一种基于云处理功能的语言学习方法及学习机
1.本发明属于语言学习方法领域,具体涉及为一种基于云处理功能的语言学习方法及学习机。
背景技术:
2.随着国际化的进程,我们在工作和生活当中与外国友人、企业等团体的接触越来越多,在接触的过程中,语言交流成为阻碍我们的第一个制约要素。对于大部分中国人来说,仅仅学过英语一门外语,而多元的世界除了英语之外还有很多其他语系,要求一个普通的中国人来说,掌握这么多种语言是不切实际的。
3.同时随着互联网、云计算的发展,给出我们一个新的解决语言问题的思路。就是与云处理器相结合,临时帮助我们解决语言不通带来的交流问题。
4.云计算能够提供可靠的基础软硬件、丰富的网络资源、低成本的构建和管理能力,是信息技术发展和服务模式创新的集中体现。在云计算模式下,软件、硬件、平台等信息技术资源以服务的方式提供给使用者,有效的降低客户端的配置要求,在低配置的情况下实现高处理能力。
技术实现要素:
5.本发明要解决的技术问题是:克服现有技术的不足,提供一种基于云处理功能的语言学习方法及学习机,本发明将语言信息进行录入然后传递到云处理器上,通过云数据库或人工的帮助,与他人进行交流或获悉该语言信息的内容。
6.本发明解决现有技术存在的问题所采用的技术方案是:
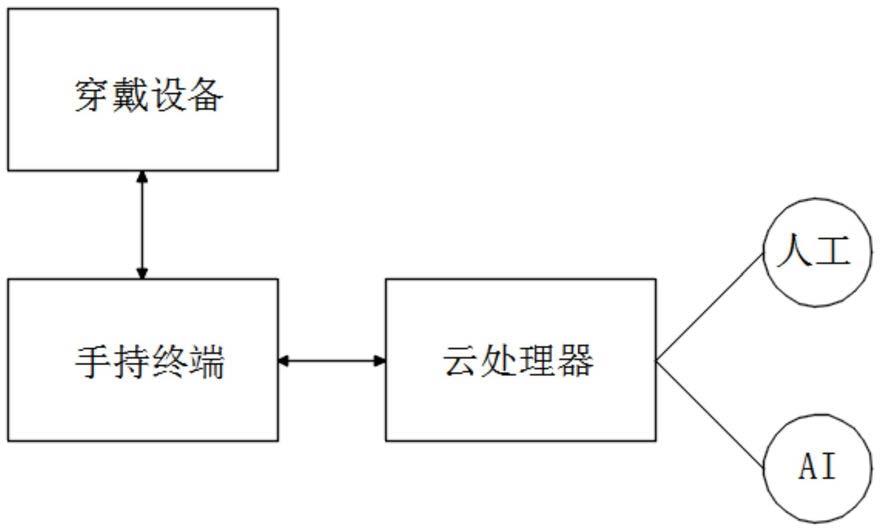
7.一种学习机,包括客服端,所述的客户端包括图像录入模块、语音录入模块、图像处理模块、声音处理模块、通信模块以及电源模块。
8.图像录入模块:拍摄有含有文字的照片;
9.语音录入模块:录入声音信息;
10.图像处理模块:对图像录入模块拍摄的照片进行处理,提取其内部的文字信息;
11.声音处理模块:对语音录入模块录入的声音进行降噪处理;
12.通信模块:将照片信息以及声音信息转换为数字信号,传递给云处理器;
13.电源模块:为客服端的工作提供所需电源。
14.优选的,客户端包括穿戴设备以及手持终端。
15.穿戴设备包括眼镜,眼镜的镜框内部设有电源模块以及通信模块,通信模块与手持终端进行无线连接。
16.镜框前端中间位置设有摄像头,镜腿靠近镜框的外侧设有麦克风,镜腿挂在耳朵位置的内侧设有扬声器。
17.手持终端内部包括图像处理模块、声音处理模块、通信模块、电源模块以及穿戴设备控制模块。
18.穿戴设备控制模块控制穿戴设备开关以及音量大小。
19.优选的,所述的手持终端还包括语言选择模块,所述的语言选择模块可选择需要翻译的语言类型。
20.优选的,所述的声音处理模块包括降噪模块、转化模块、特征提取模块、噪音压制模块,
21.所述的降噪模块使用降噪自动编码对实时获取的用户声音或已存储的其它声音进行噪声抑制,获得降噪后的声音信息;
22.所述的转化模块将声音信息进行拉普拉斯变换,得到拉普拉斯频谱信息;
23.所述的特征提取模块将得到的拉普拉斯频谱信息进行二维傅里叶变换,得到拉普拉斯变换声音信息数据波数谱特征;
24.所述的噪音压制模块根据所述拉普拉斯变换声音信息数据波数谱,截取3~6个时间切片的滤波因子组合成滤波团;将时间切片的信息数据进行二维傅里叶变换,得到滤波信息数据波数谱,利用滤波信息数据波数谱对整段录音的声音数据波数谱进行环境噪音压制。
25.优选的,所述的图像处理模块包括ccd/cmos传感模块、图像识别模块、文字识别模块以及图文修正模块。
26.所述的图文修正模块包括字体计算单元、字体修正选择单元。
27.一种基于云处理功能的语言学习方法,包括一下步骤:
28.s1、当与外国友人进行交流时,麦克风对其声音进行采集,然后将音频传递给手持终端,手持终端上的声音处理模块对音频进行处理,处理后传递给云服务器;
29.s2、云服务器对接受到的音频进行分析处理,分析处理方法为:先对其与数据库中的语种进行匹配,找到与其对应的语系,然后进行单词拆分,逐词进行翻译,然后根据语法组成一个连贯的语句,或找到对应的语系后,直接对音频进行翻译;
30.s3、云服务器将翻译好的语言通过手持终端传递给穿戴设备,然后通过扬声器播放,使穿戴人理解外语的意思;
31.s4、当穿戴人需要讲话时,在手持终端上选择需要翻译成的语种,然后讲话,在重复s1至s3步骤,最终扬声器播放相对应的外语声音。
32.一种基于云处理功能的语言学习方法,包括一下步骤:
33.s1、当需要了解文字类外语信息时,摄像头对文字信息进行拍照,然后将图片传递给手持终端,手持终端上的图像处理模块对图片进行处理,处理后传递给云服务器;
34.s2、云服务器对接受到的图片信息进行分析处理,分析处理方法为:接收待识别的图像后二值化处理图像,根据像素的邻域块的像素值分布确定所述像素位置上的二值化阈值;并基于图像切割字符,水平投影所述图像以确定每一行的上界限和下界限,基于所述上界限和下界限行切割以获得行,垂直投影行以获得字符的左右边界,基于所述左右边界切割得到单个单词;
35.文字识别模块读取云端数据库中的待识别单词的单词模型,切割的单词与单词模型对比得到识别结果,当云端数据库没有待识别文字的单词模型时,返回图像切割字符并重新切割,直至可在云端数据库中检索对比得到识别结果;然后将识别结果输出;
36.s3、结果输出可采用两种方法:文字输出或音频输出,文字输出则在手持终端的显
示屏上显示,音频输出则通过扬声器进行播报。
37.与现有技术相比,本发明所具有的有益效果:
38.(1)通过眼镜作为信息收集端,方便快捷。
39.(2)依托云处理技术,降低客户端的配置,通过对外语的在线实时翻译来进行语言学习与交流。
附图说明
40.下面结合附图和实施例对本发明进一步说明。
41.图1为本发明一种基于云处理功能的语言学习方法及学习机系统图,
42.图2为本发明一种基于云处理功能的语言学习方法及学习机的穿戴设备图,
43.图3本发明一种基于云处理功能的语言学习方法及学习机手持终端系统图。
44.图中:1-眼镜、2-摄像头、3-麦克风、4-扬声器。
具体实施方式
45.附图为该一种基于云处理功能的语言学习方法及学习机的最佳实施例,下面结合附图对本发明进一步详细的说明。
46.一种学习机,包括客服端,所述的客户端包括图像录入模块、语音录入模块、图像处理模块、声音处理模块、通信模块以及电源模块。
47.图像录入模块:拍摄有含有文字的照片;
48.语音录入模块:录入声音信息;
49.图像处理模块:对图像录入模块拍摄的照片进行处理,提取其内部的文字信息;
50.声音处理模块:对语音录入模块录入的声音进行降噪处理;
51.通信模块:将照片信息以及声音信息转换为数字信号,传递给云处理器;
52.电源模块:为客服端的工作提供所需电源。
53.所述的声音处理模块包括降噪模块、转化模块、特征提取模块、噪音压制模块。
54.所述的降噪模块使用降噪自动编码对实时获取的用户声音或已存储的其它声音进行噪声抑制,获得降噪后的声音信息;
55.所述的转化模块将声音信息进行拉普拉斯变换,得到拉普拉斯频谱信息;
56.所述的特征提取模块将得到的拉普拉斯频谱信息进行二维傅里叶变换,得到拉普拉斯变换声音信息数据波数谱特征;
57.所述的噪音压制模块根据所述拉普拉斯变换声音信息数据波数谱,截取3~6个时间切片的滤波因子组合成滤波团;将时间切片的信息数据进行二维傅里叶变换,得到滤波信息数据波数谱,利用滤波信息数据波数谱对整段录音的声音数据波数谱进行环境噪音压制。
58.所述的图像处理模块包括ccd/cmos传感模块、图像识别模块、文字识别模块以及图文修正模块。所述的图文修正模块包括字体计算单元、字体修正选择单元。ccd/cmos传感模块将图像录入模块采集到的照片传递个图像识别模块,图像识别模块对其进行分析,做初步处理,凸显文字内容,淡化其他内容,然后再通过文字识别模块进行文字识别。
59.文字识别模块接收待识别的图像后二值化处理图像,根据像素的邻域块的像素值
分布确定所述像素位置上的二值化阈值;并基于图像切割字符,水平投影所述图像以确定每一行的上界限和下界限,基于所述上界限和下界限行切割以获得行,垂直投影行以获得字符的左右边界,基于所述左右边界切割得到单个单词;所述文字识别模块读取云端数据库中的待识别单词的单词模型,切割的单词与单词模型对比得到识别结果,当云端数据库没有待识别文字的单词模型时,返回图像切割字符并重新切割,直至可在云端数据库中检索对比得到识别结果;然后将识别结果输出。
60.图文修正模块包括字体计算单元、字体修正选择单元。字体计算单元,所述字体计算单元其根据其图像的多个特征点计算用图像进行摄像而得到的摄像图像,计算出多个特征点的各特征点处的变形量;字体修正选择单元,其选择与利用所述变形量计算单元计算出的所述各特征点处的变形量相对应的字体修正方法;图像修正处理模块,通过由所述字体修正方法选择部选择的字体修正方法,对所述应该投射的字体的规定区域进行修正,得到准确的文字信息。
61.通信模块采用现有技术,将声音处理模块以及图像处理模块处理后的数据传递给云处理器,通过云处理器与数据库进行对比,来实现翻译功能。
62.为了便于携带以及采集数据方便,本实施例中,客户端包括穿戴设备以及手持终端。
63.穿戴设备包括眼镜1,眼镜1的镜框内部设有电源模块以及通信模块,通信模块与手持终端进行无线连接。
64.镜框前端中间位置设有摄像头2,镜腿靠近镜框的外侧设有麦克风3,镜腿挂在耳朵位置的内侧设有扬声器4。
65.手持终端内部包括图像处理模块、声音处理模块、通信模块、电源模块以及穿戴设备控制模块。
66.穿戴设备控制模块控制穿戴设备开关以及音量大小。
67.同时,所述的手持终端还包括语言选择模块,所述的语言选择模块可选择需要翻译的语言类型。语言选择模块通过软件程序进行选择,手持终端上设有显示屏,显示屏采用电容屏或电阻屏,通过触碰显示屏来选择语言。
68.一种基于云处理功能的语言学习方法,包括以下步骤:
69.s1、当与外国友人进行交流时,麦克风3对其声音进行采集,然后将音频传递给手持终端,手持终端上的声音处理模块对音频进行处理,处理后传递给云服务器;
70.s2、云服务器对接受到的音频进行分析处理,分析处理方法为:先对其与数据库中的语种进行匹配,找到与其对应的语系,然后进行单词拆分,逐词进行翻译,然后根据语法组成一个连贯的语句,或找到对应的语系后,直接对音频进行翻译;
71.s3、云服务器将翻译好的语言通过手持终端传递给穿戴设备,然后通过扬声器4播放,使穿戴人理解外语的意思;
72.s4、当穿戴人需要讲话时,在手持终端上选择需要翻译成的语种,然后讲话,在重复s1至s3步骤,最终扬声器4播放相对应的外语声音。
73.一种基于云处理功能的语言学习方法,包括以下步骤:
74.s1、当需要了解文字类外语信息时,摄像头2对文字信息进行拍照,然后将图片传递给手持终端,手持终端上的图像处理模块对图片进行处理,处理后传递给云服务器;
75.s2、云服务器对接受到的图片信息进行分析处理,分析处理方法为:接收待识别的图像后二值化处理图像,根据像素的邻域块的像素值分布确定所述像素位置上的二值化阈值;并基于图像切割字符,水平投影所述图像以确定每一行的上界限和下界限,基于所述上界限和下界限行切割以获得行,垂直投影行以获得字符的左右边界,基于所述左右边界切割得到单个单词;
76.文字识别模块读取云端数据库中的待识别单词的单词模型,切割的单词与单词模型对比得到识别结果,当云端数据库没有待识别文字的单词模型时,返回图像切割字符并重新切割,直至可在云端数据库中检索对比得到识别结果;然后将识别结果输出;
77.s3、结果输出可采用两种方法:文字输出或音频输出,文字输出则在手持终端的显示屏上显示,音频输出则通过扬声器4进行播报。
78.同时在一些特殊场合,可选择同声传译服务,即在手持终端上增设人工服务或ai服务,ai服务按以上步骤,人工服务为同声传译服务。在手持终端上选择人工服务,则通过云处理器匹配到相关语种的人工服务人员。语种选配采用两种方法:一,在手持终端上选择;二、云服务器通过接受到的文字、语音信息自动分析匹配。
79.选择好语种后,人工服务人员与使用者进行视频连接,人工服务人员通过使用者的摄像头2以及麦克风3实时了解外文信息,然后进行快速、精准的翻译,并将翻译内容通过扬声器4进行播报。
80.当使用者使用母语进行交流后,人工服务人员通过麦克风3了解信息,然后翻译成外语,通过扬声器4播放给外国友人听。
81.扬声器4的音量可自动调节,调节方式为,当播放使用者母语时,音量低;当播放外语时,音量高。
82.上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在所属技术领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1