一种自然的人机语音交互方法和系统与流程
本发明涉及一种人机语音交互方法和系统,尤其涉及一种自然的人机语音交互方法和系统。
背景技术:
伴随着语音识别、语义理解等自然语言处理技术在近年来的高速发展,以语音为主要交互方式的数字智能助手不断涌现,比如苹果siri、googlenow、微软cortana、亚马逊echo等等。语音作为人机交互的方式在智能手表、智能手机、平板电脑、个人电脑等终端被广泛应用。
当前主流的语音助手的使用流程通常具有如下特征:
1.通常一个终端上的智能语音助手的工作状态分为待命状态和识别状态。
2.处于待命状态的智能语音助手并不会处理用户请求,而处于识别状态的智能语音助手则会接收所有音频信息并识别。
3.处于待命状态的智能语音助手需要通过用户在界面点击或者说出指定词语来唤醒从而进入识别状态。
现有主流系统这样设计的一个主要原因是从语音到文字识别和语义理解目前还是一个相当耗费计算资源的事情,因此大部分的解决方案是基于云端的,如果整个系统一直保持识别状态的话不仅浪费计算资源,也存在巨大的隐私问题。
但是这种语音交互方式存在着诸多限制,使得用户在使用过程中有不自然的感觉,例如:
1.当进入识别状态之后即将用户说的所有内容作为指令,不具备区分一段语音是否为用户请求的能力,容易记录错误信息。
2.受当前的软硬件性能限制,单纯依靠语音信息还无法具备准确的说话人识别的能力,也就是说单一终端无法处理多个用户的请求。
3.工作状态切换过程不自然,尤其是在纯语音场景中用户需要说出指定词汇才能唤醒语音助手。当同一范围内有多个设备都安装有语音助手软件时甚至可能同时被唤醒。
因此,期望获得一种自然的人机语音交互方法,该方法可被应用于人机语音交互,增强人机语音交互体验,使得用户在人机语音交互过程中感觉更加自然。
技术实现要素:
本发明的目的之一是提供一种自然的人机语音交互方法,该方法可被应用于人机语音交互,增强人机语音交互体验,使得用户在人机语音交互过程中感觉更加自然。
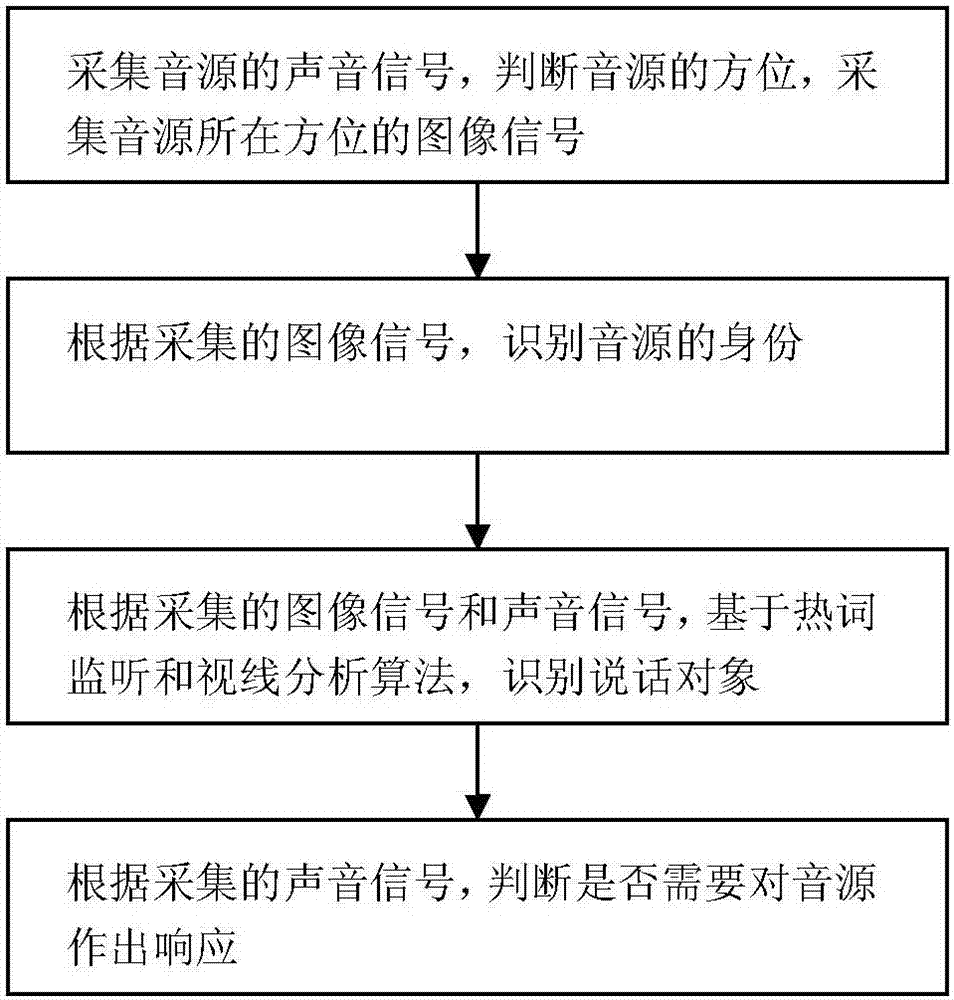
根据上述目的之一,本发明提出了一种自然的人机语音交互方法,其包括步骤:
(1)信号采集:采用麦克风阵列采集音源的声音信号,根据麦克风阵列中不同位置的麦克风采集的声音信号,判断音源的方位,采用摄像头采集音源所在方位的图像信号;
(2)音源身份识别:根据采集的图像信号,识别音源的身份;
(3)说话对象识别:根据采集的图像信号和声音信号,基于热词监听和视线分析算法,识别说话对象;
(4)根据采集的声音信号,判断是否需要对音源作出响应。
本发明所述的自然的人机语音交互方法,其基本思想是在机器的语音交互终端利用多种传感器与算法来模拟人类语音交流时利用视觉、听觉结合完成说话人识别、内容上下文理解等任务的方式,使得用户可以以与人类语音交流基本同样自然的方式与机器进行语音交互,从而增强人机语音交互体验,使得用户在人机语音交互过程中感觉更加自然。
本发明方法通常基于传感器和处理系统实现,传感器扮演人的感官器官的角色,处理系统扮演人的大脑的角色,从而模拟人类语音交流的方式。例如机器的语音交互终端的“听觉”由麦克风采集声音信号模拟,机器的语音交互终端的“视觉”由摄像头采集图像信号模拟,处理系统运行与步骤(1)至步骤(4)相应的各种算法,以控制传感器实现信号的采集和处理以实现各步骤功能,最终判断是否需要对音源作出响应。因此,本发明可以作为一个模块被应用到一切适用于人机语音交互的终端设备当中,例如作为机器的语音交互终端中安装的语音助手的一个前置增强模块,增强人机语音交互体验。当然,本发明还可以进一步包括语义理解、搜索和/或计算需要响应的具体内容,以对音源作出响应,从而作为一个完整的语音交互模块被使用。
本发明相对于常见语音交互方法的主要优势在于传感器部分引入了“视觉”信号,并将其应用到说话人即音源身份识别和说话对象识别过程中,为语义理解过滤不必要的干扰,从而能够自然精准地进入语义理解状态,增强人机语音交互体验。涉及的原理包括:
步骤(1)涉及对音源方位的判断。
如同日常生活中一样,当一个人听到可能是在跟自己讲话的声音时,通常会先判断出声音发出的方向,然后再通过眼睛去确认该方向的音源。
当使用麦克风阵列(microphonearray,一组已知排列的麦克风)时,声音到达阵列中不同麦克风的时间会有所不同,而不同方向来的声音到达不同麦克风的延迟是不同的,因此可以通过计算延迟差来大致估算音源的方向。
当环境中存在多个音源时,可以在麦克风阵列中采用指向性麦克风,指向性麦克风的收音角度较小,因此不同方向上音源到达麦克风采集到的强度会有比较明显的差别,结合频域上的聚类和回归等后处理方法可以达到区分多个音源方向的目的。
考虑语音交互的应用场景,通常对麦克风采集到的信号频率范围进行裁剪处理以限制在人声范围内,从而进一步提高稳定性。
当能够区分出环境中多个不同的音源即说话人时,则可以调用步骤(2)来进一步确认每个说话人的身份。
步骤(2)涉及音源身份的识别。
识别音源的身份包括两种途径,一种是基于“听觉”识别,看他/她的声音特质是否符合已知的某一个说话人,这方面已经有不少的算法研究,但是单单依靠“听”来判断说话人的身份,技术上目前尚不成熟,尤其在较为复杂的环境下,嗓音识别几乎不具有实用性。另一种则是基于“视觉”识别。本发明中,基于“听觉”的音源识别通常为备选方案,可以作为基于“视觉”的音源识别的补充。
通常单独依靠可见光摄像头无法区分真人和照片/视频,因此本发明中,“视觉”部分的传感器除了普通的可见光摄像头外,通常还包括一组红外摄像头,理想的情况下最好为具备深度感应的立体视觉摄像头,比如目前市场上来自英特尔的real-sense摄像头。
在系统配备了景深和红外感应的摄像头之后,可以利用大量的现有算法实现人脸的检测与识别,从而得到上述音源方位的判断中产生的各个候选人的身份信息。通常这类算法在需要识别的人数较少,比如千人级别时,都是可以离线运行的。
步骤(3)涉及说话对象的识别。
通常,只有当说话对象为机器的语音交互终端时才有必要对其作出响应。因此需要判断说话人是否在对机器的语音交互终端说话,也就是说话对象识别。
在真实环境中,当一个人无法通过内容确认是否别人在跟自己讲话时,通常会通过两种方式来进行判断,一是听对方是否提到了自己,也就是类似于现有主流系统中的热词检测;二是会看对方是否看向了自己。本发明同样借鉴了这样的两种实现方式。
本发明中当热词监听和/或视线分析算法判断说话人可能是在跟机器的语音交互终端对话时,则进入步骤(4)对收到的说话人的声音信号进行意图理解过滤,以判断是否需要对音源作出响应。
步骤(4)涉及对声音信号的意图理解过滤。
不同于直接产生最终响应的语义理解过程中的意图分类是一个多分类问题,即对多种潜在意图进行分类,该步骤的意图理解过滤是一个简单的二分类判断,即判断是否需要对音源作出响应,是一个更加简单的问题。
假如机器的语音交互终端的语音系统名字叫做“小安”,那么对于“小安这个系统非常棒!”,“最近小安的开发进展不错。”这样的句子,哪怕已经触发了热词监听实际上也不应该做出响应。而对于“今天天气怎么样?”,“去a地的路堵车么?”这类句子则应该做出响应。注意当语音信息传到这一步时,说明已经通过“视觉”或者“听觉”判断出来说话人大概率是在对机器的语音交互终端讲话了。
本发明可以通过训练一个意图分类器,使得能够区分哪类句子应该做出反应,哪类句子即使是用户看着机器的语音交互终端说也不需要做出反应。这种区别类似于一般陈述句无需响应,祈使句与问句需要响应,但是真实的机器学习模型可能无法精准对应到人类语言学的这类概念上。
关于“意图分类”问题实际上是自然语言处理算法中的一个被广泛研究的问题,目前已经有产品化的技术,比如微软的luis就可以让用户自行训练一个可以识别十种以内意图的分类器。其基本原理是提供一些带有意图标记的“语料”给神经网络模型训练,得到能够识别新语句意图的分类器。上述意图分类器的关键在于可以解决两分类问题,即是否需要响应,其训练难度较低,精度较高。
当说话人的一句话通过意图理解过滤后,即判断需要对音源作出响应,就可以进入传统系统中的语义理解与执行反馈的过程了。
进一步地,本发明所述的自然的人机语音交互方法中,在所述步骤(2)中,根据采集的图像信号,采用人脸识别算法,识别音源的身份。
进一步地,本发明所述的自然的人机语音交互方法中,在所述步骤(2)中,根据采集的图像信号,采用人脸识别算法和唇部动作分析算法,识别音源的身份。
上述方案中,当几个人靠得比较近并且都是属于被认可的说话人时,就需要通过唇部动作来确认刚刚收到的声音信号是来自于哪一个说话人。目前现有的唇部动作检测算法可以以较高的精度检测出一个人是否在说话,而不是呼吸、吃东西等其它嘴部动作。通过这一步,绝大部分情况下可以锁定每一个时刻说话人的身份。当很多人一起说话时,可以认为不属于人机语音交互场景。因此可以认为需要处理的是每个时刻只有一个说话人,或者说主要只有一个说话人的情况。
进一步地,本发明所述或上述任一自然的人机语音交互方法中,在所述步骤(2)中,还根据采集的声音信号,采用嗓音识别算法,识别音源的身份。
进一步地,本发明所述的自然的人机语音交互方法中,在所述步骤(2),只有当音源被识别为特定身份的人时,才进行下一步骤。
上述方案中,只对限定身份的人做出响应,可以视为只有当说话人通过了视觉身份识别之后,他的声音、画面信息才会进入下一步处理。
本发明的另一目的是提供一种自然的人机语音交互系统,该系统可被应用于人机语音交互,增强人机语音交互体验,使得用户在人机语音交互过程中感觉更加自然。
基于上述发明目的,本发明还提供了一种自然的人机语音交互系统,其包括:
传感器装置,其至少包括采集声音信号的麦克风阵列和采集图像信号的摄像头,所述麦克风阵列具有若干个麦克风,所述摄像头包括可见光摄像头和红外摄像头;
处理装置,其与所述传感器装置连接,以根据接受自传感器装置的声音信号和图像信号,对音源身份进行识别,对说话对象进行识别,以及判断是否需要对音源作出响应。
本发明所述的自然的人机语音交互系统中,所述处理装置可被配置为按照上述自然的人机语音交互方法的步骤(1)至步骤(4)工作,因此,该系统可被应用于人机语音交互,增强人机语音交互体验,使得用户在人机语音交互过程中感觉更加自然。相应的工作原理已在上述自然的人机语音交互方法的原理说明部分阐述,在此不再赘述。
进一步地,本发明所述的自然的人机语音交互系统中,所述处理装置包括:
身份识别模块,其对音源身份进行识别;
说话对象识别模块,其对说话对象进行识别;
语义理解与响应模块,其基于两分类的意图分类器判断是否需要对音源作出响应。
进一步地,本发明所述的自然的人机语音交互系统中,所述处理装置根据麦克风阵列中不同位置的麦克风采集的声音信号以判断音源的方位,并基于音源的方位控制摄像头转动到相应位置以采集音源所在方位的图像信号。
进一步地,本发明所述的自然的人机语音交互系统中,所述麦克风为指向性麦克风。
进一步地,本发明所述的自然的人机语音交互系统中,所述摄像头还包括具备深度感应的立体视觉摄像头。
本发明所述的自然的人机语音交互方法,其具有以下优点和有益效果:
(1)可被应用于人机语音交互,增强人机语音交互体验,使得用户在人机语音交互过程中感觉更加自然。
(2)细粒度的状态切换:传统语音助手进入识别状态和退出识别状态都需要非常明确的“信号”,对于本发明而言,实际上不存在明显的状态切换过程。本发明的状态切换可以认为是无缝的,始终保持监听,判断是否有被认可的用户在说话、是否在对机器的语音交互终端说话、是否对机器的语音交互终端发出请求,当所有判断都为肯定时,则进入理解与执行的状态。本发明的状态切换粒度可以如同普通人一样以句子为单位。
(3)利用本发明,用户可以像是在日常环境中一样与机器的语音交互终端的语音助手进行语音交互,避免生硬的用户体验,并且本发明的更加有效的说话人身份识别机制和细粒度的状态切换特性使得多人语音交互成为了可能。
本发明所述的自然的人机语音交互系统,其同样具有上述效果。
附图说明
图1为本发明所述的自然的人机语音交互方法的流程示意图。
图2为本发明所述的自然的人机语音交互系统在一种实施方式下的结构示意图。
具体实施方式
下面将结合说明书附图和具体的实施例来对本发明所述的自然的人机语音交互方法和系统进行进一步地详细说明,但是该详细说明不构成对本发明的限制。
图1显示了本发明所述的自然的人机语音交互方法的流程。如图1所示,该自然的人机语音交互方法包括步骤:
(1)信号采集:采用麦克风阵列采集音源的声音信号,根据麦克风阵列中不同位置的麦克风采集的声音信号,判断音源的方位,采用摄像头采集音源所在方位的图像信号;
(2)音源身份识别:根据采集的图像信号,识别音源的身份;
(3)说话对象识别:根据采集的图像信号和声音信号,基于热词监听和视线分析算法,识别说话对象;
(4)根据采集的声音信号,判断是否需要对音源作出响应。
在某些实施方式中,在所述步骤(2)中,根据采集的图像信号,采用人脸识别算法,识别音源的身份。
在某些实施方式中,在所述步骤(2)中,根据采集的图像信号,采用人脸识别算法和唇部动作分析算法,识别音源的身份。
在某些实施方式中,在所述步骤(2)中,还根据采集的声音信号,采用嗓音识别算法,识别音源的身份。
在某些实施方式中,在所述步骤(2),只有当音源被识别为特定身份的人时,才进行下一步骤。
图2示意了本发明所述的自然的人机语音交互系统在一种实施方式下的结构。如图2所示,该自然的人机语音交互系统包括:
传感器装置1,其包括采集声音信号的麦克风阵列11和采集图像信号的摄像头12,该麦克风阵列具有若干个指向性麦克风,该摄像头12包括可见光摄像头、红外摄像头以及具备深度感应的立体视觉摄像头,例如英特尔的real-sense摄像头。
处理装置2,其与传感器装置1连接,以根据接受自传感器装置1的声音信号和图像信号,对音源身份进行识别,对说话对象进行识别,以及判断是否需要对音源作出响应。
本实施例中,处理装置2包括:
身份识别模块21,其被配置为对音源身份进行识别。具体来说,身份识别模块21根据麦克风阵列11中不同位置的麦克风采集的声音信号以判断音源的方位,并基于音源的方位控制摄像头12转动到相应位置以采集音源所在方位的图像信号。其中,通过计算延迟差来大致估算音源的方向。当环境中存在多个音源时,结合频域上的聚类和回归等后处理方法区分多个音源方向。此外,对麦克风采集到的信号频率范围进行裁剪处理以限制在人声范围内,从而进一步提高稳定性。当区分出环境中多个不同的音源即说话人时,基于音源的方位控制摄像头12转动到相应位置以采集音源所在方位的图像信号。然后采用唇部动作分析算法锁定每一个时刻的说话人,并采用人脸识别算法实现该说话人的人脸的检测与识别,从而基于上述音源所在方位的图像信号得到上述音源方位的判断中产生的各个说话人的身份信息,只有当音源被识别为特定身份的人时,才调用说话对象识别模块22。在某些实施方式中,也可以根据采集的声音信号,采用嗓音识别算法,识别音源的身份。
说话对象识别模块22,其被配置为对说话对象进行识别。具体来说,通过热词监听和视线分析算法判断说话人是否可能是在跟机器的语音交互终端对话,若是则调用语义理解与响应模块23。
语义理解与响应模块23,其被配置为基于两分类的意图分类器判断是否需要对音源作出响应,用于意图理解过滤。具体来说,通过训练一个基于两分类的意图分类器,使得能够区分哪类句子应该做出反应,哪类句子即使是用户看着机器的语音交互终端说也不需要做出反应。
本实施例的自然的人机语音交互系统工作时:
首先通过身份识别模块21进行信号采集和音源身份识别:采用麦克风阵列11采集音源的声音信号,根据麦克风阵列11中不同位置的麦克风采集的声音信号,判断音源的方位,采用摄像头12采集音源所在方位的图像信号。根据采集的图像信号,识别音源的身份。
然后通过说话对象识别模块22进行说话对象识别:根据采集的图像信号和声音信号,基于热词监听和视线分析算法,识别说话对象。
最后通过语义理解与响应模块23根据采集的声音信号,判断是否需要对音源作出响应。
本实施例的自然的人机语音交互系统可作为机器的语音交互终端中安装的语音助手的一个前置增强模块,从而增强人机语音交互体验。当说话人的一句话通过意图理解过滤后,即判断需要对音源作出响应,就可以进入语音助手中的语义理解与执行反馈的过程了。
需要注意的是,以上列举的仅为本发明的具体实施例,显然本发明不限于以上实施例,随之有着许多的类似变化。本领域的技术人员如果从本发明公开的内容直接导出或联想到的所有变形,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!