训练神经网络声学模型的方法和装置及语音识别方法和装置与流程
本发明涉及语音识别系统,具体涉及训练神经网络声学模型的方法、训练神经网络声学模型的装置、语言识别方法以及语音识别装置。
背景技术:
语音识别系统一般包含声学模型(am)和语言模型(lm)两个部分。声学模型是统计语音特征对音素单元概率分布的模型,语言模型是统计词序列(词汇上下文)出现概率的模型,语音识别过程是根据两个模型的概率得分的加权和得到得分最高的结果。
近几年,神经网络声学模型(nnam)作为一种新方法被引入语音识别系统,极大地提高了识别性能。
在神经网络声学模型的训练中,传统的技术是使用强制对齐的方法得到每个语音特征样本的输出目标并将其概率设置为1,然后基于交叉熵训练声学模型。
后来也有通过使用所有输出目标的概率分布作为目标输出,基于kl距离(kullback-leiblerdivergence,又称为kl散度)训练声学模型,kl距离是和交叉熵等价的。
技术实现要素:
本发明者们发现,在传统的神经网络声学模型的训练中,单一目标的训练和所有输出目标的训练都没有合理的使用训练目标之间的相似性,缺乏对训练目标的选择和筛选。
对于单一目标的训练,在给定训练样本的情况下,输出状态目标的概率为1,其他输出状态目标为0,而这样的训练忽略了输出状态目标和其他状态目标的之间的相似性,破坏了输出状态目标的真实的概率分布。例如一些和输出状态目标非常相似的其他状态也应该有一个合理的概率分布值。
对于所有输出目标的训练,也没有合理的使用训练目标之间的相似性,缺乏对训练目标的选择和筛选。
另外,在传统的神经网络声学模型训练中,对于具有多个输出状态目标的神经网络声学模型训练来说,使用交叉熵作为训练准则进行训练不够灵活,不能够从多角度学习输出目标的真实的概率分布。
为了进一步改进神经网络声学模型的训练方法,提高语音识别的精度,本发明提出了使用聚集的音素状态来训练神经网络声学模型的方法和装置,并进一步提供了语音识别方法和语音识别装置。在本发明的一个实施方式中,将与标注的音素状态相似度高或距离近的音素状态聚集,聚集的音素状态和标注的音素状态一起分享输出概率。具体地,提供了以下技术方案。
[1]一种训练神经网络声学模型的方法,包括:
基于包括训练语音和标注的音素状态的训练数据,计算与上述标注的音素状态不同的音素状态的得分;
将得分大于预定阈值的音素状态和上述标注的音素状态聚集;
使上述聚集的音素状态分享上述标注的音素状态的概率;和
基于上述训练语音和上述聚集的音素状态,训练神经网络声学模型。
通过上述方案[1]的训练神经网络声学模型的方法,将得分高的音素状态与标注的音素状态聚集,聚集的音素状态分享标注的音素状态的概率,能够真实平滑地训练神经网络声学模型。
[2]根据上述方案[1]所述的训练神经网络声学模型的方法,其中,
计算上述音素状态的得分的步骤包括:
基于上述音素状态与上述标注的音素状态之间的相似度和上述音素状态和上述标注的音素状态之间的距离中的至少一个,计算上述音素状态的得分。
通过上述方案[2]的训练神经网络声学模型的方法,基于音素状态与标注的音素状态之间的相似度和音素状态和标注的音素状态之间的距离中的至少一个,计算音素状态的得分,能够将与标注的音素状态相似度高或距离近的音素状态聚集,进而分享标注的音素状态的概率,能够更加真实平滑地训练神经网络声学模型。
[3]根据上述方案[1]所述的训练神经网络声学模型的方法,其中,
计算上述音素状态的得分的步骤包括:
基于上述训练数据和训练好的神经网络声学模型,计算上述音素状态的得分。
[4]根据上述方案[3]所述的训练神经网络声学模型的方法,其中,
计算上述音素状态的得分的步骤包括:
通过向前传播,得到上述音素状态的得分。
通过上述方案[3]或[4]的训练神经网络声学模型的方法,基于训练数据和训练好的神经网络声学模型,计算音素状态的得分,能够基于训练好的的神经网络声学模型选择音素状态进行聚集,进而分享标注的音素状态的概率,能够更加真实平滑地训练神经网络声学模型。
[5]根据上述方案[1]至[4]的任一方案所述的训练神经网络声学模型的方法,其中,
将得分大于预定阈值的音素状态和上述标注的音素状态聚集的步骤包括:
利用上述音素状态的决策树,对上述音素状态进行过滤。
[6]根据上述方案[5]所述的训练神经网络声学模型的方法,其中,
将与上述标注的音素状态不在同一决策树上的音素状态过滤。
通过上述方案[5]或[6]的训练神经网络声学模型的方法,将与标注的音素状态不在同一决策树上的音素状态过滤,能够更加真实平滑地训练神经网络声学模型。
[7]根据上述方案[1]至[6]的任一方案所述的训练神经网络声学模型的方法,其中,
使上述聚集的音素状态分享上述标注的音素状态的概率的步骤包括:
基于预定的分享比例和上述聚集的音素状态的得分,分享上述标注的音素状态的概率。
[8]根据上述方案[1]至[7]的任一方案所述的训练神经网络声学模型的方法,其中,
训练神经网络声学模型的步骤包括:
使用交叉熵训练准则,训练神经网络声学模型。
[9]根据上述方案[8]所述的训练神经网络声学模型的方法,其中,
上述交叉熵训练准则包括带权重的交叉熵训练准则。
[10]根据上述方案[9]所述的训练神经网络声学模型的方法,其中,
上述带权重的交叉熵训练准则为:
上述带权重的交叉熵训练准则为:
通过上述方案[10]的训练神经网络声学模型的方法,通过调节带权重的交叉熵训练准则的权重因子和距离因子,能够提高训练的灵活度,能够从多角度学习输出目标的真实的概率分布。
[11]一种语音识别方法,包括:
输入待识别的语音;
利用由上述方案[1]至[10]的任一方案所述的方法训练得到的神经网络声学模型和语言模型将上述语音识别为文本句。
通过上述方案[11]的语音识别方法,能够提高语音识别的精度。
[12]一种训练神经网络声学模型的装置,包括:
计算单元,其基于包括训练语音和标注的音素状态的训练数据,计算与上述标注的音素状态不同的音素状态的得分;
聚集单元,其将得分大于预定阈值的音素状态和上述标注的音素状态聚集;
分享单元,其使上述聚集的音素状态分享上述标注的音素状态的概率;和
训练单元,其基于上述训练语音和上述聚集的音素状态,训练神经网络声学模型。
通过上述方案[12]的训练神经网络声学模型的装置,将得分高的音素状态与标注的音素状态聚集,聚集的音素状态分享标注的音素状态的概率,能够真实平滑地训练神经网络声学模型。
[13]根据上述方案[12]所述的训练神经网络声学模型的装置,其中,
上述计算单元,基于上述音素状态与上述标注的音素状态之间的相似度和上述音素状态和上述标注的音素状态之间的距离中的至少一个,计算上述音素状态的得分。
通过上述方案[13]的训练神经网络声学模型的装置,基于音素状态与标注的音素状态之间的相似度和音素状态和标注的音素状态之间的距离中的至少一个,计算音素状态的得分,能够将与标注的音素状态相似度高或距离近的音素状态聚集,进而分享标注的音素状态的概率,能够更加真实平滑地训练神经网络声学模型。
[14]根据上述方案[12]所述的训练神经网络声学模型的装置,其中,
上述计算单元,基于上述训练数据和训练好的神经网络声学模型,计算上述音素状态的得分。
[15]根据上述方案[14]所述的训练神经网络声学模型的装置,其中,
上述计算单元,通过向前传播,得到上述音素状态的得分。
通过上述方案[14]或[15]的训练神经网络声学模型的装置,基于训练数据和训练好的神经网络声学模型,计算音素状态的得分,能够基于训练好的的神经网络声学模型选择音素状态进行聚集,进而分享标注的音素状态的概率,能够更加真实平滑地训练神经网络声学模型。
[16]根据上述方案[12]至[15]的任一方案所述的训练神经网络声学模型的装置,其中,
上述聚集单元,利用上述音素状态的决策树,对上述音素状态进行过滤。
[17]根据上述方案[16]所述的训练神经网络声学模型的装置,其中,
上述聚集单元,将与上述标注的音素状态不在同一决策树上的音素状态过滤。
通过上述方案[16]或[17]的训练神经网络声学模型的装置,将与标注的音素状态不在同一决策树上的音素状态过滤,能够更加真实平滑地训练神经网络声学模型。
[18]根据上述方案[12]至[17]的任一方案所述的训练神经网络声学模型的装置,其中,
上述分享单元,基于预定的分享比例和上述聚集的音素状态的得分,分享上述标注的音素状态的概率。
[19]根据上述方案[12]至[18]的任一方案所述的训练神经网络声学模型的装置,其中,
上述训练单元,使用交叉熵训练准则,训练神经网络声学模型。
[20]根据上述方案[19]所述的训练神经网络声学模型的装置,其中,
上述交叉熵训练准则包括带权重的交叉熵训练准则。
[21]根据上述方案[20]所述的训练神经网络声学模型的装置,其中,
上述带权重的交叉熵训练准则为:
其中
通过上述方案[21]的训练神经网络声学模型的装置,通过调节带权重的交叉熵训练准则的权重因子和距离因子,能够提高训练的灵活度,能够从多角度学习输出目标的真实的概率分布。
[22]一种语音识别装置,包括:
输入单元,其输入待识别的语音;
语音识别单元,其利用由上述方案[12]至[21]的任一方案所述的装置训练得到的神经网络声学模型和语言模型将上述语音识别为文本句。
通过上述方案[22]的语音识别装置,能够提高语音识别的精度。
[23]根据上述方案[1]所述的训练神经网络声学模型的方法,其中,
在计算上述音素状态的得分的步骤之前还包括:
将与上述标注的音素状态不在同一决策树上的音素状态过滤。
通过上述方案[23]的训练神经网络声学模型的方法,在计算得分之前,将与标注的音素状态不在同一个决策树上的音素状态过滤,可以降低计算量,提高计算效率。
[24]根据上述方案[12]所述的训练神经网络声学模型的装置,还包括:
过滤单元,其在上述计算单元计算上述音素状态的得分之前,将与上述标注的音素状态不在同一决策树上的音素状态过滤。
通过上述方案[23]的训练神经网络声学模型的装置,在计算单元计算得分之前,将与标注的音素状态不在同一个决策树上的音素状态过滤,可以降低计算量,提高计算效率。
附图说明
通过以下结合附图对本发明具体实施方式的说明,能够更好地了解本发明上述的特点、优点和目的。
图1是根据本发明的一个实施方式的训练神经网络声学模型的方法的流程图。
图2是根据本发明的一个实施方式的训练神经网络声学模型的方法的一个实例的流程图。
图3是根据本发明的另一个实施方式的语音识别方法的流程图。
图4是根据本发明的另一实施方式的训练神经网络声学模型的装置的框图。
图5是根据本发明的另一实施方式的语音识别装置的框图。
具体实施方式
下面就结合附图对本发明的各个优选实施例进行详细的说明。
<训练神经网络声学模型的方法>
图1是根据本发明的一个实施方式的训练神经网络声学模型的方法的流程图。
如图1所示,首先,在步骤s101中,基于训练数据10,计算与标注的音素状态不同的音素状态的得分。训练数据10包括训练语音和标注的音素状态。
在本实施方式中,可以利用本领域知晓的或未来开发的任何给音素状态打分的模型或方法获得音素状态的得分,本发明对此没有任何限制。
在本实施方式中,优选,基于音素状态与标注的音素状态之间的相似度和音素状态和标注的音素状态之间的距离中的至少一个,计算音素状态的得分。相似度是表示音素状态和标注的音素状态之间的相似程度,可以利用本领域知晓的任何方法计算相似度,相似度越高,得分越高。距离是表示音素状态和标注的音素状态之间的相近程度,可以利用本领域知晓的任何方法计算距离,距离越近,得分越高。
另外,也可以基于训练数据10和训练好的神经网络声学模型,计算音素状态的得分。训练好的神经网络声学模型可以是利用本领域知晓的任何训练方法进行训练得到的神经网络声学模型。
对于给定的训练数据10,优选通过向前传播,可以得到各个音素状态的得分。
接着,在步骤105,将得分大于预定阈值的音素状态和上述标注的音素状态聚集。在本实施方式中,阈值可以基于实际需要进行设定,通过设定阈值来控制聚集的音素状态的数量。
另外,在本实施方式中,优选利用音素状态的决策树,对得分大于预定阈值的音素状态进行过滤。具体地,如果一些音素状态与标注的音素状态不在同一个决策树上,则将其过滤掉。
另外,也可以在计算得分之前,将与标注的音素状态不在同一个决策树上的音素状态过滤掉,而只计算与标注的音素状态在同一个决策树上的音素状态的得分,这样可以降低计算得分的计算量,提高计算效率。
接着,在步骤s110,使上述聚集的音素状态分享上述标注的音素状态的概率。优选,基于预定的分享比例和上述聚集的音素状态的得分,分享上述标注的音素状态的概率。
最后,在步骤s115,基于上述训练语音和上述聚集的音素状态,训练神经网络声学模型。
在本实施方式中,优选使用交叉熵训练准则,训练神经网络声学模型。通用的训练函数准则由以下的公式(1)表示:
其中i是聚集状态的索引,w(ti)是聚集状态的权重函数,d(ti,yi)是距离函数,用来度量聚集状态的输出和神经网络输出的距离。
在本实施方式中,优选上述交叉熵训练准则包括带权重的交叉熵训练准则。上述带权重的交叉熵训练准则由以下的公式(2)表示:
其中
下面,参考图2详细说明本实施方式的一个实例。图2是根据本发明的一个实施方式的训练神经网络声学模型的方法的一个实例的流程图。
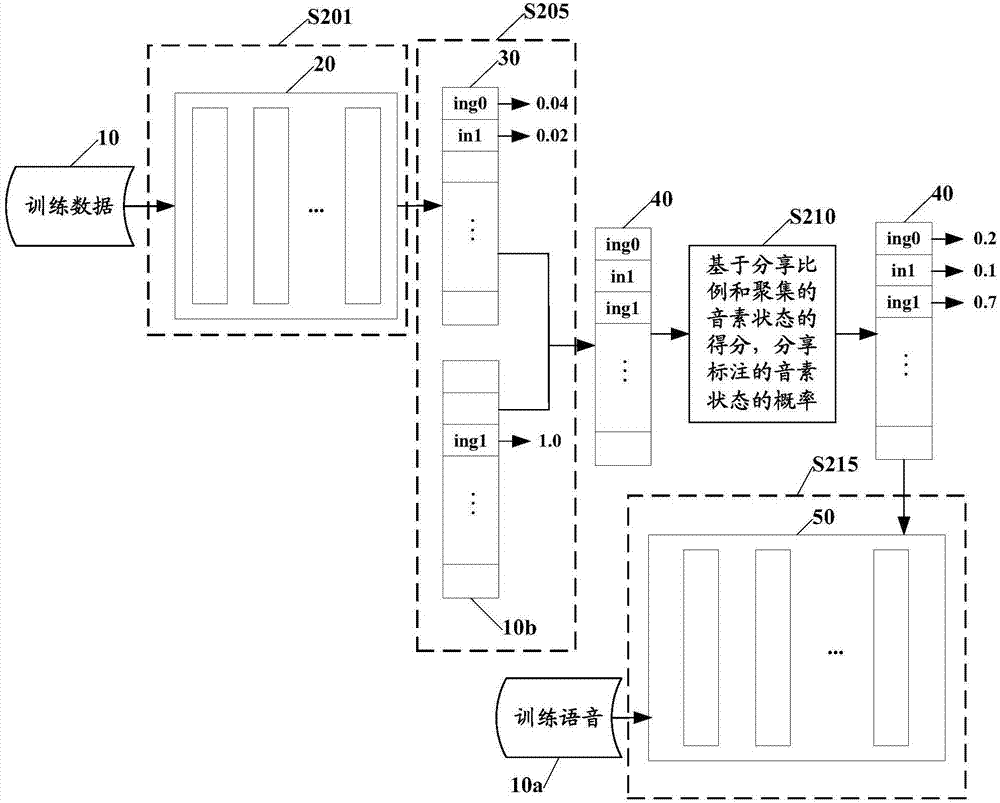
如图2所示,首先,在步骤s201,基于训练数据10和训练好的神经网络声学模型20,例如通过向前传播,计算音素状态的得分,从而得到各音素状态的得分30,例如ing0和in1的得分分别为0.04和0.02。
接着,在步骤s205中,将得分大于预定阈值的音素状态与标注的音素状态10b聚集。例如通过设定阈值将设为ing0和in1这两个音素状态选出,与标注的音素状态ing1聚类,得到聚类的音素状态40。
接着,在步骤s210,基于分享比例和聚集的音素状态的得分,分享标注的音素状态ing1的概率。例如,将分享比例设为0.3,即将标注的音素状态ing1的概率的30%分享给聚类的音素状态中除了标注的音素状态的其他音素状态。对于其他音素状态的概率,可以根据得分比例0.04/0.02计算,得到音素状态ing0和in1的概率分别为0.2和0.1,而标注的音素状态的概率为0.7,最终得到聚类的音素状态ing0、in1和ing1的概率分别为0.2、0.1和0.7。
最后,基于训练数据10中的训练语音10a和聚类的音素状态40及其概率,训练神经网络声学模型50。具体的训练方法如上所述,例如可以利用由上述公式(2)表示的带权重的交叉熵训练准则进行训练。
本实施方式的上述训练神经网络声学模型的方法,将得分高的音素状态与标注的音素状态聚集,聚集的音素状态分享标注的音素状态的概率,能够真实平滑地训练神经网络声学模型。
进而,本实施方式的上述训练神经网络声学模型的方法,基于音素状态与标注的音素状态之间的相似度和音素状态和标注的音素状态之间的距离中的至少一个,计算音素状态的得分,能够将与标注的音素状态相似度高或距离近的音素状态聚集,进而分享标注的音素状态的概率,能够更加真实平滑地训练神经网络声学模型。
另外,本实施方式的上述训练神经网络声学模型的方法,基于训练数据和训练好的神经网络声学模型,计算音素状态的得分,能够基于训练好的的神经网络声学模型选择音素状态进行聚集,进而分享标注的音素状态的概率,能够更加真实平滑地训练神经网络声学模型。
进而,本实施方式的上述训练神经网络声学模型的方法,通过将与标注的音素状态不在同一决策树上的音素状态过滤,能够更加真实平滑地训练神经网络声学模型。
进而,本实施方式的上述训练神经网络声学模型的方法,通过调节带权重的交叉熵训练准则的权重因子和距离因子,能够提高训练的灵活度,能够从多角度学习输出目标的真实的概率分布。
<语音识别方法>
图3是在同一发明构思下的本发明的另一个实施方式的语音识别方法的流程图。下面就结合该图,对本实施方式进行描述。对于那些与前面实施例相同的部分,适当省略其说明。
如图3所示,在步骤s301,输入待识别的语音。待识别的语音可以使任何语音,本发明对此没有任何限制。
接着,在步骤s305,利用由上述训练神经网络声学模型的方法训练得到的神经网络声学模型和语言模型将上述语音识别为文本句。
对语音进行识别的过程中,需要使用声学模型和语言模型。在本实施方式中,声学模型是使用上述训练神经网络声学模型的方法训练得到的神经网络声学模型,语言模型可以本领域知晓的任何语言模型,可以是神经网络语言模型,也可以是其他类型的语言模型。
在本实施方式中,利用神经网络声学模型和语言模型对待识别的语音进行识别的方法,是本领域知晓的任何方法,在此不再赘述。
通过上述语音识别方法,由于利用了使用聚集的音素状态来训练神经网络声学模型的方法得到的神经网络声学模型,由此能够提高语音识别的精度。
<训练神经网络声学模型的装置>
图4是在同一发明构思下的根据本发明的另一个实施方式的训练神经网络声学模型的装置的框图。下面就结合该图,对本实施方式进行描述。对于那些与前面实施方式相同的部分,适当省略其说明。
如图4所示,本实施方式的训练神经网络声学模型的装置400,包括:计算单元401,其基于包括训练语音和标注的音素状态的训练数据10,计算与上述标注的音素状态不同的音素状态的得分;聚集单元405,其将得分大于预定阈值的音素状态和上述标注的音素状态聚集;分享单元410,其使上述聚集的音素状态分享上述标注的音素状态的概率;和训练单元415,其基于上述训练语音和上述聚集的音素状态,训练神经网络声学模型
在本实施方式中,计算单元401,基于训练数据10,计算与标注的音素状态不同的音素状态的得分。训练数据10包括训练语音和标注的音素状态。
在本实施方式中,可以利用本领域知晓的或未来开发的任何给音素状态打分的模型或方法获得音素状态的得分,本发明对此没有任何限制。
在本实施方式中,优选,基于音素状态与标注的音素状态之间的相似度和音素状态和标注的音素状态之间的距离中的至少一个,计算音素状态的得分。相似度是表示音素状态和标注的音素状态之间的相似程度,可以利用本领域知晓的任何方法计算相似度,相似度越高,得分越高。距离是表示音素状态和标注的音素状态之间的相近程度,可以利用本领域知晓的任何方法计算距离,距离越近,得分越高。
另外,也可以基于训练数据10和训练好的神经网络声学模型,计算音素状态的得分。训练好的神经网络声学模型可以是利用本领域知晓的任何训练方法进行训练得到的神经网络声学模型。
对于给定的训练数据10,优选通过向前传播,可以得到各个音素状态的得分。
在本实施方式中,聚集单元405,将得分大于预定阈值的音素状态和上述标注的音素状态聚集。在本实施方式中,阈值可以基于实际需要进行设定,通过设定阈值来控制聚集的音素状态的数量。
另外,在本实施方式中,优选利用音素状态的决策树,对得分大于预定阈值的音素状态进行过滤。具体地,如果一些音素状态与标注的音素状态不在同一个决策树上,则将其过滤掉。
另外,也可以在计算得分之前,将与标注的音素状态不在同一个决策树上的音素状态过滤掉,而只计算与标注的音素状态在同一个决策树上的音素状态的得分,这样可以降低计算得分的计算量,提高计算效率。
在本实施方式中,分享单元410,使上述聚集的音素状态分享上述标注的音素状态的概率。优选,基于预定的分享比例和上述聚集的音素状态的得分,分享上述标注的音素状态的概率。
在本实施方式中,训练单元415,基于上述训练语音和上述聚集的音素状态,训练神经网络声学模型。
在本实施方式中,优选使用交叉熵训练准则,训练神经网络声学模型。通用的训练函数准则由以下的公式(1)表示:
其中i是聚集状态的索引,w(ti)是聚集状态的权重函数,d(ti,yi)是距离函数,用来度量聚集状态的输出和神经网络输出的距离。
在本实施方式中,优选上述交叉熵训练准则包括带权重的交叉熵训练准则。上述带权重的交叉熵训练准则由以下的公式(2)表示:
其中
下面,参考图2详细说明本实施方式的一个实例。图2是根据本发明的一个实施方式的训练神经网络声学模型的装置进行训练的一个实例。
如图2所示,计算单元401基于训练数据10和训练好的神经网络声学模型20,例如通过向前传播,计算音素状态的得分,从而得到各音素状态的得分30,例如ing0和in1的得分分别为0.04和0.02。
聚类单元405将得分大于预定阈值的音素状态与标注的音素状态10b聚集。例如通过设定阈值将设为ing0和in1这两个音素状态选出,与标注的音素状态ing1聚类,得到聚类的音素状态40。
分享单元410基于分享比例和聚集的音素状态的得分,分享标注的音素状态ing1的概率。例如,将分享比例设为0.3,即将标注的音素状态ing1的概率的30%分享给聚类的音素状态中除了标注的音素状态的其他音素状态。对于其他音素状态的概率,可以根据得分比例0.04/0.02计算,得到音素状态ing0和in1的概率分别为0.2和0.1,而标注的音素状态的概率为0.7,最终得到聚类的音素状态ing0、in1和ing1的概率分别为0.2、0.1和0.7。
训练单元415基于训练数据10中的训练语音10a和聚类的音素状态40及其概率,训练神经网络声学模型50。具体的训练方法如上所述,例如可以利用由上述公式(2)表示的带权重的交叉熵训练准则进行训练。
本实施方式的上述训练神经网络声学模型的装置,将得分高的音素状态与标注的音素状态聚集,聚集的音素状态分享标注的音素状态的概率,能够真实平滑地训练神经网络声学模型。
进而,本实施方式的上述训练神经网络声学模型的装置,基于音素状态与标注的音素状态之间的相似度和音素状态和标注的音素状态之间的距离中的至少一个,计算音素状态的得分,能够将与标注的音素状态相似度高或距离近的音素状态聚集,进而分享标注的音素状态的概率,能够更加真实平滑地训练神经网络声学模型。
另外,本实施方式的上述训练神经网络声学模型的装置,基于训练数据和训练好的神经网络声学模型,计算音素状态的得分,能够基于训练好的的神经网络声学模型选择音素状态进行聚集,进而分享标注的音素状态的概率,能够更加真实平滑地训练神经网络声学模型。
进而,本实施方式的上述训练神经网络声学模型的装置,通过将与标注的音素状态不在同一决策树上的音素状态过滤,能够更加真实平滑地训练神经网络声学模型。
进而,本实施方式的上述训练神经网络声学模型的装置,通过调节带权重的交叉熵训练准则的权重因子和距离因子,能够提高训练的灵活度,能够从多角度学习输出目标的真实的概率分布。
<语音识别装置>
图5是在同一发明构思下的根据本发明的另一个实施方式的语音识别装置的框图。下面就结合该图,对本实施方式进行描述。对于那些与前面实施方式相同的部分,适当省略其说明。
如图5所示,本实施方式的语音识别装置500包括:输入单元501,其输入待识别的语音60;语音识别单元505,其利用由上述训练神经网络声学模型的装置400训练得到的神经网络声学模型和语言模型将上述语音识别为文本句
在本实施方式中,输入单元501,输入待识别的语音。待识别的语音可以使任何语音,本发明对此没有任何限制。
语音识别单元505,利用由上述训练神经网络声学模型的装置400训练得到的神经网络声学模型和语言模型将上述语音识别为文本句。
对语音进行识别的过程中,需要使用声学模型和语言模型。在本实施方式中,声学模型是使用上述训练神经网络声学模型的装置400训练得到的神经网络声学模型,语言模型可以本领域知晓的任何语言模型,可以是神经网络语言模型,也可以是其他类型的语言模型。
在本实施方式中,利用神经网络声学模型和语言模型对待识别的语音进行识别的方法,是本领域知晓的任何方法,在此不再赘述。
通过上述语音识别装置500,由于利用了使用聚集的音素状态来训练神经网络声学模型的装置400得到的神经网络声学模型,由此能够提高语音识别的精度。
以上虽然通过一些示例性的实施方式详细地描述了本发明的训练神经网络声学模型的方法、训练神经网络声学模型的装置、语言识别方法以及语音识别装置,但是以上这些实施方式并不是穷举的,本领域技术人员可以在本发明的精神和范围内实现各种变化和修改。因此,本发明并不限于这些实施方式,本发明的范围仅由所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!