一种语音起始点和终止点的检测方法与流程
本发明涉及一种检测方法,特别是一种判断语音起始点和终止点的检测方法。
背景技术:
语音识别,也称为自动语音识别(automaticspeechrecognition,asr),其目标是将人类语音转换为计算机可读的文字或指令,是模式识别的一个重要分支。一个完整的语音识别系统一般包括语音信号预处理、特征提取、模型训练、声学模型、语言模型以及自然语言后处理等几大模块。
语音信号预处理阶段可对语音进行降噪、增强以处理原始语音信号,部分消除噪声和不同说话人带来的影响,使处理后的信号更能反映语音的本质特征。
特征参数提取是指从语音信号中提取出有关的特征参数,如语音识别建模中常用的梅尔频率倒谱系数(mel-frequencycepstralcoefficient,mfcc)或滤波器组系数(filterbankcoefficient)等等。
声学模型的主要作用是用来辨识用户发什么样的音。目前占据主流地位的建模方法为深度神经网络模型(dnn/cnn/rnn)等。
语言模型的作用是帮助辨识用户发出的音对应于什么文字,利用前后词汇的搭配信息来选取更为准确的词汇序列。目前主要使用n-gram统计语言模型。
识别器的主要作用是进行搜索,在搜索空间中确定跟用户语音吻合度最高的词序列。比较经典的搜索算法为时间同步的viterbi搜索。
自然语言后处理阶段一般是利用语言知识库或模型进一步提升语音识别的精度。对自然语言的识别和理解。首先必须将连续的讲话分解为词、音素等单位,其次要建立一个理解语义的规则,根据上下文的约束对识别结果进行纠正和修改。
在实际应用过程中,语音端点检测(voiceactivitydetect,vad或者voiceendpointdetect)是语音识别前端(frontend)中一个非常重要的模块,它的重要性可以简要概括如下:
摒除一些非语音信号,如偶发的咳嗽声、键盘敲击声、拍掌声、类似汽车发动机的低频噪声、雷声和雨声等等。这样可以降低语音识别的误识别率,避免后续的误操作。
降低不必要的计算量和系统的功耗水平。对于很多应用场合,如智能玩具和智能家居等,我们多部署嵌入式语音识别系统,控制和降低功耗非常重要。这些场合用户使用语音识别技术的频度不是很高,但识别系统必须随时处于待命状态,一旦用户发出指令,能够及时响应。而待命时的功耗水平控制很严,这些场合,一个复杂度相对较低、准确检测语音端点的vad模块非常重要。
远场支持由于麦克风等拾音设备物理上的限制,一旦说话人和麦克风相距较远(比如5米以上)的时候,录出来的语音信号幅度很小,即使周围环境的噪声水平很低,语音信号也可能淹没在噪声信号中。如果不能把语音信号通过端点检测从背景噪声中分离出来,识别精度是无法保证的。借助于先进的端点检测技术,可以更好地支持远场语音识别。
此外,在现代通信系统中,也使用语音端点技术来检测语音的开始。对于非语音信号,通过端点检测在本地排除,并不发送给远端的接收方。这样可以降低通信中的带宽需求。
现有的方法也存在一些问题,如算法的稳定性不够、抗噪声能力不够强或者计算复杂度过高,不太适合应用需求,上述问题亟待解决。
技术实现要素:
针对现有技术存在的上述问题,本发明的目的在于提供一种语音起始点和终点的检测方法。
本发明提供了一种语音起始点的检测方法,包括以下步骤,
s1,接收输入的待检测语音信号;
s2,对待检测语音信号进行时频变换;
s3,在频域对经步骤s2处理后的信号进行滤波;
s4,对步骤s3处理后的信号进行增强处理;
s5,在频域计算经步骤s4处理后的信号的共振峰的个数以及不同频带的能量占比;
s6,在时域计算经步骤s4处理后的信号的过零交叉率和最大最小幅值比;
s7,通过步骤s5和s6的计算值判定语音信号的起点。
优选地,所述步骤s3中滤波时,选取频带范围为200-2500hz的分量供后续步骤使用。
优选地,所述步骤s4包括以下步骤,
s41,选取待检测语音信号前一段时间的语音信号作为背景信号;
s42,将待检测语音信号减去背景信号的频谱。
优选地,所述步骤s41中选取待检测语音信号前100-150ms的语音信号作为背景信号。
优选地,所述步骤s1采用中滑动窗口协议用于接收待检测的语音信号。
本发明还提供了一种语音终止点的检测方法,包括以下步骤,
sa1,接收输入的待检测语音信号;
sa2,对待检测语音信号进行时频变换;
sa3,在频域对经步骤sa2处理后的信号进行滤波;
sa4,在频域计算经步骤sa3处理后的信号的共振峰的个数以及不同频带的能量占比;
sa5,在时域计算经步骤sa3处理后的信号的过零交叉率和最大最小幅值比;
sa6,通过步骤sa4和sa5的计算值判定语音信号的终点。
优选地,所述步骤sa3中滤波时,选取频带范围为200-2500hz的分量供后续步骤使用。
综上所述,本发明具有以下优点:
本发明的语音起始点和终止点的检测方法,综合了时域和频域的处理方法,检测精度高,同计算复杂程度低,且抗噪能力腔,通过信号增强和特定频带的检测,可以抑制大部分低频信号分量和高频信号分量的干扰,提升鲁棒性。
附图说明
图1为本发明实施例的语音起始点检测方法流程图;
图2为本发明实施例的语音终止点的检测方法流程图。
具体实施方式
下面结合实施方式及附图对本发明作进一步详细、完整地说明。
如图1-2所示,一种语音起始点的检测方法,包括以下步骤,
s1,接收输入的待检测语音信号;
s2,对待检测语音信号进行时频变换;
s3,在频域对经步骤s2处理后的信号进行滤波;
s4,对步骤s3处理后的信号进行增强处理;
s5,在频域计算经步骤s4处理后的信号的共振峰的个数以及不同频带的能量占比;
s6,在时域计算经步骤s4处理后的信号的过零交叉率和最大最小幅值比;
s7,通过步骤s5和s6的计算值判定语音信号的起点。
所述步骤s3中滤波时,选取频带范围为200-2500hz的分量供后续步骤使用。
所述步骤s4包括以下步骤,
s41,选取待检测语音信号前一段时间的语音信号作为背景信号;
s42,将待检测语音信号减去背景信号的频谱。
所述步骤s41中选取待检测语音信号前100-150ms的语音信号作为背景信号。
所述步骤s1采用中滑动窗口协议用于接收待检测的语音信号。
语音起始点的判决使用了背景信号的信息。在带通滤波的基础上进行语音信号增强。经过时频变换后,在频域对信号进行滤波,只选取特定频带的分量供后续分析和处理。选取语音开始前一段时间的语音信号作为背景参考信号,在检测语音端点时,先减去参考信号的频谱,以增强语音信号、提升信噪比和端点检测的抗噪声能力。
在频域计算共振峰的个数,以及不同频带的能量占比。这样可排除金属声乃至频带单一的乐曲声。浊音(voiced)部分有基频和谐波,而频带单一的周期性信号不具备类似特征,即使它们周期性明显,也通不过语音起始点的检测。
在时域通过零交叉率(zerocrossrate)和最大最小幅值比进行判决。对于语音的起始点,我们先找到浊音(voiced)部分,相对于清音(unvoiced)部分,浊音部分幅值更大、周期性强、与背景噪声的区分程度高,辨识的可靠性更高。因此先判决浊音,然后再倒推200~300毫秒作为语音的起始点。对于语音的结束点,主要考虑当前幅值与前400~500毫秒内的最大幅值之比,如果下降明显,则作为语音的结束点。
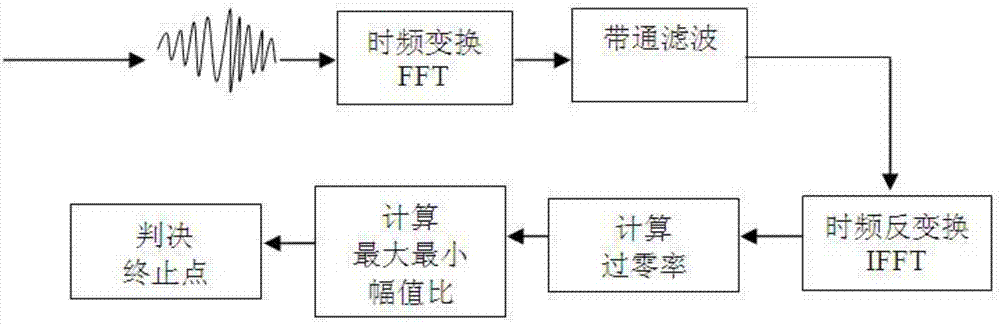
一种语音终止点的检测方法,包括以下步骤,
sa1,接收输入的待检测语音信号;
sa2,对待检测语音信号进行时频变换;
sa3,在频域对经步骤sa2处理后的信号进行滤波;
sa4,在频域计算经步骤sa3处理后的信号的共振峰的个数以及不同频带的能量占比;
sa5,在时域计算经步骤sa3处理后的信号的过零交叉率和最大最小幅值比;
sa6,通过步骤sa4和sa5的计算值判定语音信号的终点。
所述步骤sa3中滤波时,选取频带范围为200-2500hz的分量供后续步骤使用。
语音终止点的检测流程如图2所示。考虑到终止点之前的信号为正常语音信号,不能作为背景参考信号,因此终止点的检测不再进行语音增强,主要使用过零率和最大最小比值。
同时本发明上述实施例仅为说明本发明技术方案之用,仅为本发明技术方案的列举,并不用于限制本发明的技术方案及其保护范围。采用等同技术手段、等同设备等对本发明权利要求书及说明书所公开的技术方案的改进应当认为是没有超出本发明权利要求书及说明书所公开的范围。
- 还没有人留言评论。精彩留言会获得点赞!