一种语音搜索列表的实现方法与流程
本发明涉及搜索技术领域,尤其是一种语音搜索列表的实现方法。
背景技术:
现有技术中,语音识别系统在进行搜索列表时,无法将列表项的属性关联;或者即使关联,但需要手工排列组合可能的发音。例如,对于第一种情况,在通讯录里有总务科张三和人事科章山,两个人名发音相似,如果用户说“打电话给人事科章山”,语音识别可能会返回“打电话给人事科张三”。这里人名和部门这两个属性没有关联,导致识别出错误的联系人。再例如,对于第二种情况,用户需要在附近的饭店列表中选出“麦当劳(珠江路5000号)”和“肯德基(长江路6000号)”,需要进行排列所有可能的发音序列。比如对于第一个麦当劳,就生成如下发音序列:“麦当劳”,“珠江路麦当劳”,“珠江路5000号麦当劳”,“珠江路5000号”和“珠江路”;对于第二个肯德基,就生成如下发音序列:“肯德基”,“长江路肯德基”,“长江路6000号肯德基”,“长江路6000号”和“长江路”。这种属性关联方法的缺陷为不灵活,程序必须列出所有序列;运算量大,随着列表属性增加,可能的发音序列变得很大。综合以上两种情况,现有技术没有解决好灵活性和复杂性的矛盾。
技术实现要素:
本发明所要解决的技术问题在于,提供一种语音搜索列表的实现方法,可以降低计算复杂性,同时增加了灵活性。
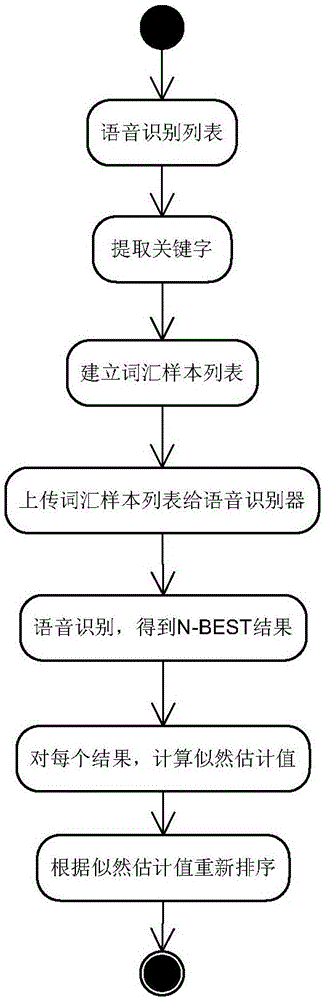
为解决上述技术问题,本发明提供一种语音搜索列表的实现方法,包括如下步骤:
(1)列表预处理:
一个列表,提取每个列表项C的所有属性的关键字,切词且去除重复,得到词汇样本V(v1,v2,…vn),有n个独立的词;
(2)语音识别
将词汇样本V传送给语音识别器,并加载UNIGRAM语言模型,进行语音识别,得到N-BEST结果R,其中每个结果t为识别出的词,w为该词的权重;
(3)计算似然估计值
对每个列表项C,计算其归一化的似然估计值lik(C);
lik(c)=∏reR f(c|r)
f(c|r)=∏ter g(t|c)
其中,a、b为预设的常数,c为一个列表项,r为一个语音识别结果,t为一个识别的词,w为一个识别的词t的权重;
(4)列表搜索;根据列表项的似然估计值重新排序,选出似然估计值最大的列表项。
优选的,步骤(1)中,词汇样本V必须去除重复词汇。
优选的,步骤(2)中,语音识别器装载词汇样本V和UNIGRAM语言模型,识别输入语音数据并输出N-BEST结果。
优选的,步骤(2)中,语音识别器加载的UNIGRAM语言模型是动态生成的,而UNIGRAM语法是固定的,不依赖于列表而变化,每种语言只需有一个UNIGRAM语法。
优选的,步骤(2)中,语音识别器为嵌入式语音识别器或任何支持N-BEST结果的语音识别器。
优选的,步骤(2)中,权重为概率或信任值。
优选的,步骤(2)中,词汇样本V中可以增加常用连接词和介词。
优选的,步骤(3)中,计算似然估计值基于朴素贝叶斯概率模型,并且使用了所有N-BEST结果。
优选的,步骤(3)中,a、b为预设的常数,根据试验数据来设置。
优选的,步骤(3)中,计算似然估计值方法与语音识别器无关。
本发明的有益效果为:很好的解决了语音搜索列表的灵活性和复杂性的矛盾,降低了计算复杂性,同时增加了灵活性。
附图说明
图1是本发明的方法流程示意图。
图2是本发明的语音识别流程示意图。
图3是本发明的已获取N-BEST结果后的实现方法流程示意图。
具体实施方式
如图1和图2所示,一种语音搜索列表的实现方法,包括如下步骤:
(1)列表预处理:
一个列表,提取每个列表项C的所有属性的关键字,切词且去除重复,得到词汇样本V(v1,v2,…vn),有n个独立的词;
(2)语音识别
将词汇样本V传送给语音识别器,进行语音识别,得到N-BEST结果R,其中每个结果t为识别出的词,w为该词的权重;权重为概率或信任值等;N-BEST为一种搜索算法,结果为N个最优路径;
(3)计算似然估计值
对每个列表项C,计算其归一化的似然估计值lik(C);
lik(c)=∏reR f(c|r)
f(c|r)=∏ter g(t|c)
其中,a、b为预设的常数,c为一个列表项,r为一个语音识别结果,t为一个识别的词,w为一个识别的词t的权重;
(4)列表搜索;根据列表项的似然估计值重新排序,选出似然估计值最大的列表项。
如图3所示,为已获取N-BEST结果后的实现方法流程示意图。依次取下一个列表项c,初始化似然估计值lik(c)=1,取下一个N-BEST结果r,取下一个词t;若r包含t,则lik(c)=lik(c)*wt*a;若r不包含t,则lik(c)=lik(c)*wt*b;获得似然估计值lik(c);若还有未取词,则继续取词重复上述步骤;若还有未取的N-BEST结果,则继续取下一个N-BEST结果,重复上述步骤。
以用户需要在列表中使用语音选择一个快餐店为例。用户需要在列表
[{“id”:0,“name”:”麦当劳”,“address”:”珠江路5000号”,“phone”:“555-12345678”},
{“id”:1,“name”:”肯德基”,“address”:”长江路6000号”,“phone”:“555-87654321”}]中使用语音选择一个快餐店,具体步骤如下:
(1)提取关键字,得到列表[“麦当劳”,“珠江路5000号”,“555-12345678”,“肯德基”,“长江路6000号”,“555-87654321”];
(2)切词,并且除去重复,得到词汇样本列表V=[“麦当劳”,“珠江路”,“5000号”,“555-12345678”,“12345678”“肯德基”,“长江路”,“6000号”,“555-87654321”,“87654321”];
(3)将此词汇样本V传给语音识别器,每个语音识别器都有特定的方法;
(4)语音识别,假设用户说“珠江路麦当劳”,得到N-BEST结果R=
{{“珠江路”:0.9,“麦当劳”:0.8},
{{“珠江路”:0.8,“麦当劳”:0.6,“6000号”:0.2},
{“珠江路”:0.7,“肯德基”:0.2,“6000号”:0.1}}
(5)计算似然估计值,假设(a=0.5,b=0.1)
麦当劳的似然估计值lik(0)=(0.5*0.9)*(0.5*0.8)*(0.5*0.8)*(0.5*0.6)*(0.1*0.2)*(0.5*0.7)*(0.1*.0.2)*(0.1*0.1)=3e-8
肯德基的似然估计值lik(1)=(0.1*0.9)*(0.1*0.8)*(0.1*0.8)*(0.1*0.6)*(0.5*0.2)*(0.1*0.7)*(0.5*0.2)*(0.5*0.1)=1e-9;
(6)重新排序,选出似然估计值最大的列表项“麦当劳”,因为麦当劳的似然估计值大于肯德基的似然估计值。
尽管本发明就优选实施方式进行了示意和描述,但本领域的技术人员应当理解,只要不超出本发明的权利要求所限定的范围,可以对本发明进行各种变化和修改。
- 还没有人留言评论。精彩留言会获得点赞!