基于语音相似度的语音评测方法及系统与流程
本发明涉及语音评测领域,特指一种基于语音相似度的语音评测方法及系统。
背景技术:
语音信号处理技术是语音处理和语音识别领域中的一个重要分支,也是现今语音识别和语音评价系统的主要核心技术。随着科技的发展,语音信号处理技术已深入到各个领域,包括语言学习以及语音自动评分,而在语言学习和自动评分中,运用语音信号处理的目的是将最新的语音技术于当前的教学和学习方法结合,建立辅助语言学习的系统或者语音智能评分系统。
对于语音评测的研究,目前大多数的评测方法或系统均专注于如何提高语音评测的准确性,即提高评测结果的准确度,以实现对发音质量的公正、客观、高效的评测。但是评测结果是否准确对学习者的语言学习并没有提供直接的帮助,其仅能更为客观的反应学习者目前的口语水平,不能提高口语水平和语言学习效果。
技术实现要素:
本发明的目的在于克服现有技术的缺陷,提供一种基于语音相似度的评测方法及系统,解决现有的评测系统不能为学习者的语言学习提供直接帮助和不能提高口语水平及语言学习效果的问题。
实现上述目的的技术方案是:
本发明提供了一种基于语音相似度的语音评测方法,包括如下步骤:
提供训练数据集,所述训练数据集包括训练参照语音数据、与所述训练参照语音数据对应的训练模仿语音数据以及所述训练参照语音数据和所述训练模仿语音数据的相似度评分值;
利用所述训练数据集对动态时间规整算法和支持向量顺序回归算法进行算法训练,以获得相似度评分模型;
提供参照语音信息;
录制模仿朗读所述参照语音信息的模仿语音信息;
提取所述参照语音信息中的参照语音特征序列集和所述模仿语音信息中的模仿语音特征序列集;以及
向所述相似度评分模型输入所述参照语音特征序列集和所述模仿语音特征序列集,获得所述模仿语音信息和所述参照语音信息的相似度评分值并输出。
本发明提出了一种语音相似度的评测方法,能够直观的为学习者给出相似度的评分,为语言学习的模仿学习方法提供了有效的反馈,能够促进学习者在语言学习中反复模仿练习,以提高学习者的语言学习水平和学习效果,进而为学习者的语音学习提供直接的帮助。本发明的语音相似度的评测方法在对发音正确性进行考核的基础上,增加了对发音模仿程度的评估,可帮助用户有针对性的进行模仿练习,提高发音水平。
本发明基于语音相似度的语音评测方法的进一步改进在于,所述训练参照语音数据和所述训练模仿语音数据包括语音内容特征序列、语音音调特征序列、语音时长特征序列、语音停顿特征序列以及语音重读特征序列;
进行算法训练包括:
利用所述训练参照语音数据和所述训练模仿语音数据中的语音音调特征序列、语音时长特征序列、语音停顿特征序列以及语音重读特征序列对所述动态时间规整算法进行算法训练,以使得通过所述动态时间规整算法获得所述训练参照语音数据和所述训练模仿语音数据之间的语音音调距离、语音时长距离、语音停顿距离以及语音重读距离;
利用所述训练参照语音数据和所述训练模仿语音数据中的语音内容特征序列、所述训练参照语音数据和所述训练模仿语音数据的相似度评分值、所获得的语音音调距离、语音时长距离、语音停顿距离以及语音重读距离对所述支持向量顺序回归算法进行算法训练。
本发明基于语音相似度的语音评测方法的进一步改进在于,在进行算法训练时,为所述动态时间规整算法设定以时间帧顺序依序进行计算的约束条件。
本发明基于语音相似度的语音评测方法的进一步改进在于,提取所述参照语音信息中的参照语音特征序列集和所述模仿语音信息中的模仿语音特征序列集,包括:
对所述参照语音信息进行语音识别以获得对应的语音内容特征序列、语音停顿特征序列以及语音时长特征序列并加入到参照语音特征序列集中;
对所述模仿语音信息进行语音识别以获得对应的语音内容特征序列、语音停顿特征序列以及语音时长特征序列并加入到模仿语音特征序列集中。
本发明基于语音相似度的语音评测方法的进一步改进在于,提取所述参照语音信息中的参照语音特征序列集和所述模仿语音信息中的模仿语音特征序列集,还包括:
对所述参照语音信息进行基频提取以获得对应的语音音调特征序列并加入到参照语音特征序列集中;
对所述参照语音信息进行能量提取以获取对应的语音重读特征序列并加入到参照语音特征序列集中;
对所述模仿语音信息进行基频提取以获得对应的语音音调特征序列并加入到模仿语音特征序列集中;
对所述模仿语音信息进行能量提取以获取对应的语音重读特征序列并加入到模仿语音特征序列集中。
本发明还提供了一种基于语音相似度的语音评测系统,包括:
数据存储模块,用于存储参照语音信息;
语音播报模块,与所述数据存储模块连接,用于播报所述数据存储模块中存储的参照语音信息;
语音获取模块,用于录制模仿朗读所述语音播报模块播报的参照语音信息的模仿语音信息;
特征提取模块,与所述语音播报模块和所述语音获取模块连接,用于对所述语音播报模块所播报的参照语音信息和所述语音获取模块所获取的模仿语音信息进行特征提取,以获得对应的参照语音特征序列集和模仿语音特征序列集;以及
评分模块,与所述特征提取模块连接,所述评分模块接收所述特征提取模块获得的参照语音特征序列集和模仿语音特征序列集,并计算得出所述模仿语音信息和所述参照语音信息的相似度评分值。
本发明基于语音相似度的语音评测系统的进一步改进在于,所述评分模块内建立有相似度评分模型,所述相似度评分模型通过训练数据集对动态时间规整算法和支持向量顺序回归算法进行算法训练而建立,所述训练数据集包括训练参照语音数据、与所述训练参照语音数据对应的训练模仿语音数据以及所述训练参照语音数据和所述训练模仿语音数据的相似度评分值;
所述评分模块将所述的参照语音特征序列集和模仿语音特征序列集后输入到所述相似度评分模块以获得所述模仿语音信息和所述参照语音信息的相似度评分值。
本发明基于语音相似度的语音评测系统的进一步改进在于,所述训练参照语音数据和所述训练模仿语音数据包括语音内容特征序列、语音音调特征序列、语音时长特征序列、语音停顿特征序列以及语音重读特征序列;
通过所述训练参照语音数据和所述训练模仿语音数据中的语音音调特征序列、语音时长特征序列、语音停顿特征序列以及语音重读特征序列对所述动态时间规整算法进行算法训练,以使得通过所述动态时间规整算法获得所述训练参照语音数据和所述训练模仿语音数据之间的语音音调距离、语音时长距离、语音停顿距离以及语音重读距离;
通过所述训练参照语音数据和所述训练模仿语音数据中的语音内容特征序列、所述训练参照语音数据和所述训练模仿语音数据的相似度评分值、所获得的语音音调距离、语音时长距离、语音停顿距离以及语音重读距离对所述支持向量顺序回归算法进行算法训练,从而于所述评分模块内建立了相似度评分模型。
本发明基于语音相似度的语音评测系统的进一步改进在于,所述动态时间规整算法在进行算法训练时,设定有以时间帧顺序依序进行算法训练的约束条件。
本发明基于语音相似度的语音评测系统的进一步改进在于,所述特征提取模块包括语音识别子模块、基频提取子模块、能量提取子模块以及序列缓存子模块;
所述序列缓存子模块内存储有参照语音特征序列集和模仿语音特征序列集;
所述语音识别子模块用于对所述参照语音信息进行语音识别以获得对应的语音内容特征序列、语音停顿特征序列以及语音时长特征序列并写入到所述参照语音特征序列集中;还用于对所述模仿语音信息进行语音识别以获得对应的语音内容特征序列、语音停顿特征序列以及语音时长特征序列并写入到所述模仿语音特征序列集中;
所述基频提取子模块用于对所述参照语音信息进行基频提取以获得对应的语音音调特征序列并写入到所述参照语音特征序列集中;还用于对所述模仿语音信息进行基频提取以获得对应的语音音调特征序列并写入到模仿语音特征序列集中;
所述能量提取子模块用于对所述参照语音信息进行能量提取以获取对应的语音重读特征序列并写入到所述参照语音特征序列集中;还用于对所述模仿语音信息进行能量提取以获取对应的语音重读特征序列并写入到模仿语音特征序列集中。
附图说明
图1为本发明基于语音相似度的语音评测系统的系统图。
图2为本发明基于语音相似度的语音评测方法及系统的相似度评测流程图。
图3为本发明基于语音相似度的语音评测方法及系统中特征提取的流程图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明。
本发明提供了一种基于语音相似度的语音评测方法及系统,实现了自动化的相似度评分。为模仿学习提供帮助,对于语言学习来讲,模仿学习对语言发音练习具有显著的帮助效果,但是目前现有的评测系统都仅是针对发音质量进行公正客观的评测,而不能直观的为发音模仿程度给出评估结果,对于模仿学习方法没有直接帮助。而本发明的基于语音相似度的语音评测方法及系统,针对语音韵律特征,感知两条语音相似程度,给出相似度评分,能够给学习者的模仿学习提供有效直观的反馈,为语言学习提供了一种新的学习方法,即模仿练习学习。有效的提高学习者的发音水平和学习效果。下面结合附图对本发明基于语音相似度的语音评测方法及系统进行说明。
如图1所示,本发明的基于语音相似度的语音评测系统包括有数据存储模块11、语音播报模块12、语音获取模块13、特征提取模块14、评分模块15,数据存储模块11与语音播报模块12连接,语音播报模块12和语音获取模块13与特征提取模块14连接,特征提取模块14与评分模块15连接。
数据存储模块11用于存储参照语音信息,在数据存储模块11中建立有用于发音练习的发音练习数据库,该发音练习数据库中存储复数个参照语音信息,该参照语音信息为音频格式,可通过音频播放器进行播放,以供学习者进行模仿。
语音播报模块12与数据存储模块11连接,该语音播报模块12用于播报数据存储模块11中存储的参照语音信息给学习者,学习者通过聆听播报的参照语音信息而进行模仿发音练习。
语音获取模块13用于录制模仿朗读语音播报模块12播报的参照语音信息的模仿语音信息,该语音播报模块12在播报完成后形成录制获取指令发送给语音获取模块13,以启动语音获取模块13,语音获取模块13录制学习者的朗读声音形成模仿语音信息。该语音获取模块13可以为麦克风,能够录制来自学习者的语音。
特征提取模块14用于对语音播报模块12所播报的参照语音信息进行特征提取,还对语音获取模块13所获取的模仿语音信息进行特征提取,以获得对应参照语音信息的参照语音特征序列集和对应模仿语音信息的模仿语音特征序列集,该参照语音特征序列集和模仿语音特征序列集中包括有语音韵律特征,通过对两个语音韵律特征进行分析比对就能够得到两条语音信息的相似度评分值。
评分模块15接收特征提取模块获得的参照语音特征序列集合模仿语音特征序列集,并计算得出模仿语音信息和参照语音信息的相似度评分值。该得到的相似度评分值直接反馈给模仿学习者,对模仿学习者的模仿练习起到评估的作用,可帮助学习者有针对性的进行模仿练习,且通过模仿练习使得学习者的发音越来越像参照语音(标准发音或者老师的发音),有效提高了发音水平,为发音练习提供了新的模仿学习方法。
评分模块内建立有相似度评分模型,该相似度评分模型用于在输入模仿语音特征序列集和参照语音特征序列集后,输出模仿语音信息和参照语音信息的相似度评分值。评分模块在接收到参照语音特征序列集合模仿语音特征序列集后,将参照语音特征序列集合模仿语音特征序列集输入到相似度评分模型中,就能够获得模仿语音信息和参照语音信息的相似度评分值。
该相似度评分模型通过训练数据集对动态时间规整算法(DTW,Dynamic Time Warping)和支持向量顺序回归算法(SVOR,Support Vector Ordinal Regression)进行算法训练而建立,训练数据集包括有训练参照语音数据、与训练参照语音数据对应的训练模仿语音数据以及训练参照语音数据和模仿语音数据的相似度评分值,该训练参照语音数据和模仿语音数据的相似度评分值为人工标注,利用训练数据集进行算法训练以获得相似度评分模型。在进行算法训练时,训练参照语音数据和训练模仿语音数据包括有语音内容特征序列、语音音调特征序列、语音时长特征序列、语音停顿特征序列以及语音重读特征序列,其中的语音内容特征序列是指语音数据中的文本内容,即以单词为单位的识别结果文本序列;语音音调特征序列指人发音语调的变化情况,音调特征序列包括标准化的基频序列、风格化的基频序列、标准化基频序列的一阶差分、以及风格化基频序列的一阶差分,语音音调特征序列通过基频提取来实现,该基频提取是指对每一帧语音提取其基频信息;语音时长特征序列指单词或音节的发音时间长短情况,语音时长特征序列包括单词绝对发音时长序列和单词相对发音时长序列,单词绝对发音时长序列指识别结果中每个单词发音时长所构成的序列,单词相对发音时长序列指每个单词发音时长占总发音时长的比例的序列;语音停顿特征序列是指发音和静音交错情况,即静音和发音间隔时长序列,因为一条语音是由静音段和发音段交错组成的,将每个静音段也当作一个单词(SIL,silence,静音),计算其持续时间当作时长,与每个单词的发音时长共同构成一个序列;语音重读特征序列是指哪些单词为了突出强调而重读,重读的声音具有较大的力度和音量,语音重读特征序列包括能量序列和能量序列的一阶差分。利用训练参照语音数据和训练模仿语音数据中的语音音调特征序列、语音时长特征序列、语音停顿特征序列以及语音重读特征序列对所述动态时间规整算法进行算法训练,以使得通过所述动态时间规整算法获得所述训练参照语音数据和所述训练模仿语音数据之间的语音音调距离、语音时长距离、语音停顿距离以及语音重读距离,由于语音音调特征序列、语音时长特征序列、语音停顿特征序列以及语音重读特征序列都是时间序列,可用“距离”来衡量两个序列的相似度,采用动态时间规整算法从两个不同长度序列中找到相似的匹配点,从而计算匹配点的距离即获得了两个序列的距离。为了提高动态时间规整算法的鲁棒性,为动态时间规整算法设定约束条件,令动态时间规整算法以时间帧顺序依序进行算法训练,避免动态时间规整算法在查找匹配点时返回已遍历过的时间帧进行查找。约束了动态时间规整算法的连续性和单调性,提高了算法的鲁棒性。对于训练参照语音数据和训练模仿语音数据中的语音内容特征序列的内容距离,可通过两者的直接比对而获得。利用训练参照语音数据和训练模仿语音数据中的语音内容特征序列、训练参照语音数据和训练模仿语音数据的相似度评分值、所获得的语音音调距离、语音时长距离、语音停顿距离以及语音重读距离对支持向量顺序回归算法进行算法训练,该支撑向量顺序回归算法作为分数映射模型,针对两个序列的距离给出合适的相似度评分值。通过对动态时间规整算法和支持向量顺序回归算法的算法训练,在评分模块内建立相似度评分模型。
该相似度评分模型通过相似度特征提取和相似度得分计算得到相似度评分值,其中的相似度特征提取是基于从音频和语音识别结果中提取出各个语音特征序列,进一步提取相似度相关特征,具体包括从模仿语音信息和参照语音信息中分别提取出所有语音特征序列,该所有语音特征序列包括语音内容特征序列、语音音调特征序列、语音时长特征序列、语音停顿特征序列以及语音重读特征序列;计算模仿语音信息和参照语音信息的语音内容特征序列之间的Levenshtein距离,作为一维特征;对于其他序列特征,均采用DTW计算模仿语音信息和参照语音信息的最小匹配距离,设参照语音信息的特征序列为R,模仿语音信息的特征序列为U,则DTW动态规划目标函数为:Gi,j=di,j+min{Gi,j-1,Gi-1,j,Gi-1,j-1+di,j}
其中i为参照语音特征序列的下标,j为模仿语音信息语音特征序列的下标,Gi,j为累积距离,di,j=|Ri-Uj|
每一对特征序列均可得到一个最小匹配距离,作为一维相似度特征,这样一共得到10维相似度特征。
相似度得分计算,在相似度特征和专家打分之间建立一种对应关系,通过训练以得到相似度得分计算的模型,该模型可以是任何一种回归、分类模型。常用的线性回归模型对于相似度特别高或者特别差的样本不能准确表达,因此我们采用SVOR模型,可以克服线性回归的缺点。
特征提取模块14包括语音识别子模块、基频提取子模块、能量提取子模块以及序列缓存子模块;序列缓存子模块内存储有参照语音特征序列集和模仿语音特征序列集;语音识别子模块用于对参照语音信息进行语音识别,识别出语音内的文本内容、语音中单词音素边界,从而获得对应该参照语音信息的语音内容特征序列、语音停顿特征序列和语音时长特征序列,语音内容特征序列为以单词为单位的识别结果文本序列;语音停顿特征序列包括静音、发音间隔时长序列;语音时长特征序列包括单词绝对发音时长序列和单词相对发音时长序列,可通过如下公式计算:
其中D为单词绝对发音时长序列,D′为单词相对发音时长序列,N为识别结果中单词总个数。语音停顿特征序列通过语音识别检测出哪些语音段是发音段,哪些语音段是静音段,这种发音段和静音段交错代表了人说话的节奏,即语音停顿特征序列,语音时长特征序列利用语音识别技术和强制切分算法,可以获得单词和音素的起止时间点,进一步计算出单词和音素的发音时间长度。语音识别子模块将获得的对应该参照语音信息的语音内容特征序列、语音停顿特征序列和语音时长特征序列写入到序列缓存子模块中的参照语音特征序列集中。语音识别子模块还用于对模仿语音信息进行语音识别以获得对应的语音内容特征序列、语音停顿特征序列以及语音时长特征序列并写入到模仿语音特征序列集中。基频提取子模块用于对参照语音信息进行基频提取以获得对应的语音音调特征序列并写入到参照语音特征序列集中,利用基频提取技术从语音中获得基频曲线,以代表语音音调特征序列。基频提取子模块还用于对模仿语音信息进行基频提取以获得对应的语音音调特征序列并写入到模仿语音特征序列集中。基频提取是指对每一帧语音提取其基频信息,算法采用基于自相关的基频提取算法,该算法计算速度快,得到基频准确稳定。根据语音的特点,频率区间设为60Hz至600Hz。提取出的基频需要进行如下后处理:提取出来的基频存在一些错误点,基于自相关的基频提取算法会出现倍频和半频错误,基频序列中大部分是准确的,以此为基准可以修正提取结构的倍频和半频错误。提取出的基频曲线不是连续光滑的,还需要对其进行插值和平滑。插值算法采用线性插值,平滑算法采用3阶巴特沃斯低通滤波器。人耳对声音频率的感知是对数均匀的,因此需要先将基频F0转至对数域,即Semitone(半音程),
其中Fref为参考频率,一般参考频率取20Hz。标准化基频序列是为了消除不同人群固有的基频差异,使其具有可比性。这里采用Z-score标准化:
其中F0为基频序列中一点,μ为基频序列的均值,σ为基频序列的方差。发音的最小单位是音节。风格化基频序列是在标准化的基础上,按语音识别结果中的音节边界信息切分基频序列,每个切分片段取其中位数,再将其连接成一个新的序列。风格化不考虑每个音节内部的基频变化细节,只关心语音基频变化的整体趋势。基频序列本身的相对变化也是描述音调编号的重要特征,因此分别取标准化基频序列的一阶差分、风格化基频序列的一阶差分作为两个特征序列。能量提取子模块用于对参照语音信息进行能量提取以获得对应的语音重读特征序列并写入到参照语音特征序列集中,重读特征可从语音中提取能量变化曲线,能量代表人说话的力度和音量,分析能量曲线可获得哪些单词是强度重读的,哪些是非重读的。能量提取子模块还用于对模仿语音信息进行能力提取以获取对应的语音重读特征序列并写入到模仿语音特征序列集中。能量提取是指对每一帧语音提取其能量:
其中E为一帧语音的能量,A为音频振幅序列,N为帧长。能量序列本身的相对变化也是描述重读编号的重要特征,因此取能量序列的一阶差分作为一个特征序列。
下面对本发明提供的一种基于语音相似度的语音评测方法进行说明。
本发明基于语音相似度的语音评测方法,包括如下步骤:
提供训练数据集,该训练数据集包括训练参照语音数据、与训练参照语音数据对应的训练模仿语音数据以及训练参照语音数据和训练模仿语音数据的相似度评分值;该训练参照语音数据和训练模仿语音数据的相似度评分值根据人工标注获得;
利用训练数据集对动态时间规整算法和支持向量顺序回归算法进行算法训练,以获得相似度评分模型;
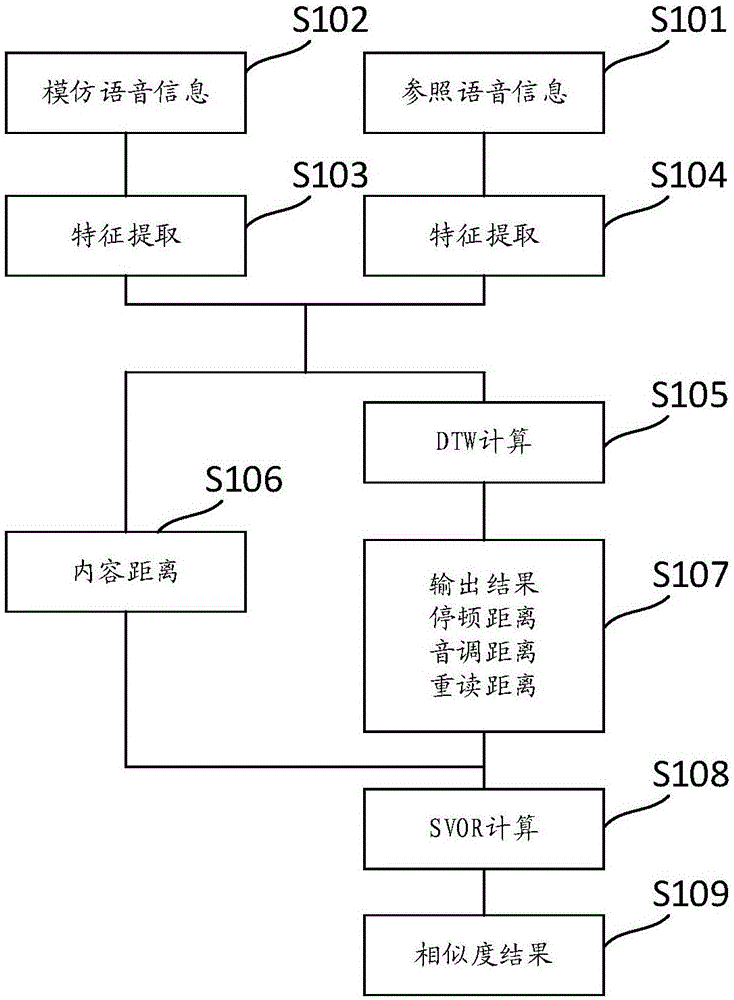
如图1所示,执行步骤S101,参照语音信息。提供参照语音信息;并将参照语音信息播放给学习者聆听以供其模仿练习;
执行步骤S102,模仿语音信息。录制模仿朗读参照语音信息的模仿语音信息;在学习者模仿朗读参照语音信息时对该模仿语音信息进行录制获取;
执行步骤S103和步骤S104,特征提取。提取参照语音信息中的参照语音特征序列集和模仿语音信息中的模仿语音特征序列集;
执行步骤S105至步骤S109,向相似度评分模型输入参照语音特征序列集和模仿语音特征序列集,获得模仿语音信息和参照语音信息的相似度评分值并输出。
作为本发明的一较佳实施方式,训练参照语音数据和训练模仿语音数据包括语音内容特征序列、语音音调特征序列、语音时长特征序列、语音停顿特征序列以及语音重读特征序列;其中的语音内容特征序列是指语音数据中的文本内容,语音音调特征序列指人发音语调的变化情况,语音时长特征序列指单词或音节的发音时间长短情况,语音停顿特征序列是指发音和静音交错情况,语音重读特征序列是指哪些单词为了突出强调而重读,重读的声音具有较大的力度和音量。
利用训练数据集进行算法训练包括:
利用训练参照语音数据和训练模仿语音数据中的语音音调特征序列、语音时长特征序列、语音停顿特征序列以及语音重读特征序列对动态时间规整算法进行算法训练,以使得通过动态时间规整算法获得训练参照语音数据和训练模仿语音数据之间的语音音调距离、语音时长距离、语音停顿距离以及语音重读距离,结合图1中步骤S105和步骤S107所示;由于语音音调特征序列、语音时长特征序列、语音停顿特征序列以及语音重读特征序列都是时间序列,可用“距离”来衡量两个序列的相似度,采用动态时间规整算法从两个不同长度序列中找到相似的匹配点,从而计算匹配点的距离即获得了两个序列的距离。为了提高动态时间规整算法的鲁棒性,为动态时间规整算法设定以时间帧顺序依序进行计算的约束条件,令动态时间规整算法以时间帧顺序依序进行算法训练,避免动态时间规整算法在查找匹配点时返回已遍历过的时间帧进行查找。约束了动态时间规整算法的连续性和单调性,提高了算法的鲁棒性。
利用训练参照语音数据和训练模仿语音数据中的语音内容特征序列、训练参照语音数据和训练模仿语音数据的相似度评分值、所获得的语音音调距离、语音时长距离、语音停顿距离以及语音重读距离对支持向量顺序回归算法进行算法训练。该支撑向量顺序回归算法作为分数映射模型,针对两个序列的距离给出合适的相似度评分值。
作为本发明的一较佳实施方式,提取参照语音信息中的参照语音特征序列集,包括:
如图3所示,执行步骤S201,参照语音信息。提供参照语音信息进行特征提取。执行步骤S202,语音识别,对参照语音信息进行语音识别。执行步骤S205,通过语音识别输出参照语音信息的语音内容特征序列,语音停顿特征序列以及语音时长特征序列并加入到参照语音特征序列集总。语音识别子模块用于对参照语音信息进行语音识别,识别出语音内的文本内容、语音中单词音素边界,从而获得对应该参照语音信息的语音内容特征序列、语音停顿特征序列和语音时长特征序列,语音停顿特征序列通过语音识别检测出哪些语音段是发音段,哪些语音段是静音段,这种发音段和静音段交错代表了人说话的节奏,即语音停顿特征序列,语音时长特征序列利用语音识别技术和强制切分算法,可以获得单词和音素的起止时间点,进一步计算出单词和音素的发音时间长度。执行步骤S203,基频提取,对参照语音信息进行基频提取,执行步骤S206,通过基频提取输出参照语音信息的语音音调特征序列并加入到参照语音特征序列集中。利用基频提取技术从语音中获得基频曲线,以代表语音音调特征序列。执行步骤S204,能量提取,对参照语音信息进行能量提取,执行步骤S207,通过能量提取输出参照语音信息的语音重读特征序列并加入到参照语音特征序列集中。重读特征可从语音中提取能量变化曲线,能量代表人说话的力度和音量,分析能量曲线可获得哪些单词是强度重读的,哪些是非重读的。
作为本发明的一较佳实施方式,提取模仿语音信息中的模仿语音特征序列集,包括:对模仿语音信息进行语音识别以获得对应的语音内容特征序列、语音停顿特征序列以及语音时长特征序列并加入到模仿语音特征序列集中;对模仿语音信息进行基频提取以获得对应的语音音调特征序列并加入到模仿语音特征序列集中;对模仿语音信息进行能量提取以获取对应的语音重读特征序列并加入到模仿语音特征序列集中。
本发明基于语音相似度的语音评测方法及系统的有益效果为:
本发明的语音相似度的评测方法及系统,能够直观的为学习者给出相似度的评分,为语言学习的模仿学习方法提供了有效的反馈,能够促进学习者在语言学习中反复模仿练习,以提高学习者的语言学习水平(口语水平)和学习效果,进而为学习者的语音学习提供直接的帮助。本发明的语音相似度的评测方法在对发音正确性进行考核的基础上,增加了对发音模仿程度的评估,可帮助用户有针对性的进行模仿练习,提高发音水平。
以上结合附图实施例对本发明进行了详细说明,本领域中普通技术人员可根据上述说明对本发明做出种种变化例。因而,实施例中的某些细节不应构成对本发明的限定,本发明将以所附权利要求书界定的范围作为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!