;
所述初始解构建模块用于采用适应度函数输出最佳个体作为禁忌搜索算法的初始解;
所述邻域集构建模块用于按照邻域规则生成邻域环,在邻域环内随机取多个点作为初始解x的邻域集;
所述适应度计算模块用于将辨识的参数作为机器人运动学参数,利用已知的关节角度求得机器人末端的理论位置,将所有点实际位置和理论位置坐标差平方和的均值作为适应度,根据该适应度,计算邻域集各点的适应度和当前点的适应度;
所述排序模块用于对邻域集中各点的适应度按从小到大进行排序,取最小适应度的点作为邻域的最佳点,标记为x′;
所述适应度判断模块用于判断x′的适应度是否小于初始解x的适应度,若不小于则进行禁忌表中禁忌次数判断,若小于则将当前解替换为x′,并且更新禁忌表;
所述禁忌次数判断模块用于判断x′在禁忌表中的禁忌次数是否大于等于设定值,若大于等于设定值则按照邻域各点适应度排序,取邻域的下一个最优点作为x′;若小于设定值则将当前解替换为x′,并且更新禁忌表;
所述邻域范围判断模块用于判断是否已经超出邻域内的最后一个点,若超出则取邻域内所有点的平均值作为x′,若不超出则进行禁忌次数判断;
所述迭代次数判断模块用于判断是否达到禁忌搜索的最大迭代次数,若未达到则返回构建邻域集,若达到则输出最佳解和最佳解的适应度。
为了到达上述第三目的,本发明采用以下技术方案:
一种存储介质,存储有程序,所述程序被处理器执行时实现上述基于遗传禁忌搜索算法的机器人运动学参数辨识方法。
为了到达上述第四目的,本发明采用以下技术方案:
一种计算设备,包括处理器和用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现上述基于遗传禁忌搜索算法的机器人运动学参数辨识方法。
本发明与现有技术相比,具有如下优点和有益效果:
(1)本发明利用遗传算法的全局搜索能力和禁忌搜索算法的局部搜索能力,遗传算法得到的最佳解直接输入禁忌搜索算法,使得该技术既具有全局优化能力,又能利用禁忌规则跳出局部最优解,实现模型误差的精确辨识,以此来修正机器人模型的各项参数,提高机器人末端的绝对定位精度。
附图说明
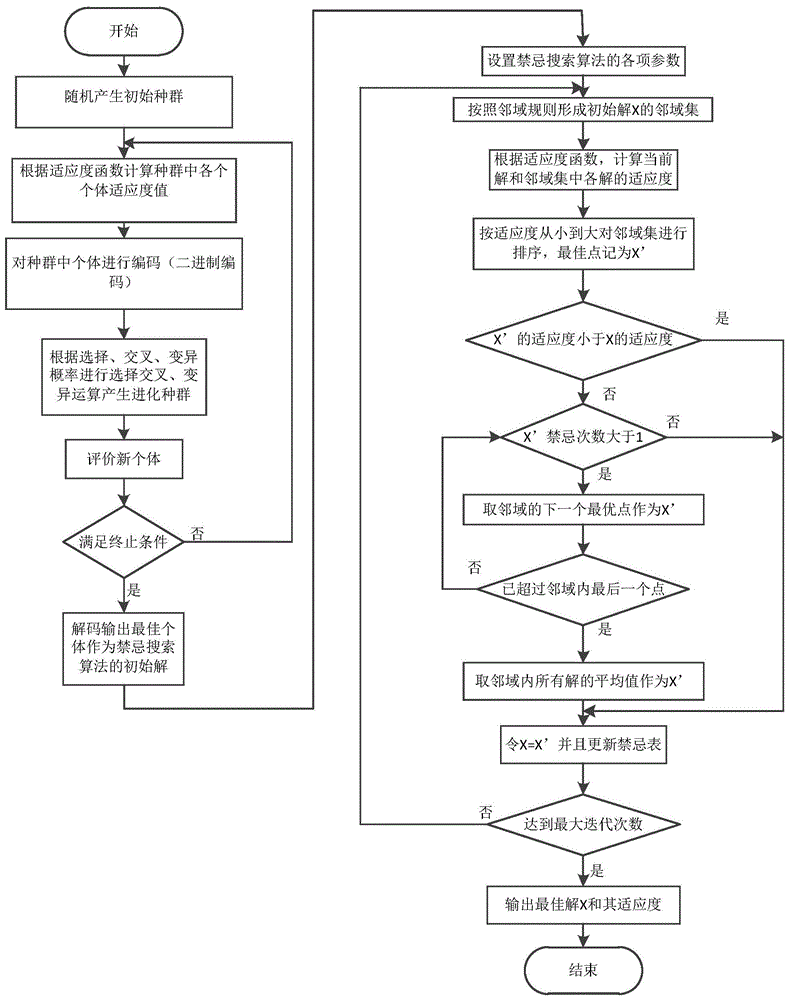
图1为本实施例基于遗传禁忌搜索算法的机器人运动学参数辨识方法流程示意图;
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例
本实施例提供一种基于遗传禁忌搜索算法的机器人运动学参数辨识方法,包括下述步骤:
首先建立六自由度机器人的md-h运动学模型,建立坐标系就是坐标轴方向和原点的选择,d-h模型建立关节轴参考坐标系的方法如下:
(1)z轴方向的确立
关节i处建立的坐标系命名为坐标系i-1,如果关节i是旋转轴关节,z轴方向和关节旋转轴的轴线一致;如果关节i是移动关节,将其移动方向定为z轴轴线方向;
(2)坐标系原点及x轴方向的确立
相邻两关节的轴线可能出现三种几何关系:异面直线、平行线和相互垂直。所以坐标系原点和x轴方向也分三种情况考虑;
当相邻两关节轴线zi-1和zi为异面直线时,在两轴线之间有且仅有一条最短公垂线,x轴的方向就是这条最短公垂线从zi-1指向zi的方向,坐标系的原点就是z轴和x轴的交点。
当相邻两关节轴线zi-1和zi为平行线时,两轴之间存在无数长度相同的公垂线,选择与前一关节坐标系原点相交的公垂线作为最短公垂线,x轴的方向就是这条最短公垂线从zi-1指向zi的方向,坐标系的原点就是z轴和x轴的交点。
当相邻两关节轴线zi-1和zi为相互垂直时,选择两轴所在平面的法线作为公垂线,x轴的方向就是公垂线的方向,坐标系原点即为公垂线与两轴的交点。
y轴的方向通过右手定则来确定。
通过上述方法就建立了关节轴参考坐标系,在关节i-1与关节i之间有4个描述模型的参数:αi、θi、ai和di;αi是扭转角即zi-1轴与zi轴的夹角,θi是关节转角即xi-1轴与xi轴的夹角,ai是连杆长度即zi-1轴与zi轴的公垂线,di是派偏移量表示xi-1轴沿zi轴移动到xi轴的距离。
于是,关节轴i-1参考坐标系到关节轴i参考坐标系的转换可以这样描述:坐标系i-1先绕zi-1轴旋转θi,再沿zi-1轴平移di,然后沿xi-1轴平移ai,最后绕xi-1轴旋转αi。md-h模型在经典的d-h模型中每个关节坐标系上增加了一个绕y轴的转动β,当相邻两个关节轴线平行时,用βi取代di,此时di为零;当相邻两个关节轴线不平行时,定义βi为零。此时相邻关节参考坐标系齐次变换矩阵为:
其中,c代表cos(),s代表sin()。
根据每个关节处的齐次变换矩阵可以的得到机器人的误差模型如下面公式所示:
pg-p=mθδθ+mαδα+maδa+mdδd+mβδβ
pg表示机器人末端在激光跟踪仪下建立的基坐标系的实际位置,p表示根据机器人运动学模型和关节角度求得的末端理论位置,且δθ=[δθ1,δθ2,…,δθ6]’,δα=[δα1,δα2,…,δα6]’,δa=[δa1,δa2,…,δa6]’,δd=[δd1,δd2,…,δd6]’,δβ=δβ3,都是机器人md-h模型的待辨识参数误差,mθ,mα,ma,md,mβ分别为δθ、δα、δa、δd、δβ的系数矩阵,机器人误差模型标定也就是求解δθ、δα、δa、δd、δβ;
其次利用遗传禁忌搜索算法对上面的误差进行参数辨识,如图1所示,下面详细介绍该算法实施步骤:
步骤1:将25项参数误差作为将遗传算法中种群的个体,种群大小设置为50,并随机初始化种群;
步骤2:将机器人末端实际位置和理论位置的x,y,z误差平方和的倒数作为适应度函数,计算种群中每个个体的适应度;
步骤3:对种群中每个个体进行二进制编码;
步骤4:选择概率设为0.5,交叉概率设为0.8,变异概率设为0.1,先对二进制编码后的染色体进行选择运算,这里使用轮盘赌的方式,然后对选择后的染色体进行单点交叉运算,然后对交叉后的染色体进行单点按位取反的操作得到新的种群;
步骤5:判断是否到达最大迭进化次数100,否进入步骤2,是进入步骤6;
步骤6:对结果种群中的每个染色体进行二进制解码,利用适应度函数输出最佳个体作为禁忌搜索算法的初始解;
禁忌搜索算法的初始解对于寻优非常重要,本实施例用遗传算法得到的最优解作为禁忌搜索算法的初始解;禁忌表的长度在禁忌搜索算法体系里至关重要,它可以确定被禁忌个体在禁忌表中停留的时间,本实施例将禁忌表的长度设置为5;邻域设置的规则,本实施例通过适应度乘以个体上下界的差向量动态调整邻域半径;迭代终止规则本实施例使用固定迭代次数,设为200。接下来详细介绍遗传禁忌搜索算法中禁忌搜索算法步骤:
步骤7:按照邻域规则生成邻域环,在邻域环内随机取6个点作为初始解x的邻域集;
步骤8:禁忌搜索算法的适应度函数这样定义,为辨识的参数作为机器人运动学参数,利用已知的关节角度求得机器人末端的理论位置,将所有点实际位置和理论位置坐标差平方和的均值作为适应度,根据该适应度,计算邻域集各点的适应度和当前点的适应度;
步骤9:对邻域集中各点的适应度按从小到大进行排序,取最小适应度的点作为邻域的最佳点,标记为x′;
步骤10:判断x′的适应度是否小于初始解x的适应度,否的话直接转向步骤11,是的话转向步骤14;
步骤11:判断x′在禁忌表中的禁忌次数是否大于等于1,是的话直接转向步骤12,否的话转向步骤14;
步骤12:按照邻域各点适应度排序取邻域的下一个最优点作为x′,判断是否已经超出邻域内的最后一个点,是的话转向步骤13,否的话转向步骤11;
步骤13:取邻域内所有点的平均值作为x′;
步骤14:将当前解替换为x′,即令x=x′,并且更新禁忌表;
更新禁忌表做如下说明:如果禁忌表未满,则直接将本次迭代的最优解添加到禁忌表末尾,禁忌次数加1;如果禁忌表内已经写满,那么随机选取一个己解禁的记录被新的最优解替换,每当更新一次禁忌表,所有禁忌次数大于0的个体的被禁忌次数将依次减1位,当禁忌次数为0时,表示该个体被解禁;
步骤15:判断是否达到禁忌搜索的最大迭代次数,否的话进入步骤7,是的话进入步骤16;
步骤16:输出最佳解x和x的适应度,结束算法流程。
完成了以上十六个步骤就完成了机器人运动学误差模型辨识,将机器人原有理论运动学参数减去该误差得到修正的运动学参数,将修正的运动学参数传入机器人的控制系统能够提高机器人末端的绝对定位精度。
本实施例利用遗传算法的全局搜索能力和禁忌搜索算法的局部搜索能力,遗传算法得到的最佳解直接输入禁忌搜索算法,使得该技术既具有全局优化能力,又能利用禁忌规则跳出局部最优解,实现模型误差的精确辨识,以此来修正机器人模型的各项参数,提高机器人末端的绝对定位精度。
本实施例还提供一种基于遗传禁忌搜索算法的机器人运动学参数辨识系统,包括:误差模型构建模块、初始种群构建模块、种群个体适应度计算模块、初始解构建模块、邻域集构建模块、适应度计算模块、排序模块、适应度判断模块、禁忌次数判断模块、邻域范围判断模块和迭代次数判断模块;
所述误差模型构建模块用于构建机器人的运动学模型及机器人的误差模型;
所述初始种群构建模块用于设置种群大小,随机产生初始种群;
所述种群个体适应度计算模块用于将机器人末端实际位置和理论位置的x,y,z误差平方和的倒数作为适应度函数,计算种群中每个个体的适应度;
所述初始解构建模块用于采用适应度函数输出最佳个体作为禁忌搜索算法的初始解;
所述邻域集构建模块用于按照邻域规则生成邻域环,在邻域环内随机取多个点作为初始解x的邻域集;
所述适应度计算模块用于将辨识的参数作为机器人运动学参数,利用已知的关节角度求得机器人末端的理论位置,将所有点实际位置和理论位置坐标差平方和的均值作为适应度,根据该适应度,计算邻域集各点的适应度和当前点的适应度;
所述排序模块用于对邻域集中各点的适应度按从小到大进行排序,取最小适应度的点作为邻域的最佳点,标记为x′;
所述适应度判断模块用于判断x′的适应度是否小于初始解x的适应度,若不小于则进行禁忌表中禁忌次数判断,若小于则将当前解替换为x′,并且更新禁忌表;
所述禁忌次数判断模块用于判断x′在禁忌表中的禁忌次数是否大于等于设定值,若大于等于设定值则按照邻域各点适应度排序,取邻域的下一个最优点作为x′;若小于设定值则将当前解替换为x′,并且更新禁忌表;
所述邻域范围判断模块用于判断是否已经超出邻域内的最后一个点,若超出则取邻域内所有点的平均值作为x′,若不超出则进行禁忌次数判断;
所述迭代次数判断模块用于判断是否达到禁忌搜索的最大迭代次数,若未达到则返回构建邻域集,若达到则输出最佳解和最佳解的适应度。
本实施例还提供一种存储介质,存储介质可以是rom、ram、磁盘、光盘等储存介质,该存储介质存储有一个或多个程序,所述程序被处理器执行时,实现上述基于遗传禁忌搜索算法的机器人运动学参数辨识方法。
本实施例还提供一种计算设备,所述的计算设备可以是台式电脑、笔记本电脑、智能手机、pda手持终端、平板电脑或其他具有显示功能的终端设备,该计算设备包括该计算设备包括处理器和存储器,存储器存储有一个或多个程序,处理器执行存储器存储的程序时,实现上述基于遗传禁忌搜索算法的机器人运动学参数辨识方法。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!