在线教学精彩片段提取的方法与流程
本发明涉及一种数据提取方法,具体的说,是涉及一种在线教学精彩片段提取的方法。
背景技术:
在当前的在线教育行业中,一对一上课是重要的教学方式之一,为了保证教学体验,需要对上课内容进行录制,以便学生及家长课后回顾。
由于录制的课程媒体文件对存储量要求很大,而媒体文件自身包含了很多冗余信息,对存储造成浪费,同时,学生回顾课程时,也只是希望回顾重点或者精彩片段,而不是把一堂课重新再学一次,这就需要对上课的录制内容进行精彩片段的分析和提取,最终仅保存最有价值、最精彩的上课片段。
技术实现要素:
针对上述现有技术中的不足,本发明提供一种的在线教学精彩片段提取的方法。
本发明所采取的技术方案是:
一种在线教学精彩片段提取的方法,
构建语音特征库,设定精彩片段的判定标准,根据判定标准,制作语音特征库;
提取精彩片段,解析上课媒体文件,获得音频原始文件;
对音频文件预处理,剔除静音信息,获得多个音频片段;
在每个音频片段中,与该节课对应的语音片段库中的信息进行特征匹配,匹配成功,则打点记录;
根据打点记录,对每个打点记录之前的一定长度的音视频片段进行提取,形成精彩片段,将这些精彩片段进行拼接,形成最终的媒体文件。
保存在语音特征库中的语音为great、good和excellent。
制作语音特征库的方式如下:
获取语音片段方式包括:
提前录制好判定标准中各个单词的语音片段;
从先前媒体文件中提取判定标准中各个单词的语音片段;
语音片段预处理:基于音响大小,识别出静音成分,并去除静音成分;
特征信息提取:对经处理过的语音片段进行分帧;
对每帧都提取梅尔频率倒谱系数及其一阶差分,组成24维的特征向量,语音片段所有帧的特征向量组成特征向量集;
将特征向量集与特定单词的语音片段形成一一映射的关系;
将特征向量集、特征向量集对应的单词和老师的id信息存入特征信息库;
完成语音片段的特征信息库建立。
音频特征匹配步骤如下:
(1)对有效音频片段分帧,每帧长度40ms,对每帧提取梅尔频率倒谱系数及其一阶差分组成的特征向量;
(2)将首帧的特征向量与特征信息库中各个特征向量集的首个特征向量进行相关性计算,根据相关度判定匹配度,若不匹配,则进入(5);
(3)选定库中特征向量集,计算有效音频片段后续帧的特征向量;与该特征向量集对应位置的特征向量进行匹配,如遇不匹配,则进入(5),若全部匹配,则进入(4);
(4)说明该有效音频片段为精彩片段的响应,对该片段做打点记录,记录包括该音频片段的时间戳及片段id信息;
(5)若有效音频片段处理完成,则完成整个匹配过程,否则,选择下一个有效音频片段,进入(1)。
语音片段预处理包括如下步骤:
a)预置静音振幅的阈值,用tthreshold来表示,取经验值0.03;
b)根据语音的短时平稳性质,对语音片段进行分帧,每帧时长40ms,对每帧求平均振幅,计算公式如下:
c)静音帧判决:
d)对于每帧完成静音帧判决后,若为有效语音帧,则写入有效语音片段文件,获得有效的语音片段。
所述特征信息提取步骤如下:
a)根据语音的短时平稳性质,对语音片段进行分帧,每帧时长40ms,对每帧都进行离散傅里叶变换,变换公式如下:
进一步,得到能量频谱,计算公式如下:
b)将上述能量谱pi(k)通过梅尔滤波器组,梅尔滤波器组定义如下:
c)对数频谱li(m)进行dct变换,得到梅尔倒谱系数,公式如下:
同时,计算其一阶差分,公式如下:
d)梅尔倒谱系数和一阶差分系数的维数m均为12,ci,di组成每帧的特征向量fi,维数为24;
e)对每帧进行上述操作,即可提取出语音片段的特征向量集。。
本发明相对现有技术的有益效果:
本发明在线教学精彩片段提取的方法,根据所运用的行业场景,将特征库细化,能够有效提升特征匹配的准确率,同时,由于针对特定对象进行特征匹配,也极大提升了匹配效率。
附图说明
图1是本发明在线教学精彩片段提取的方法,制作老师的语音特征库流程图;
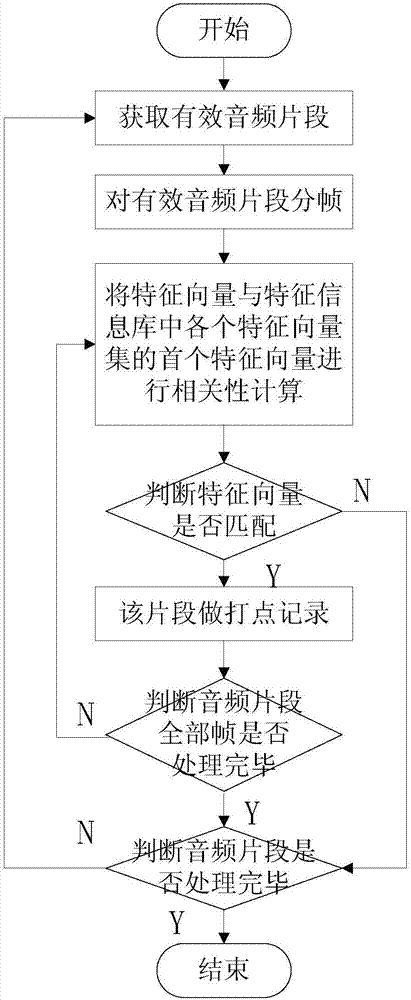
图2是本发明在线教学精彩片段提取的方法的音频片段匹配流程图。
附图中主要部件符号说明:
具体实施方式
以下参照附图及实施例对本发明进行详细的说明:
附图1-2可知,一种在线教学精彩片段提取的方法,
构建语音特征库,设定精彩片段的判定标准,根据判定标准,制作语音特征库;
提取精彩片段,解析上课媒体文件,获得音频原始文件;
对音频文件预处理,剔除静音信息,获得多个音频片段;
在每个音频片段中,与该节课对应的老师在语音片段库中的信息进行特征匹配,匹配成功,则打点记录;
根据打点记录,对每个打点记录之前的5s长度(时长可以根据需求灵活设定)的音视频片段进行提取,形成精彩片段,将这些精彩片段进行拼接,形成最终的媒体文件。
确定精彩片段的判定标准:在老师感觉学生表现较好时,会给予鼓励性的回应,因此,本发明中精彩片段的判定标准为,当老师说出如下词汇之一时,认为该时间点前,学生的表现优秀,存在一定时长的精彩片段:
(1)老师的语音中包含“great”;
(2)老师的语音中包含”good”;
(3)老师的语音中包含“excellent”。
保存在语音特征库中的语音为great、good和excellent。
制作老师的语音特征库的方式如下:
获取语音片段方式包括:
老师提前录制好判定标准中各个单词的语音片段;
从先前老师的上课媒体文件中提取判定标准中各个单词的语音片段;
语音片段预处理:基于音响大小,识别出静音成分,并去除静音成分;
特征信息提取:对经处理过的语音片段进行分帧(40ms每帧);
对每帧都提取梅尔频率倒谱系数(mel-frequencycepstralcoefficients)及其一阶差分(delta-mfccs),组成24维的特征向量,语音片段所有帧的特征向量组成特征向量集;
将特征向量集与特定单词的语音片段形成一一映射的关系;
将特征向量集、特征向量集对应的单词和老师的id信息存入特征信息库;
完成语音片段的特征信息库建立。
其他片段处理方法相同。
精彩片段提取:
解析上课媒体文件,获得音频原始文件:媒体文件可以为各种标准化格式,如mp4等,通过解码,得到音频原始文件;
音频文件中会有很多无效信息,比重最大的是静音部分或者响度很低的噪音部分,音频片段分帧,每帧长度40ms,通过对文件中各帧(40ms/帧)的声音响度分析,剔除静音或者噪音部分,从而将音频文件切分为多个独立的有效音频片段。
音频特征匹配步骤如下:
(1)对有效音频片段分帧,每帧长度40ms,对每帧提取梅尔频率倒谱系数及其一阶差分组成的特征向量;
(2)将首帧的特征向量与特征信息库中该老师的各个特征向量集的首个特征向量进行相关性计算,根据相关度判定匹配度,若不匹配,则进入(5);
(3)选定库中特征向量集,计算有效音频片段后续帧的特征向量;与该特征向量集对应位置的特征向量进行匹配,如遇不匹配,则进入(5),若全部匹配,则进入(4);
(4)说明该有效音频片段为精彩片段的响应,对该片段做打点记录,记录包括该音频片段的时间戳及片段id信息;
(5)若有效音频片段处理完成,则完成整个匹配过程,否则,选择下一个有效音频片段,进入(1)。
5、根据权利要求1所述在线教学精彩片段提取的方法,其特征在于:所述语音片段预处理包括如下步骤:
a)预置静音振幅的阈值(silentthreshold),用tthreshold来表示,取经验值0.03;
b)根据语音的短时平稳性质,对语音片段进行分帧,每帧时长40ms,对每帧求平均振幅,计算公式如下:
c)静音帧判决:
d)对于每帧完成静音帧判决后,若为有效语音帧,则写入有效语音片段文件,否则不处理;获得有效的语音片段。
6、根据权利要求1所述在线教学精彩片段提取的方法,其特征在于:所述特征信息提取步骤如下:
a)根据语音的短时平稳性质,对语音片段进行分帧,每帧时长40ms,对每帧都进行离散傅里叶变换,变换公式如下:
进一步,得到能量频谱,计算公式如下:
b)将上述能量谱pi(k)通过梅尔滤波器组,梅尔滤波器组定义如下:
c)对数频谱li(m)进行dct变换,得到梅尔倒谱系数,公式如下:
同时,计算其一阶差分,公式如下:
d)梅尔倒谱系数和一阶差分系数的维数m均为12,ci,di组成每帧的特征向量fi,维数为24;
e)对每帧进行上述操作,即可提取出语音片段的特征向量集。
本发明在线教学精彩片段提取的方法,根据所运用的行业场景,将特征库细化,能够有效提升特征匹配的准确率,同时,由于针对特定对象进行特征匹配,也极大提升了匹配效率。
以上所述,仅是本发明的较佳实施例而已,并非对本发明的结构作任何形式上的限制。凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均属于本发明的技术方案范围内。
- 还没有人留言评论。精彩留言会获得点赞!