一种自适应的识别方法及系统与流程
本发明涉及信息交互技术领域,具体涉及一种自适应的识别方法及系统。
背景技术:
随着自然语言理解技术的不断发展,用户与智能终端的交互变得越来越频繁,经常需要使用语音或拼音等方式向智能终端输入信息。智能终端对输入信息进行识别,并根据识别结果做出相应操作。一般情况下,当用户用语音输入一段常用语句时,如“今天的天气不错”,“我们一起去吃饭”等,智能终端系统基本都会给出正确的识别结果。然而当用户输入信息中包含用户特有信息时,智能终端系统往往不能给出正确的识别结果,用户特有信息一般指与用户相关的个性化词,如用户有个同事叫“章东梅”,周末要和她去“红杉假日酒店”出差,用户向智能终端系统用语音输入“我明天和章东梅一起去红杉假日酒店出差”,其中,章东梅与红杉假日酒店是属于用户的个性化词,现有的智能终端系统一般给出的识别结果如下:
“我明天和张冬梅一起去红杉假日酒店出差”
“我明天和张冬梅一起去红衫假日酒店出差”
“我明天和张冬梅一起去洪山假日酒店出差”
“我明天合唱冬梅一起去红杉假日酒店出差”
除了上述结果外,甚至有些系统会给出差距更大的识别结果,使用户难以接受。
目前,智能终端的识别系统一般是通过获取用户相关文档数据,为每个用户建立一个较小的语言模型,然后将这个较小的语言模型以插值的形式融合到通用语言模型中,利用通用语言模型对用户输入信息进行识别。然而由于获取到的用户相关文档中经常包含大量与用户无关的数据信息, 如垃圾邮件,直接偏离用户个性化数据,导致根据用户相关文档获取到的有用用户数据较少,在用户语言模型训练时容易出现数据稀疏问题,从而使构建的用户语言模型可靠性较低。而且将所述用户语言模型融合到通用语言模型,往往会降低通用语言模型的识别准确度。此外,现有识别系统需要为每个用户构建一个语言模型,每个模型的维护需要消耗大量系统资源,当用户数量较多时,系统开销较大。
技术实现要素:
本发明提供一种自适应的识别方法及系统,以提高用户个性化词的识别准确度,并降低系统开销。
为此,本发明提供如下技术方案:
一种自适应的识别方法,包括:
根据用户历史语料构建用户个性化词典;
对所述用户个性化词典中的个性化词进行聚类,得到每个个性化词所属类编号;
根据所述个性化词所属类编号构建语言模型;
在对用户输入的信息进行识别时,如果所述信息中的词存在于所述用户个性化词典中,则根据该词对应的个性化词所属类编号对解码路径进行扩展,得到扩展后的解码路径;
根据扩展后的解码路径对所述信息进行解码,得到多个候选解码结果;
根据所述语言模型计算各候选解码结果的语言模型得分;
选取语言模型得分最高的候选解码结果作为所述信息的识别结果。
优选地,所述根据用户历史语料构建用户个性化词典包括:
获取用户历史语料,所述用户历史语料包括以下任意一种或多种:用户语音输入日志、用户文本输入日志、用户浏览文本信息;
根据所述用户历史语料进行个性化词发现,得到个性化词;
将所述个性化词添加到用户个性化词典中。
优选地,所述个性化词包括:易错个性化词和天然个性化词;所述易 错个性化词是指对用户输入信息进行识别时,经常出错的词;所述天然个性化词是指对用户输入信息进行识别时,可以通过用户的本地存储信息直接找到的词或根据该词扩展的词。
优选地,所述对所述用户个性化词典中的个性化词进行聚类,得到每个个性化词所属类编号包括:
确定所述个性化词的词向量及其左右邻接词的词向量;
根据所述个性化词的词向量及其左右邻接词的词向量对所述个性化词的词向量进行聚类,得到每个个性化词所属类编号。
优选地,所述确定所述个性化词及其左右邻接词的词向量包括:
对所述用户历史语料进行分词;
对分词得到的各词进行向量初始化,得到各词的初始词向量;
利用神经网络对各词的初始词向量进行训练,得到各词的词向量;
根据所有用户个性化词典得到所有个性化词,并根据所述个性化词所在用户历史语料,得到所述个性化词的左右邻接词;
提取所述个性化词的词向量及其左右邻接词的词向量。
优选地,所述根据所述个性化词及其左右邻接词的词向量对所述个性化词的词向量进行聚类,得到每个个性化词所属类编号包括:
根据各个性化词的词向量、左右邻接词的词向量、以及词向量的TF_IDF值计算个性化词向量之间的距离;
根据所述距离进行聚类,得到每个个性化词所属类编号。
优选地,所述根据所述个性化词所属类编号构建语言模型包括:
采集训练语料;
将所述训练语料中的个性化词替换为所述个性化词所属类编号,得到替换后的语料;将采集的训练语料及替换后的语料作为训练数据,训练得到语言模型。
优选地,所述方法还包括:
如果所述识别结果中包含个性化词的类编号,则将该类编号替换为其对应的个性化词。
优选地,所述方法还包括:
对所述用户输入的信息进行个性化词发现,如果有新的个性化词,则将新的个性化词添加到所述用户的个性化词典中,以更新所述用户的个性化词典;如果有用户的个性化词典做了更新,则根据更新后的个性化词典,更新所述语言模型;或者
定时根据用户历史语料对各用户个性化词典及所述语言模型进行更新。
一种自适应的识别系统,包括:
个性化词典构建模块,用于根据用户历史语料构建用户个性化词典;
聚类模块,用于对所述用户个性化词典中的个性化词进行聚类,得到每个个性化词所属类编号;
语言模型构建模块,用于根据所述个性化词所属类编号构建语言模型;
解码路径扩展模块,用于在对用户输入的信息进行识别时,如果所述信息中的词存在于所述用户个性化词典中,则根据该词对应的个性化词所属类编号对解码路径进行扩展,得到扩展后的解码路径;
解码模块,用于根据扩展后的解码路径对所述信息进行解码,得到多个候选解码结果;
语言模型得分计算模块,用于根据所述语言模型计算各候选解码结果的语言模型得分;
识别结果获取模块,用于选取语言模型得分最高的候选解码结果作为所述信息的识别结果。
优选地,所述个性化词典构建模块包括:
历史语料获取单元,用于获取用户历史语料,所述用户历史语料包括以下任意一种或多种:用户语音输入日志、用户文本输入日志、用户浏览文本信息;
个性化词发现单元,用于根据所述用户历史语料进行个性化词发现,得到个性化词;
个性化词典生成单元,用于将所述个性化词添加到用户个性化词典中。
优选地,所述聚类模块包括:
词向量训练单元,用于确定所述个性化词的词向量及其左右邻接词的词向量;
词向量聚类单元,用于根据所述个性化词的词向量及其左右邻接词的词向量对所述个性化词的词向量进行聚类,得到每个个性化词所属类编号。
优选地,所述词向量训练单元包括:
分词子单元,对所述用户历史语料进行分词;
初始化子单元,用于对分词得到的各词进行向量初始化,得到各词的初始词向量;
训练子单元,用于利用神经网络对各词的初始词向量进行训练,得到各词的词向量;
查找子单元,用于根据所有用户个性化词典得到所有个性化词,并根据所述个性化词所在用户历史语料,得到所述个性化词的左右邻接词;
提取子单元,用于提取所述个性化词的词向量及其左右邻接词的词向量。
优选地,所述词向量聚类单元包括:
距离计算子单元,用于根据各个性化词的词向量、左右邻接词的词向量、以及词向量的TF_IDF值计算个性化词向量之间的距离;
距离聚类子单元,用于根据所述距离进行聚类,得到每个个性化词所属类编号。
优选地,所述语言模型构建模块包括:
语料采集单元,用于采集训练语料;
语料处理单元,用于将所述训练语料中的个性化词替换为所述个性化词所属类编号,得到替换后的语料;语言模型训练单元,用于将采集的训练语料及替换后的语料作为训练数据,训练得到语言模型。
优选地,所述识别结果获取模块,还用于在所述识别结果中包含个性化词的类编号时,将该类编号替换为其对应的个性化词。
本发明实施例提供的自适应的识别方法及系统,利用用户的个性化词典构建语言模型,具体地,将用户的个性化词进行聚类后,根据个性化词 所属类编号构建该语言模型,从而使该语言模型既具有全局性特点,又考虑了各用户的个性化特点。利用该语言模型对用户输入的信息进行识别时,如果所述信息中的词存在于所述用户个性化词典中,则根据该词对应的个性化词所属类编号对解码路径进行扩展,得到扩展后的解码路径,然后根据扩展后的解码路径对所述信息进行解码,从而在保证原有识别效果的基础上,大大提高了用户个性化词的识别准确度。由于每个个性化词使用其所属类编号表示,从而可以解决构建全局个性化语言模型时的数据稀疏问题。而且,只需为每个用户构建一个个性化词典,而不需要为每个用户单独构建一个语言模型,从而可以大大降低系统开销,提升系统识别效率。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
图1是本发明实施例自适应的识别方法的流程图;
图2是本发明实施例中解码路径的扩展示意图;
图3是本发明实施例中训练词向量的流程图;
图4是本发明实施例中训练词向量使用的神经网络的结构示意图;
图5是本发明实施例自适应的识别系统的结构示意图;
图6是本发明系统中词向量训练单元的一种具体结构示意图;
图7是本发明系统中语言模型构建模块的一种具体结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明实施例的方案,下面结合附图和实施方式对本发明实施例作进一步的详细说明。
本发明实施例提供的自适应的识别方法及系统,利用用户的个性化词典构建语言模型,使该语言模型既具有全局性特点,又考虑了各用户的个 性化特点。从而在利用该语言模型对用户输入的信息进行识别时,既可以保证原有识别效果,又可以大大提高用户个性化词的识别准确度。
如图1所示,是本发明实施例自适应的识别方法的流程图,包括以下步骤:
步骤101,根据用户历史语料构建用户个性化词典。
所述用户历史语料主要通过用户日志获取到,具体可以包括以下任意一种或多种:用户语音输入日志、用户文本输入日志、用户浏览文本信息。其中,语音输入日志主要包括用户输入语音、语音识别结果及用户反馈信息(用户对识别结果修改后的结果);文本输入日志主要包括用户输入文本信息、输入文本的识别结果及用户反馈信息(用户对输入文本识别结果修改后的结果),用户浏览文本主要指用户根据搜索结果选择浏览的文本信息(用户浏览文本信息可能是用户感兴趣的)。
在构建用户个性化词典时,可以先为所述用户初始化一个空的个性化词典,获取上述这些用户历史语料,对所述用户历史语料进行个性化词发现,得到个性化词,然后将发现的个性化词加入到对应所述用户的个性化词典中。
所述个性化词可以包括:易错个性化词和天然个性化词两种。所述易错个性化词是指对用户输入信息进行识别时,经常出错的词;所述天然个性化词是指对用户输入信息进行识别时,可以通过用户的本地存储信息直接找到的词或根据该词扩展的词,如用户手机通讯录中的姓名以及扩展结果,比如“章东梅”可以扩展出“东梅”,或用户个人电脑中收藏或关注的信息。如用户输入语音为“我明天和章东梅一起去红杉假日酒店出差”,语音识别结果为“我明天和[章][东][梅]一起去[洪][山]假日酒店出差”,其中“洪山”为识别错误的词,可以作为易错个性化词,“章东梅”可以从用户手机通讯录中直接得到,可以作为天然个性化词。
具体的个性化词发现方法本发明实施例不作限定,如可以采用人工标注的方法,也可以采用自动发现的方法,如根据用户的反馈信息进行发现,将用户修改过的易错词作为个性化词,也可以根据用户使用的智能终端中 已存储的词进行发现,或者根据识别结果进行发现,如将识别置信度较低的词作为个性化词。
需要说明的是,需要为每个用户单独构建一个个性化词典,记录每个用户的个性化词相关信息。
另外,还可进一步保存每个个性化词对应的历史语料,以便后续在使用该语料时方便查找。为了便于记录,可以对每个历史语料进行编号,这样,在保存每个个性化词对应的历史语料时,只需记录该历史语料的编号即可。如个性化词为章东梅时,保存记录为“章东梅语料编号:20”。当然,这些信息可以单独保存,也可以同时保存在用户个性化词典中,对此本发明实施例不做限定。
步骤102,对所述用户个性化词典中的个性化词进行聚类,得到每个个性化词所属类编号。
具体地,可以根据个性化词及其左右邻接词的词向量对个性化词的词向量进行聚类,得到每个个性化词所属类编号。
需要说明的是,在进行聚类时,需要考虑所有用户的个性化词,词向量的训练过程及聚类过程将在后面详细说明。
步骤103,根据所述个性化词所属类编号构建语言模型。
语言模型的训练可以采集大量训练语料,然后采用现有的一些训练方法,如统计N-gram的方法,采用最大似然估计方法对参数进行估计,得到N-gram模型,所不同的是,在本发明实施例中,需要将采集的训练语料中的个性化词替换为该个性化词所属类编号,比如采集的训练语料为“我明天和[章东梅]一起去[洪山]假日酒店出差”,[]中为个性化词,将其中的所有个性化词替换成其所属类编号为“我明天和CLASS060一起去CLASS071假日酒店出差”。然后,将采集的训练语料及替换后的语料作为训练数据,训练得到语言模型。具体训练时,每个个性化词所属类编号直接作为一个词进行训练。
可见,通过上述方式训练的语言模型,既具有全局性特点,又考虑了各用户的个性化特点。而且由于每个个性化词使用其所属类编号表示,因 此可以解决构建全局个性化语言模型时的数据稀疏问题。
步骤104,在对用户输入的信息进行识别时,如果所述信息中的词存在于所述用户个性化词典中,则根据该词对应的个性化词所属类编号对解码路径进行扩展,得到扩展后的解码路径。
由于语言模型可以在多种不同的识别中会有应用,比如,语音识别、文本识别、机器翻译等,因此,根据不同的应用,用户输入的信息可以是语音、拼音、按键信息等信息,对此本发明实施例不做限定。
在对用户输入的信息进行识别时,首先要在解码网络中对该信息中的各词进行解码,得到解码候选结果,然后根据语言模型计算候选解码结果的语言模型得分。
与现有技术不同的是,在本发明实施例中,在对用户输入的信息进行解码时,需要判断所述信息中的各词是否存在于该用户的个性化词典中。如果存在,则利用该词所属类编号对解码路径进行扩展,得到扩展后的解码路径。然后,再利用扩展后的解码路径对用户输入的信息进行解码,得到多个解码候选结果。
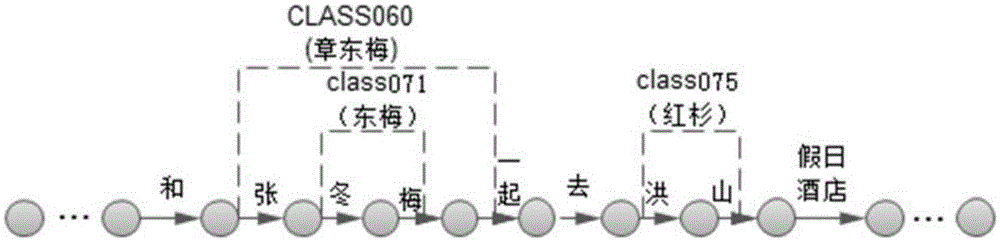
例如,当前用户个性化词典中部分个性化词如下:
章东梅 语料编号:20, 类编号:CLASS060
东梅 语料编号:35,20 类编号:CLASS071
红杉 语料编号:96, 类编号:CLASS075
用户语音输入信息为“我明天和章东梅一起去红杉假日酒店出差”,对输入信息进行解码时,通过精确匹配或模糊匹配判断当前词是否存在于用户个性化词典中,根据判断结果对解码路径进行扩展。
需要说明的是,在此还要记录扩展解码路径时用到的类编号所对应的个性化词,以便在后续得到最终识别结果后,如果该识别结果中包含个性化词的类编号,将该类编号替换为其对应的个性化词。
步骤105,根据扩展后的解码路径对所述信息进行解码,得到多个候选解码结果。
如图2所示为一条解码路径的部分扩展示意图,其中,括号中为类编 号对应的个性化词,根据扩展后的解码路径得到的部分侯选解码结果如下所示:
我明天和CLASS060(章东梅)一起去红杉假日酒店出差
我明天和章CLASS071(东梅)一起去红杉假日酒店出差
我明天和CLASS060(章东梅)一起去CLASS075(红杉)假日酒店出差
我明天和章CLASS071(东梅)一起去CLASS075(红杉)假日酒店出差
步骤106,根据所述语言模型计算各候选解码结果的语言模型得分。
在计算候选解码结果的语言模型得分时,对于候选解码结果中的个性化词和非个性化词,均可以采用现有技术中的一些计算方法,对此本发明实施例不做限定。
另外,对于候选解码结果中的个性化词,还可以根据训练词向量时得到的神经网络语言模型及给定历史词条件下,采用如下公式(1)计算其概率:
其中,RNNLM(S)为当前侯选解码结果S中所有词的神经网络语言模型得分,可以通过查找神经网络语言模型,得到当前侯选解码结果中所有词的神经网络语言模型得分;S为当前侯选解码结果;s为当前侯选解码结果包含的词总数;η为神经网络语言模型得分权重,0≤η≤1,具体可根据经验或实验结果取值;为在历史词i=1…n-1条件下,下一个词为个性化词wi的概率,具体可以根据当前个性化词的所属类编号相关信息计算得到,如下式(2)所示:
其中,为在历史词i=1…n-1条件下,当前个性化词的所属类编号为classj的概率;classj为第j个类编号,具体可通过统计历史语料得到,计算方法如式(3)所示;p(wi|classj)为在类编号为classj的条件下,当前词为个性化词wi的概率,具体可根据当前词的词向量与给定类编 号的聚类中心点的向量之间的余弦距离得到,计算方法如(4)所示:
其中,表示历史词在语料中出现的总数;表示历史词后面为类编号classj的总数。为wi的词向量,表示编号为classj的聚类中心点的向量。
步骤107,选取语言模型得分最高的候选解码结果作为所述信息的识别结果。
需要说明的是,如果该识别结果中包含个性化词的类编号,还需要将该类编号替换为其对应的个性化词。
如图3所示,是本发明实施例中训练词向量的流程图,包括以下步骤:
步骤301,对用户历史语料进行分词。
步骤302,对分词得到的各词进行向量初始化,得到各词的初始词向量。
每个词的初始词向量维数可以根据经验或实验结果确定,一般与语料大小或分词词典大小相关。例如,具体初始化时,可以在-0.01到0.01之间随机取值,如章东梅(0,0.003,0,0,-0.01,0,…)。
步骤303,利用神经网络对各词的初始词向量进行训练,得到各词的词向量。
比如,可以使用三层神经网络进行训练,即输入层、隐层、及输出层,其中,输入层为每个历史词的初始词向量,输出层为给定历史词条件下每个词出现的概率,将所有词出现的概率使用一个向量表示,向量大小为所有词单元总数,所有词单元总数根据分词词典中词总数确定,例如所有词出现的概率向量为(0.286,0.036,0.073,0.036,0.018,……),隐层节点数一般较多,如3072个节点;使用正切函数作为激活函数,如式(5)为目标函数:
y=b+Utanh(d+Hx) (5)
其中,y为给定历史词条件下,每个词出现的概率,大小为|v|×1,|v|表示分词词典大小;U是隐层到输出层的权重矩阵,使用|v|×r的矩阵表示;r为隐层节点数;b和d为偏置项;x为输入历史词向量首位相接组合成的向量,大小为(n*m)×1,m为每个输入词向量的维数,n为输入历史词向量数;H为权重转换矩阵,大小为r×(n*m),tanh()为正切函数,即激活函数。
如图4所示,为训练词向量时,使用的神经网络结构示例。
其中,index for Wt-n+1表示编号为Wt-n+1的词,C(wt-n+1)为编号为Wt-n+1词的初始词向量,tanh为正切函数,softmax为规整函数,用于对输出层输出的概率进行规整,得到规整后的概率值。
利用用户历史语料,对目标函数即上述公式(5)进行优化,如采用随机梯度下降方法优化。优化结束后,得到每个词的最终词向量(以下简称为词向量),同时得到神经网络语言模型,即前面公式(1)中提到的神经网络语言模型。
步骤304,根据所有用户个性化词典得到所有个性化词,并根据所述个性化词所在用户历史语料,得到所述个性化词的左右邻接词。
所述左邻接词指在语料中常出现在个性化词左边的一个或多个词,一般取左边第一个词;所述右邻接词指在语料中常出现在个性化词右边的一个或多个词,一般取右边第一个词。当个性化词出现在不同的语料中时,会有多个左右邻接词。
如个性化词“钓鱼岛”的左右邻接词如下:
左邻接词:保卫、收复、在、抵达、登上、收回、夺回、……
右邻接词:真相、海域、是、及其、事件、局势、了、永远、……
步骤305,提取个性化词的词向量及其左右邻接词的词向量。
在查找得到了个性化词及其左右邻接词后,即可从上面训练结果中直接得到每个词对应的词向量。
在得到个性化词及其左右邻接词的词向量后,即可根据个性化词的词向量及其左右邻接词的词向量对个性化词的词向量进行聚类,得到每个个 性化词所属类编号。在本发明实施例中,可以根据各个性化词的词向量、左右邻接词的词向量、以及词向量的TF_IDF(Term Frequency_Inverse Document Frequency,词频_逆向文件频率)值计算个性化词向量之间的距离,词向量的TF_IDF值可以通过对历史语料进行统计得到,当前词的TF_IDF值越大,当前词越具有区分性;然后根据所述距离进行聚类,得到每个个性化词所属类编号。
具体地,首先根据两个个性化词的左邻接词的词向量的TF_IDF值,计算左邻接词的词向量之间的余弦距离;随后计算两个个性化词向量之间的余弦距离;之后再根据两个个性化词的右邻接词的词向量的TF_IDF值,计算右邻接词的词向量之间的余弦距离;最后将左邻接词、个性化词及右邻接词的余弦距离进行融合后,得到两个个性化词向量之间的距离,具体计算方法如式(6)所示:
其中,各参数含义如下:
为第a个个性化词的词向量和第b个个性化词的词向量之间的距离;
为第a个个性化词的第m个左邻接词的词向量,LTIam为该左邻接词的词向量的TF_IDF值,M为的左邻接词的词向量总数;
为第b个个性化词的第n个左邻接词的词向量,LTIbn为该左邻接词的词向量的TF_IDF值,N为的左邻接词的词向量总数;
为第a个个性化词的第s个右邻接词的词向量,LTIas为该右邻接词的词向量的TF_IDF值,S为的右邻接词的词向量总数;
为第b个个性化词的第t个右邻接词的词向量,LTIas为该右邻接词的词向量的TF_IDF值,T为的右邻接词的词向量总数;
α,β,γ分别为个性化词的词向量与左邻接词的词向量之间的余弦距离、个性化词的词向量之间的余弦距离、以及个性化词的词向量与右邻接词的词向量 之间的余弦距离的权重,具体可以根据经验或实现结果取值,α,β,γ为经验值,β权重一般较大一些,α,γ的值与个性化词的左右邻接词数量相关,一般邻接词数量越多,权重较大;如左邻接词数量较多的时候α权重较大,并且满足如下条件:
a+β+γ=1;
在本发明实施例中,聚类算法可以采用K-means算法等,预先设定聚类总数,根据公式(6)计算个性化词的词向量之间的距离进行聚类,得到每个个性化词的词向量所在类编号,将该类编号作为该个性化词所属类编号。
为了便于使用,可以将得到的个性化词对应的类编号添加到用户个性化词典中。当然,如果多个用户的个性化词典中包含相同的个性化词,则需要将该个性化词所属的类编号添加到每个包含该词的个性化词典中。
如A用户和B用户的个性化词典中均含有“章东梅”,则添加相应的类编号后如下:
A用户的个性化词典中,信息如下:
“章东梅语料编号:20类编号:CLASS060”;
B用户的个性化词典中,信息如下:
“章东梅语料编号:90类编号:CLASS060”。
需要注意的是,在进行词向量训练时,用到的用户历史语料是指所有用户的历史语料,而非单一用户的历史语料,这与建立用户个性化词典时是不同的,因为个性化词典是针对单一用户的,也就是说,对每个用户要分别建立该用户的个性化词典,当然建立该个性化词典所依据的历史语料可以仅限于该用户的历史语料。另外,在进行词向量训练时,用到的用户历史语料可以是构建用户个性化词典时用到的所有历史语料,也可以是这些历史语料中只包含个性化词的一些语料。当然语料越充足,训练结果越准确,但同时训练时也会消耗更多的系统资源,因此具体历史语料的选用 数量可以根据应用需要来确定,本发明实施例不做限定。
本发明实施例提供的自适应的识别方法,利用用户的个性化词典构建语言模型,具体地,将用户的个性化词进行聚类后,根据个性化词所属类编号构建该语言模型,从而使该语言模型既具有全局性特点,又考虑了各用户的个性化特点。利用该语言模型对用户输入的信息进行识别时,如果所述信息中的词存在于所述用户个性化词典中,则根据该词对应的个性化词所属类编号对解码路径进行扩展,得到扩展后的解码路径,然后根据扩展后的解码路径对所述信息进行解码,从而在保证原有识别效果的基础上,大大提高了用户个性化词的识别准确度。由于每个个性化词使用其所属类编号表示,从而可以解决构建全局个性化语言模型时的数据稀疏问题。而且,只需为每个用户构建一个个性化词典,而不需要为每个用户单独构建一个语言模型,从而可以大大降低系统开销,提升系统识别效率。
进一步地,本发明还可以对用户输入信息进行新个性化词的发现,将新发现的个性化词补充到用户个性化词典中,例如将识别置信度较低的词作为个性化词,将该个性化词加入到该用户的个性化词典中。具体加入时,可以将新发现的个性化词展示给用户,询问用户是否将其加入到个性化词典中,也可以后台自行将其加入到个性化词典中,以更新用户个性化词典。在用户个性化词典更新后,还可以利用更新后的个性化词典对所述语言模型进行更新。或者,设定更新时间阈值,当超过该时间阈值后,利用用户这段时间内的历史语料更新个性化词典,然后再进行语言模型的更新。
相应地,本发明实施例还提供一种自适应的识别系统,如图5所示,是该系统的一种结构示意图。
在该实施例中,所述系统包括以下各模块:个性化词典构建模块501,聚类模块502,语言模型构建模块503,解码路径扩展模块504,解码模块505,语言模型得分计算模块506,识别结果获取模块507。
下面对各模块的功能及具体实现方式进行详细说明。
上述个性化词典构建模块501用于根据用户历史语料构建用户个性化词典,如图5中所示,对于不同的用户,需要分别根据该用户的历史语料 为其构建个性化词典,也就是说,不同用户的个性化词典是各自独立的。在构建个性化词典时,可以通过个性化词发现来找出用户历史语料中的个性化词,具体的个性化词发现方法本发明实施例不做限定。
相应地,个性化词典构建模块501的一种具体结构包括以下各单元:
历史语料获取单元,用于获取用户历史语料,所述用户历史语料包括以下任意一种或多种:用户语音输入日志、用户文本输入日志、用户浏览文本信息;
个性化词发现单元,用于根据所述用户历史语料进行个性化词发现,得到个性化词;
个性化词典生成单元,用于将所述个性化词添加到用户个性化词典中。
上述聚类模块502用于对所述用户个性化词典中的个性化词进行聚类,得到每个个性化词所属类编号。具体地,可以根据个性化词及其左右邻接词的词向量对个性化词的词向量进行聚类,得到每个个性化词所属类编号。
相应地,聚类模块502的一种具体结构可以包括:词向量训练单元和词向量聚类单元。其中,所述词向量训练单元用于确定所述个性化词的词向量及其左右邻接词的词向量;所述词向量聚类单元用于根据所述个性化词的词向量及其左右邻接词的词向量对所述个性化词的词向量进行聚类,得到每个个性化词所属类编号。
需要说明的是,在进行聚类时,需要考虑所有用户的个性化词,利用至少包含这些个性化词的历史语料,进行词向量训练。所述词向量训练单元的一种具体结构如图6所示,包括以下各子单元:
分词子单元61,对用户历史语料进行分词,所述用户历史语料可以是构建用户个性化词典时用到的所有历史语料,也可以是这些历史语料中只包含个性化词的一些语料;
初始化子单元62,用于对分词得到的各词进行向量初始化,得到各词的初始词向量;
训练子单元63,用于利用神经网络对各词的初始词向量进行训练,得到各词的词向量;
查找子单元64,用于根据所有用户个性化词典得到所有个性化词,并根据所述个性化词所在用户历史语料,得到所述个性化词的左右邻接词,个性化词的左右邻接词的具体含义已在前面详细介绍,在此不再赘述;
提取子单元65,用于提取所述个性化词的词向量及其左右邻接词的词向量。
所述词向量聚类单元具体可以根据各个性化词的词向量、左右邻接词的词向量、以及词向量的TF_IDF(Term Frequency_Inverse Document Frequency,词频_逆向文件频率)值计算个性化词向量之间的距离,然后根据所述距离进行聚类,得到每个个性化词所属类编号。相应地,所述词向量聚类单元的一种具体结构可以包括:距离计算子单元和距离聚类子单元。其中,所述距离计算子单元用于根据各个性化词的词向量、左右邻接词的词向量、以及词向量的TF_IDF值计算个性化词向量之间的距离;所述距离聚类子单元,用于根据所述距离进行聚类,得到每个个性化词所属类编号,具体的聚类算法可以采用现有的一些算法,比如K-means算法等,对此本发明实施例不做限定。
上述语言模型构建模块503用于根据所述个性化词所属类编号构建语言模型,具体可以与现有的语言模型的训练方法类似的训练方式,所不同的是,在本发明实施例中,语言模型构建模块503还需要将训练语料中的个性化词替换为该个性化词所属类编号,然后将采集的训练语料及替换后的语料作为训练数据,构建语言模型。
相应地,语言模型构建模块503的一种具体结构如图7所示,包括以下各单元:
语料采集单元71,用于采集训练语料,所述训练语料可以包括所有用户的历史语料及其它语料,对此本发明实施例不做限定。
语料处理单元72,用于将所述训练语料中的个性化词替换为所述个性化词所属类编号;语言模型训练单元73,用于将采集的训练语料及替换后的语料作为训练数据,训练得到语言模型。具体训练时,每个个性化词所属类编号直接作为一个词进行训练。
上述解码路径扩展模块504用于在对用户输入的信息进行识别时,如果所述信息中的词存在于所述用户个性化词典中,则根据该词对应的个性化词所属类编号对解码路径进行扩展,得到扩展后的解码路径;
与现有技术不同的是,在本发明实施例中,在系统接收到用户输入的信息后,解码路径扩展模块504需要判断所述信息中的各词是否存在于该用户的个性化词典中。如果存在,则利用该词所属类编号对解码路径进行扩展,得到扩展后的解码路径。需要注意的是,如图5中所示,针对某个特定用户,如用户1,只需判断该用户输入的信息中的各词是否存在于用户1的个性化词典中,而无需判断这些词是否存在于其它用户的个性化词典中。
上述解码模块505用于根据扩展后的解码路径对所述信息进行解码,得到多个候选解码结果。
上述语言模型得分计算模块506用于根据所述语言模型计算各候选解码结果的语言模型得分。在计算候选解码结果的语言模型得分时,对于候选解码结果中的个性化词和非个性化词,均可以采用现有技术中的一些计算方法。当然,对于候选解码结果中的个性化词,还可以采用前面公式(1)的计算方法,由于其包含了更多历史信息,因此可以使计算结果更准确。
上述识别结果获取模块507用于选取语言模型得分最高的候选解码结果作为所述信息的识别结果。需要说明的是,如果该识别结果中包含个性化词的类编号,识别结果获取模块507还需要将该类编号替换为其对应的个性化词。
在实际应用中,本发明实施例的自适应的识别系统,还可以根据用户输入信息或定时对用户个性化词典及语言模型进行更新,具体更新方式本发明不做限定。而且,可以由人工触发进行更新,也可以由系统自动触发进行更新。
本发明实施例提供的自适应的识别系统,利用用户的个性化词典构建语言模型,具体地,将用户的个性化词进行聚类后,根据个性化词所属类编号构建该语言模型,从而使该语言模型既具有全局性特点,又考虑了各 用户的个性化特点。利用该语言模型对用户输入的信息进行识别时,如果所述信息中的词存在于所述用户个性化词典中,则根据该词对应的个性化词所属类编号对解码路径进行扩展,得到扩展后的解码路径,然后根据扩展后的解码路径对所述信息进行解码,从而在保证原有识别效果的基础上,大大提高了用户个性化词的识别准确度。由于每个个性化词使用其所属类编号表示,从而可以解决构建全局个性化语言模型时的数据稀疏问题。而且,只需为每个用户构建一个个性化词典,而不需要为每个用户单独构建一个语言模型,从而可以大大降低系统开销,提升系统识别效率。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的系统实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
以上对本发明实施例进行了详细介绍,本文中应用了具体实施方式对本发明进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及系统;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!